clip-retrieval检索本地数据集
clip-retrieval检索本地数据集
from clip_retrieval.clip_client import ClipClient, Modality
from tqdm import tqdm
import urllib.request
import os
import requests
import socket
client = ClipClient(url="https://knn.laion.ai/knn-service", indice_name="laion5B-L-14")
# Query by text
results = client.query(text="an image of a garbage can")
# results = client.query(text="an image of a fire")
print("search len:", len(results))
# results = client.query(text="an image of a cat")
# print("search len:", len(results))
# Query by image
# results = client.query(image="cat.jpg")
# print("search len:", len(results))
# save_path = "./search_result/"
save_path = "/data/home/linxu/PycharmProjects/clip-retrieval/data_result/"
for i in tqdm(range(0, len(results))):
caption = results[i]['caption']
url = results[i]['url']
id = results[i]['id']
similarity = results[i]['similarity']
parsed_url = urllib.parse.urlparse(url)
# print("caption:", caption, "url:", url, "id:", id, "similarity:", similarity)
# file_name = save_path + url.strip('/').split('.')[0] + '.jpg'
file_name = save_path + parsed_url.path.strip('/').split('.')[0] + '.jpg'
# print("parsed_url:", parsed_url, "file_name:", file_name)
print("file_name:", file_name, "url:", url)
if os.path.exists(save_path) == False:
os.makedirs(save_path)
try:
# 将图片数据写入文件
# print("file_name:", file_name, "url:", url)
#设置超时时间
socket.setdefaulttimeout(10)
try:
urllib.request.urlretrieve(url,file_name)
#如果超时
except urllib.request.urlretrieve.timeout:
count = 1
while count <= 5:
try:
urllib.request.urlretrieve(url,file_name)
break
except socket.timeout:
err_info = 'Reloading for %d time'%count if count == 1 else 'Reloading for %d times'%count
print(err_info)
count += 1
if count > 5:
print("download job failed!")
except:
print("error url:", url)

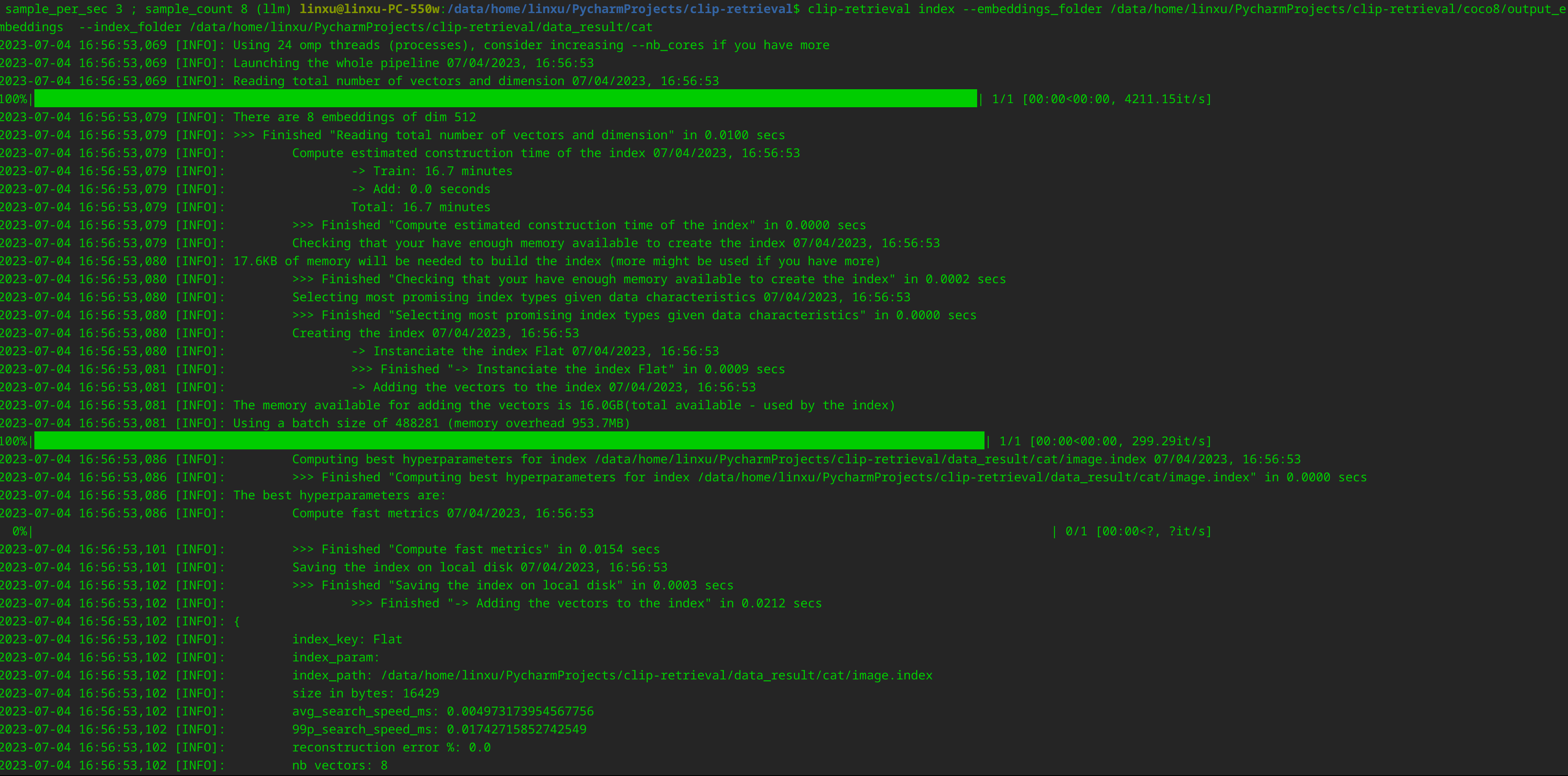

Talk is cheap. Show me the code

 浙公网安备 33010602011771号
浙公网安备 33010602011771号