视觉语言模型vlm-2025:更好、更快、更强
视觉语言模型 2025:更好、更快、更强
动机
视觉语言模型(VLMs)已成为当今人工智能领域的热门话题。自2024年4月的前一篇博客文章以来,该领域发生了巨大变化。模型变得更小但更强大,出现了新的架构和能力(推理、代理、长视频理解等)。与此同时,诸如多模态检索增强生成(RAG)和多模态代理等全新范式也已形成。
本笔记将回顾并解析过去一年视觉语言模型领域发生的一切变化,包括关键变化、新兴趋势和重要发展。
目录
新模型趋势
1. 任意到任意模型(Any-to-any models)
任意到任意模型,顾名思义,是能够接收任何模态并输出任何模态(图像、文本、音频)的模型。它们通过对齐模态来实现这一点,其中一个模态的输入可以转换为另一个模态。
关键特点:
- 多个编码器(每个模态一个)
- 融合嵌入以创建共享表示空间
- 解码器使用共享潜在空间作为输入
重要模型:
- Chameleon(Meta):最早的尝试
- Lumina-mGPT(Alpha-VLLM):在Chameleon基础上增加图像生成
- Qwen 2.5 Omni:采用"思考者-对话者"架构
- MiniCPM-o 2.6:8B参数多模态模型
- Janus-Pro-7B(DeepSeek AI):解耦视觉编码架构

2. 推理模型(Reasoning Models)
推理模型能够解决复杂问题。直到2025年,只有一个开源多模态推理模型:Qwen的QVQ-72B-preview。
新增模型:
- Kimi-VL-A3B-Thinking(Moonshot AI):
- MoonViT(SigLIP-so-400M)作为图像编码器
- 混合专家(MoE)解码器,16B总参数,2.8B活跃参数
- 长链式思维微调和强化学习对齐
- 支持长视频、PDF、截图等
3. 小而强大的模型(Smol yet Capable Models)
小型视觉语言模型通常指参数少于2B且可在消费级GPU上运行的模型。
代表性模型:
- SmolVLM系列:256M、500M、2.2B参数
- SmolVLM2:在这些尺寸中实现视频理解
- gemma3-4b-it(Google DeepMind):
- 128k令牌上下文窗口
- 支持140+种语言
- Qwen2.5-VL-3B-Instruct:
- 支持本地化(目标检测和指向)
- 文档理解和代理任务
- 32k令牌上下文长度
使用示例:
# MLX使用SmolVLM-500M-Instruct
python3 -m mlx_vlm.generate --model HuggingfaceTB/SmolVLM-500M-Instruct --max-tokens 400 --temp 0.0 --image https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/vlm_example.jpg --prompt "What is in this image?"
# llama.cpp使用gemma-3-4b-it
llama-mtmd-cli -hf ggml-org/gemma-3-4b-it-GGUF
4. 混合专家作为解码器(Mixture-of-Experts as Decoders)
混合专家(MoE)模型通过动态选择和激活最相关的子模型(称为"专家")来处理给定输入数据段,提供了密集架构的替代方案。
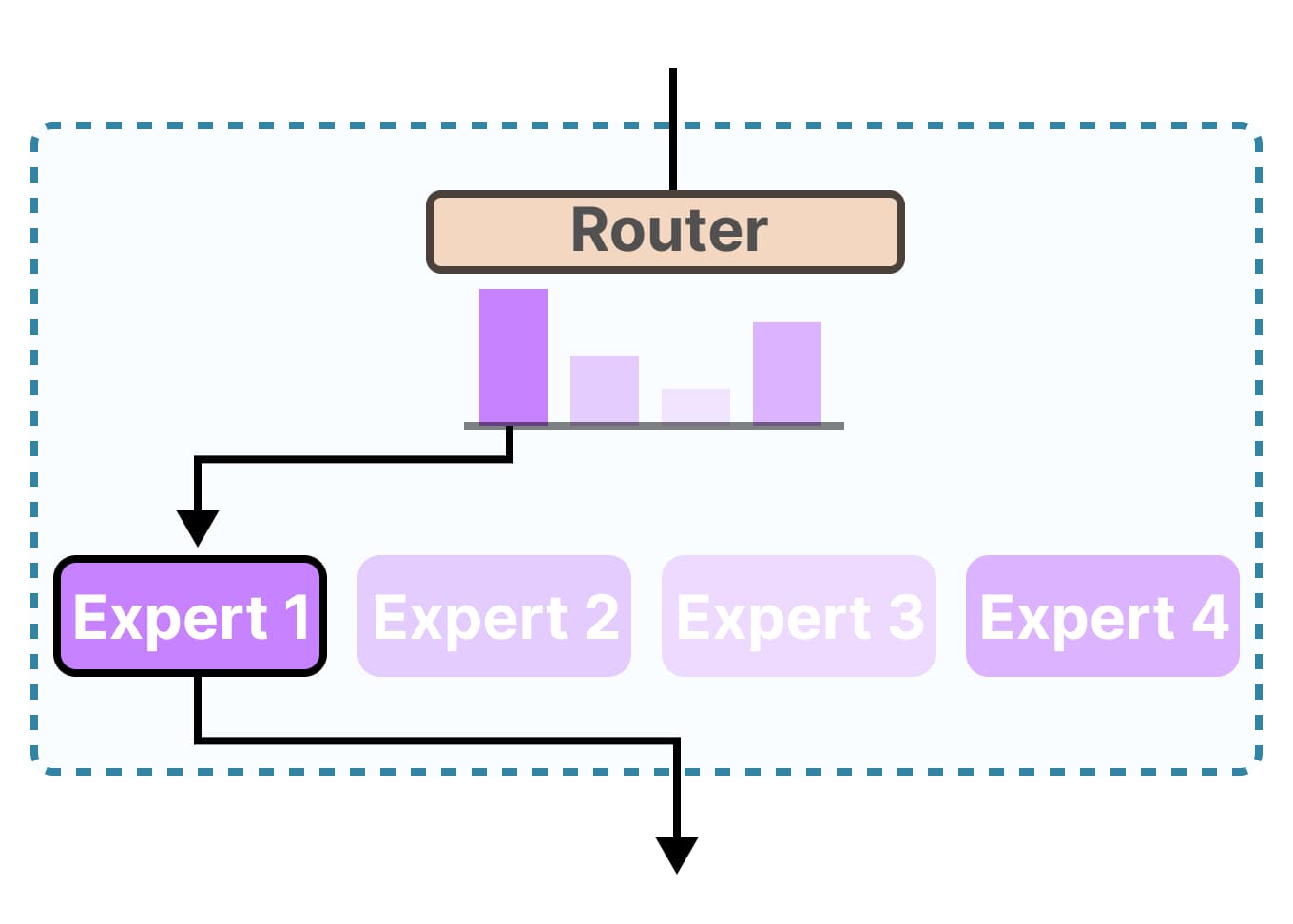
优势:
- 推理速度比类似参数的密集模型更快
- 训练时收敛更快
- 更好的计算利用率
缺点:
- 需要更多内存成本(整个模型都在GPU上)
代表性模型:
- Kimi-VL:最先进的开源推理模型
- MoE-LLaVA:专注于效率和幻觉减少
- DeepSeek-VL2:广泛的多模态能力
- Llama 4:具有视觉能力的MoE

5. 视觉-语言-动作模型(Vision-Language-Action Models)
VLA扩展了视觉语言模型,通过添加动作和状态令牌来与物理环境交互和控制。
重要模型:
- π0和π0-FAST(Physical Intelligence):
- 在7个机器人平台和68个独特任务上训练
- 在复杂现实世界活动中表现出色
- GR00T N1(NVIDIA):
- 用于通用人形机器人的开放VLA基础模型
- 结合智能推理和实时运动控制

专业化能力
1. 目标检测、分割和计数
VLM能够通过结构化文本输出本地化令牌来完成传统计算机视觉任务。
重要模型:
- PaliGemma:首个尝试解决这些任务的模型
- PaliGemma 2:升级版本,性能更好
- Molmo(Allen AI):可以用点指向实例并计数对象
- Qwen2.5-VL:可以检测、指向和计数对象,包括UI元素
2. 多模态安全模型
用于过滤输入和输出以防止越狱和有害输出。
重要模型:
- ShieldGemma 2(Google):首个开放多模态安全模型
- Llama Guard 4(Meta):密集多模态和多语言安全模型
3. 多模态RAG:检索器和重排器
多模态RAG处理复杂文档(通常为PDF格式)的三个步骤:
- 将文档完全解析为文本
- 将纯文本和查询传递给检索器和重排器
- 将相关上下文和查询传递给LLM

两种主要架构:
- 文档截图嵌入(DSE, MCDSE):每个查询返回单个向量
- ColBERT类模型(ColPali, ColQwen2, ColSmolVLM):每个令牌返回多个向量
多模态代理
视觉语言模型解锁了许多代理工作流程,从文档对话到计算机使用。
重要模型:
- UI-TARS-1.5(ByteDance):在浏览器、计算机和手机使用方面表现出色
- MAGMA-8B:UI导航和物理世界交互的基础模型
- Qwen2.5-VL(32B变体):在代理任务上进一步训练
smolagents库:
实现ReAct框架的轻量级代理库,支持视觉语言功能。
# 文档描述示例
agent = CodeAgent(tools=[], model=model)
agent.run("Describe these documents:", images=[document_1, document_2, document_3])
# 网络代理示例
webagent "go to xyz.com/men, get to sale section, click the first clothing item you see. Get the product details, and the price, return them. note that I'm shopping from France"
视频语言模型
大多数视觉语言模型现在都可以处理视频,因为视频可以表示为帧序列。
重要模型:
- LongVU(Meta):使用DINOv2下采样视频帧
- Qwen2.5VL:处理长上下文并适应动态FPS速率
- Gemma 3:可以接受与时间戳交错的视频帧
新的对齐技术
偏好优化是语言模型的替代微调方法,也可以扩展到视觉语言模型。
示例配置:
from trl import DPOConfig, DPOTrainer
training_args = DPOConfig(
output_dir="smolvlm-instruct-trl-dpo-rlaif-v",
bf16=True,
gradient_checkpointing=True,
per_device_train_batch_size=1,
num_train_epochs=5,
)
trainer = DPOTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
)
新基准测试
MMT-Bench
设计用于评估VLM在需要专家知识、精确视觉识别、本地化、推理和规划的各种多模态任务中的表现。
- 31,325个多选视觉问题
- 32个不同的元任务,162个子任务
MMMU-Pro
原始MMMU基准的改进版本:
- 仅视觉输入设置
- 候选选项从4个增加到10个
- 包含真实世界模拟
模型推荐
| 模型名称 | 尺寸 | 推荐理由 |
|---|---|---|
| Qwen2.5-VL | 3B到72B | 具有代理能力、数学等的多功能模型 |
| RolmOCR | 7B | 高性能OCR模型 |
| Kimi-VL-Thinking | 16B MoE,3B活跃参数 | 最佳推理模型 |
| SmolVLM2 | 256M、500M、2.2B | 最小的视频语言模型 |
| Llama 4 Scout & Maverick | 109B/400B MoE,17B活跃参数 | 超长上下文 |
| Molmo | 1B、7B、72B和1B活跃参数的MoE | 具有本地化能力的完全开放模型 |
有用资源
深入博客文章
- 多模态安全:Llama Guard 4博客
- VLM中的DPO:使用TRL进行视觉语言模型的偏好优化
- 具有VLM支持的Smolagents:我们刚刚为smolagents提供了视觉能力
- 视觉代理课程部分:使用smolagents的视觉代理
- Gemma 3模型发布:欢迎Gemma 3
- PaliGemma 2模型发布:欢迎PaliGemma 2
- 多模态检索:ColPali:使用视觉语言模型进行高效文档检索
- 视频语言建模:SmolVLM2:为每台设备带来视频理解
GitHub资源
- nanoVLM:训练/微调小型VLM的最简单、最快的存储库
总结
2025年的视觉语言模型展现出了惊人的发展速度和多样性。从小型高效的模型到强大的推理系统,从多模态代理到视频理解,这个领域正在快速演进。未来我们可以期待看到更多创新的架构和应用场景的出现。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号