【多模态学习】多模态大语言模型(MM-LLMs)的研究相关调研
多模态大语言模型的总结
结构与原理
结构示意图

多模态输入 → 特征提取与对齐 → 语义理解与推理 → 多模态输出生成
MLLM架构组件
| 模型组件 | 作用及介绍 |
|---|---|
| 模态编码器(Modality Encoder) | 将不同模态的输入(如图像、音频、视频)编码为特征表示。常用的视觉编码器包括CLIP ViT、EVA-CLIP等 |
| 输入投影器(Input Projector) | 将模态编码器的特征映射到LLM可理解的表示空间,实现方式包括线性投影、MLP、Q-Former等 |
| LLM(LLM Backbone) | 处理来自各种模态的表示,进行语义理解、推理和决策,产生文本输出和信号标记 |
| 输出投影器(Output Projector) | 将LLM主干中的信号标记表示映射为模态生成器可理解的特征 |
| 模态生成器(Modality generator) | 产生不同模态的输出,如图像合成使用Stable Diffusion,视频合成使用Zeroscope等 |
训练流程
| 训练流程 | |
|---|---|
| 多模态预训练 (MM PT) | 利用X-Text数据集(如图像-文本对、视频-文本对)训练输入和输出投影器,实现各种模态之间的对齐 |
| 多模态指令调优 (MM IT) | 包括监督微调(SFT)和人类反馈强化学习(RLHF),使模型能够遵循指令并与人类意图对齐 |
训练特点
- 模态编码器、LLM主干和模态生成器通常保持冻结状态
- 主要优化输入和输出投影器,可训练参数比例相对较小(通常约为2%)
- 采用参数高效微调方法如前缀调优、适配器和LoRA,可训练参数甚至不到LLM参数总数的0.1%
进展
主要发展趋势
- 从专注于MM理解逐渐发展为特定模态的生成,并进一步演变为任意到任意模态的转换
- 从MM PT到SFT再到RLHF,训练流程不断完善,力求更好地符合人类意图,增强模型的对话交互能力
- 采用多样化的模态扩展,从视觉扩展到音频、视频等多种模态
- 结合更高质量的训练数据集,提升模型性能
- 采用更高效的模型架构,从复杂的Q-Former和P-Former输入投影器模块过渡到更简单但有效的线性投影器
代表性MLLM模型
| 模型 | 年份 | 主要特点 | LLM主干 | 视觉编码器 |
|---|---|---|---|---|
| LLaVA | 2023 | 视觉指令调优 | Vicuna | CLIP ViT-L |
| BLIP-2 | 2023 | 视觉语言预训练 | Flan-T5/OPT | ViT |
| MiniGPT-4 | 2023 | 视觉语言对齐 | Vicuna | EVA-CLIP |
| InstructBLIP | 2023 | 指令调优 | Flan-T5/Vicuna | ViT |
| LLaVA-1.5 | 2023 | 改进视觉指令调优 | Vicuna-v1.5 | CLIP ViT-L |
| Qwen-VL | 2023 | 多语言支持 | Qwen | ViT |
| VILA | 2024 | 简化架构 | LLaMA-2 | SigLIP ViT |
| Gemini | 2023 | 原生多模态 | 专有 | 专有 |
| GPT-4V | 2023 | 高级视觉理解 | 专有 | 专有 |
| Claude 3 | 2024 | 高级视觉理解 | 专有 | 专有 |
| Janus | 2024 | 解耦视觉编码 | 专有 | 专有 |
代表性模型亮点
LLaVA
LLaVA是一个多模态模型,结合了开源LLM Vicuna与视觉编码器,用于图像和语言处理。它整合了视觉数据和语言理解,创建基于视觉输入的丰富、交互式响应
Janus
Janus是一种新型的自回归框架,统一了多模态理解和生成。它通过将视觉编码解耦为独立路径,同时仍使用单一、统一的transformer架构进行处理
VILA
VILA采用了更简化的架构,使用线性投影器替代复杂的Q-Former,在保持性能的同时提高了效率
Gemini
Gemini是Google的原生多模态模型,从设计之初就考虑了多模态融合,而不是在现有LLM基础上添加多模态能力
挑战与缺陷
视觉处理缺陷
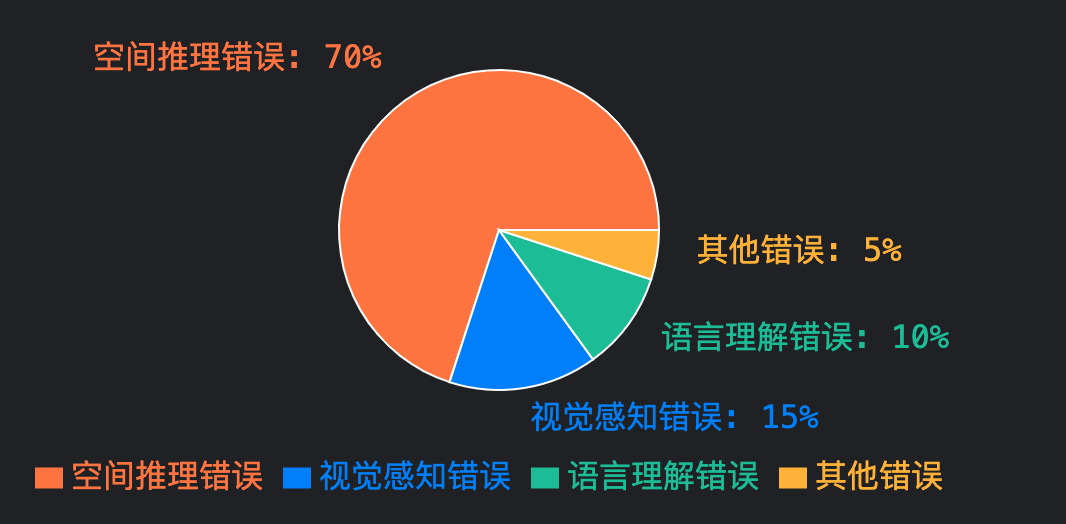
研究发现多模态大语言模型在视觉处理方面存在普遍性缺陷,特别是在基于CLIP的视觉编码器方面。即使增加CLIP的模型规模、数据规模、图片分辨率等,都无法有本质上的提升1
主要视觉缺陷
- 基础视觉问题上的准确率低,甚至不如随机猜测
- 在物体计数、相对距离、相对方向等任务上表现较差
- CLIP特征在某些视觉模式上存在固有缺陷
- 增大CLIP模型规模、数据规模、图片分辨率等无法本质提升性能
- CLIP特征的表现与集成了CLIP的MLLM表现高度相关
解决方案探索
研究者提出了特征混合(Mixture of Feature,MoF)方法,在MLLM中引入其他视觉特征(如DINOv2)来弥补CLIP的缺陷。实验表明,交织的特征混合方法在不牺牲指令跟随能力的情况下,能够显著提升MMVP基准上的性能
空间智能挑战
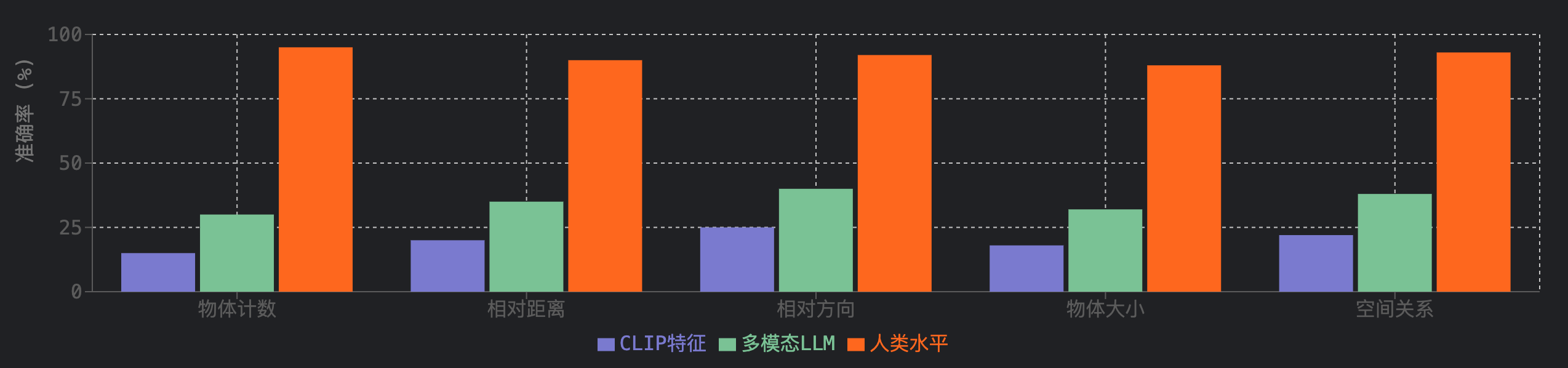
研究表明,多模态大语言模型在视觉-空间智能方面表现出竞争力,但仍低于人类水平。空间推理能力是MLLMs提升基准性能的主要瓶颈。
视觉-空间智能挑战
- 自我中心-他人中心视角转换能力不足
- 关系推理能力有限
- 空间距离估计准确度随物体距离增加而显著下降
- 传统的语言推理技术(如chain-of-thought)未能提升空间推理能力
- 视觉-空间工作记忆能力有限
VSI-Bench基准测试
VSI-Bench是一个新颖的视频驱动视觉-空间智能基准,包含超过5000个问答对,涵盖三类共八种任务:[3]
- 配置类任务:物体计数、相对距离、相对方向和路径规划
- 测量估算类任务:物体大小、房间大小和绝对距离的估算
- 时空类任务:出现顺序测试等
改进方向
研究表明,在问答过程中明确生成认知地图能够显著增强MLLMs对空间距离的处理能力。未来的改进方向包括:[3]
- 任务特定的微调
- 针对空间推理开发自监督学习目标
- 为MLLMs设计适配视觉-空间的提示技术
Grounding能力挑战
多模态大语言模型在需要高级理解和推理的视觉语言任务中表现出色,但定位能力仍然不足,尤其是与目标检测模型对比。
Grounding能力现状
- 虽然在RefCOCO等数据集上进行了训练,但这些任务中一个表达式只对应一个框,远远无法解决常规的目标检测任务
- 缺乏多目标检测能力,在检测所有目标时会有很多漏检、错检
- LLM基于自回归机制,在生成每个token时都是基于之前生成的所有token,这与密集目标检测任务需要同时处理图像中的多个目标的要求不匹配
- 输出结构不匹配,目标检测任务的输出通常是一个密集的网格或一组边界框,而LLM的自回归生成机制更适合生成序列化的输出
解决方案探索
端到端方法
LLM直接输出bbox,如LLaVA、Qwen-VL、Shikra等,但存在多目标检测能力不足和对LLM原本对话能力的破坏问题[6]
外置专家模型
如LLaVA-Grounding,在LLaVA基础上增加视觉交互模块和Grounding model,规避了端到端方法面临的问题,但引入了额外的时延[8]
特殊Tokenize方法
如Groma,将Ground能力放在Tokenize部分,解耦localization和recognition任务,在输入端先用检测头解码出ROI,再将这些Region和原始图像特征一起输入到Region Encoder[6]
视觉专家方法
如Mono-InternVL,在预训练的LLM中嵌入专门服务于视觉建模的视觉专家,通过MoE的方式实现稀疏化的建模[7]
未来发展方向
未来的发展趋势是"大一统",原生多模态和自回归统一一切任务。需要解决的关键问题包括:
- 如何基于自回归生成的机制,实现低开销的密集目标检测能力
- 解决定位任务训练带来的LLM灾难性遗忘问题
- 提升MLLM的细粒度空间感知能力,为OCR、自动驾驶等任务奠定基础
未来方向
未来发展方向
| 方向 | |
|---|---|
| 更通用和智能的模型 | 扩展模态、多样化LLMs、提高MM IT数据集质量和加强MM生成能力,从多种模态更大规模数据中学习知识 |
| 体现智能 | 体现智能旨在通过有效理解环境、识别相关对象、评估它们之间的空间关系并制定全面的任务计划,复制类似人类的感知和与周围环境的交互 |
| 更具挑战性的基准测试 | 构建更具挑战性、更大规模的基准测试,包括额外的模态和统一的评估标准 |
| 持续学习 | 由于大规模训练的巨大成本,MM-LLMs不适合频繁重新训练。需要持续学习来使模型能够灵活地、持续地利用新出现的数据,同时避免重新训练MM-LLMs的巨额成本 |
| 移动/轻量级部署 | 在资源受限的平台(如低功耗移动设备和IoT设备)上部署MM-LLMs,实现最佳性能的同时,轻量级实现至关重要 |
| 减少幻觉 | 幻觉涉及在没有视觉线索的情况下生成对不存在对象的文本描述,这在多个类别中表现出来,如判断错误和描述不准确 |
创新架构与方法
| 架构与方法 | 介绍 | 优势 |
|---|---|---|
| 特征混合(MoF) | 在MLLM中引入其他视觉特征(如DINOv2)来弥补CLIP的缺陷。交织的特征混合方法在不牺牲指令跟随能力的情况下,能够显著提升MMVP基准上的性能 | 优势: 不牺牲指令跟随能力的情况下提升视觉处理能力 |
| 认知地图生成 | 在问答过程中明确生成认知地图能够显著增强MLLMs对空间距离的处理能力,帮助模型更好地理解和表达空间关系 | 优势: 增强空间距离推理能力,提高视觉-空间智能 |
| 视觉编码解耦 | Janus通过将视觉编码解耦为独立路径,同时仍使用单一、统一的transformer架构进行处理,缓解了视觉编码器在理解和生成方面的角色冲突 | 优势: 增强框架灵活性,提高多模态理解和生成能力 |
| 视觉专家嵌入 | Mono-InternVL在预训练的LLM中嵌入专门服务于视觉建模的视觉专家,通过MoE的方式实现稀疏化的建模,仅优化视觉参数空间进行视觉预训练 | 优势: 保留语言基座的预训练知识,同时增强视觉处理能力 |
未来架构趋势
未来的MM-LLM架构趋势将朝着以下几个方向发展:
- 原生多模态架构,从设计之初就考虑多模态融合
- 更高效的模型架构,简化投影器设计,提高训练和推理效率
- 专家混合系统,针对不同模态和任务使用专门的子网络
- 统一的多模态表示空间,实现更好的跨模态对齐和转换
- 自适应架构,能够根据输入动态调整处理路径和资源分配
参考文献
-
MM-LLMs: Recent Advances in MultiModal Large Language Models
本文综述了多模态大型语言模型(MM-LLMs)的最新进展,这些模型通过cost-effective的训练策略,增强了现成的大型语言模型(LLMs)以支持多模态输入或输出。这些模型不仅保留了LLMs固有的推理和决策能力,还增强了多种多模态任务的能力。
Date: 2024 -
Eyes wide shut? exploring the visual shortcomings of multimodal llms
该研究发现多模态大语言模型在视觉处理方面存在普遍性缺陷,特别是在基于CLIP的视觉编码器方面。研究表明,即使增加CLIP的模型规模,数据规模,图片分辨率等,都无法有本质上的提升。
Date: 2024
-
Thinking in Space: How Multimodal Large Language Models See, Remember, and Recall Spaces
该研究探索了多模态大语言模型如何感知、记忆和回忆空间,提出了一个新颖的视频驱动视觉-空间智能基准(VSI-Bench),包含超过5000个问答对。研究发现,MLLMs表现出竞争力的——但仍低于人类水平的——视觉-空间智能。
Date: 2024
-
Janus: Decoupling visual encoding for unified multimodal understanding and generation
Janus是一种新型的自回归框架,统一了多模态理解和生成。它通过将视觉编码解耦为独立路径,同时仍使用单一、统一的transformer架构进行处理。这种解耦不仅缓解了视觉编码器在理解和生成方面的角色冲突,还增强了框架的灵活性。
Date: 2024
-
LLaVA: Large Language and Vision Assistant
LLaVA是一个多模态模型,结合了开源LLM Vicuna与视觉编码器,用于图像和语言处理。它整合了视觉数据和语言理解,创建基于视觉输入的丰富、交互式响应。
Date: 2023
-
Groma: Localized Visual Tokenization for Grounding Multimodal Large Language Models
Groma采用了特别的做法,将Ground能力放在了Tokenize部分,解耦了localization和recognition任务。具体地,在输入端先用检测头解码出若干ROI(Region Proposer),再将这些Region和原始图像的金字塔特征一起输入到Region Encoder,输出预设的特殊token,每个token代指图像中的一个位置,并且和一个Region相关联。
Date: 2024
-
Mono-InternVL是一种原生多模态模型,在预训练的LLM中嵌入了专门服务于视觉建模的视觉专家,通过MoE的方式实现稀疏化的建模。基于此,作者通过仅优化视觉参数空间来进行视觉预训练,同时保留了语言基座的预训练知识。
Date: 2024
-
LLaVA-Grounding: Grounded Visual Chat with Large Multimodal Models
LLaVA-Grounding在LLaVA的基础上,输入端增加了视觉交互模块,用于处理点、框、文本等视觉提示;输出端增加了Grounding model(OpenSeed),输入为LLM输出的Grounding token以及原始图像。在训练时,特殊token X_g同样参与自回归损失函数计算。
Date: 2023

 浙公网安备 33010602011771号
浙公网安备 33010602011771号