在MBP上运行推理LLaMA-7B&13B模型
在MBP上运行推理LLaMA-7B模型
build this repo
# build this repo
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
obtain the original LLaMA model weights and place them in ./models
# obtain the original LLaMA model weights and place them in ./models
ls ./models
65B 30B 13B 7B tokenizer_checklist.chk tokenizer.model

install Python dependencies
# install Python dependencies
python3 -m pip install torch numpy sentencepiece
convert the 7B model to ggml FP16 format
# convert the 7B model to ggml FP16 format
python3 convert-pth-to-ggml.py models/7B/ 1
# quantize the model to 4-bits
./quantize.sh 7B
quantize the 7B model to 4-bits

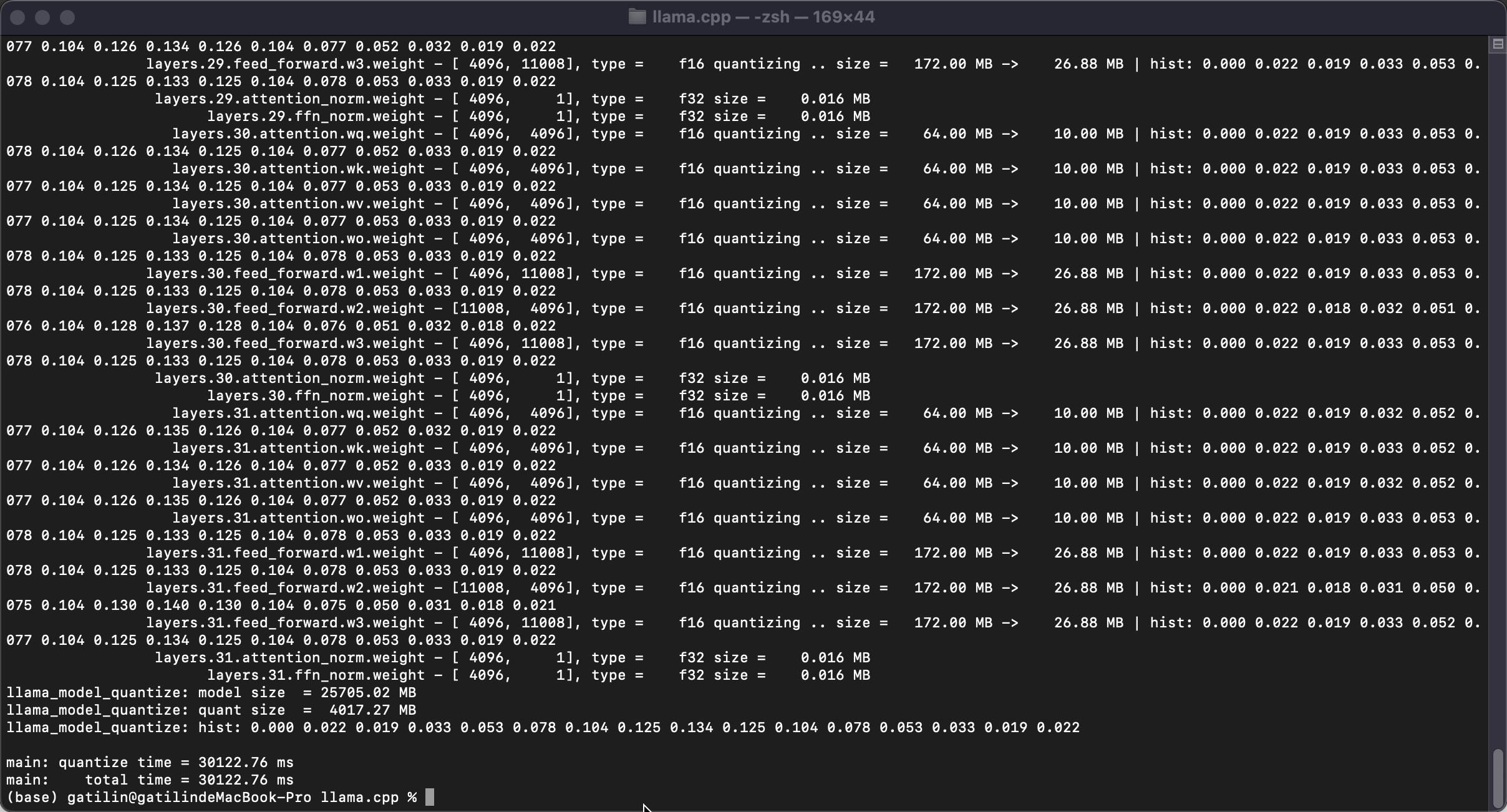

量化完之后,模型从15G降低为4G。
convert the 13B model to ggml FP16 format
# convert the 13B model to ggml FP16 format
python3 convert-pth-to-ggml.py models/13B/ 1

quantize the 13B model to 4-bits
# quantize the model to 4-bits
./quantize.sh 13B

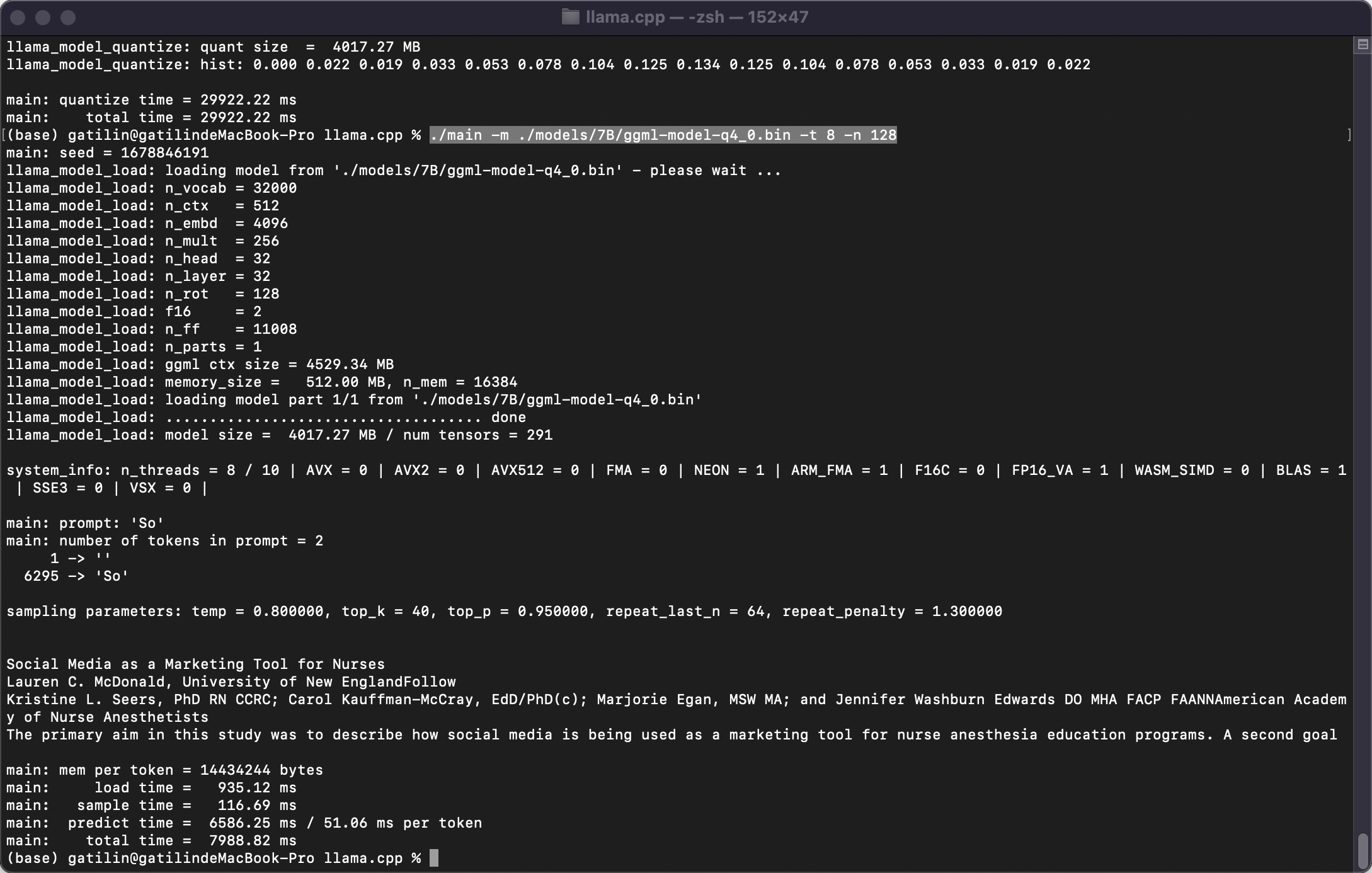
run the inference
# run the inference
./main -m ./models/7B/ggml-model-q4_0.bin -t 8 -n 128
互动模式
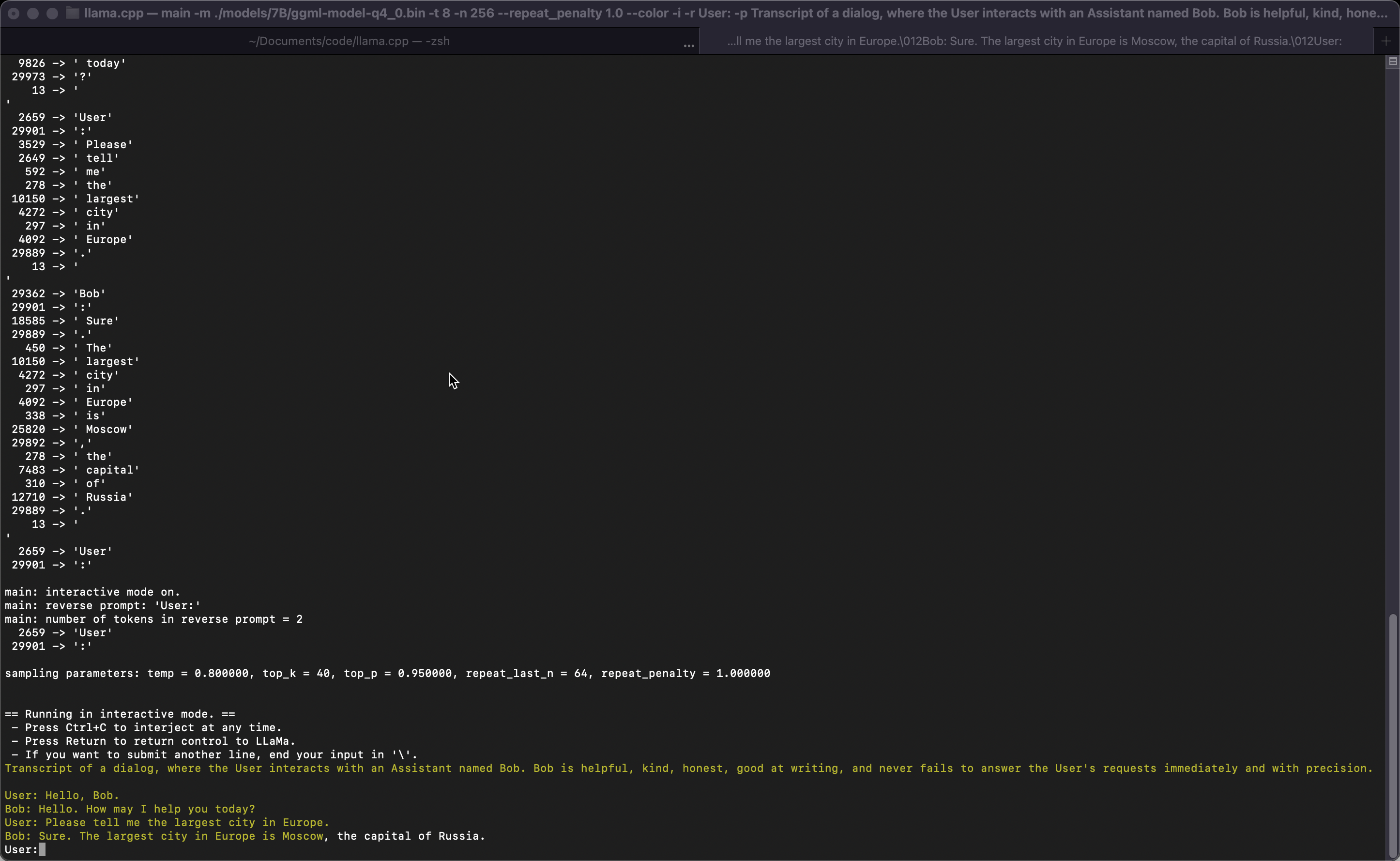
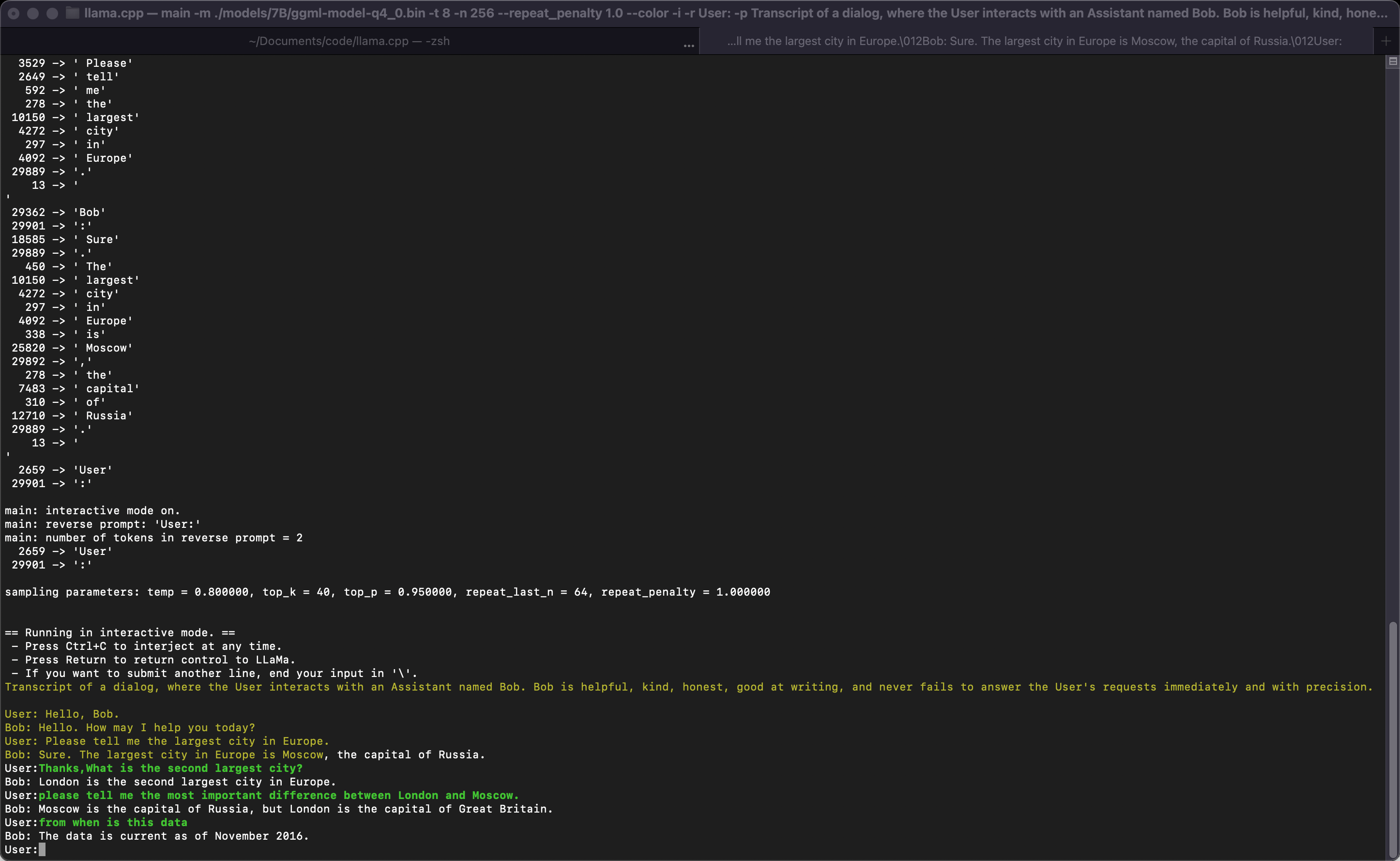
如果您想要更像ChatGPT的体验,您可以通过传递-i作为参数在交互模式下运行。在此模式下,您始终可以通过按Ctrl+C来中断生成,并输入一行或多行文本,这些文本将被转换为令牌并附加到当前上下文中。您还可以使用参数-r "reverse prompt string"指定反向提示。每当在生成中遇到反向提示字符串的确切令牌时,这将导致用户输入被提示。一个典型的用途是使用提示,使LLaMa模拟多个用户之间的聊天,比如Alice和Bob,并通过-r "Alice:"
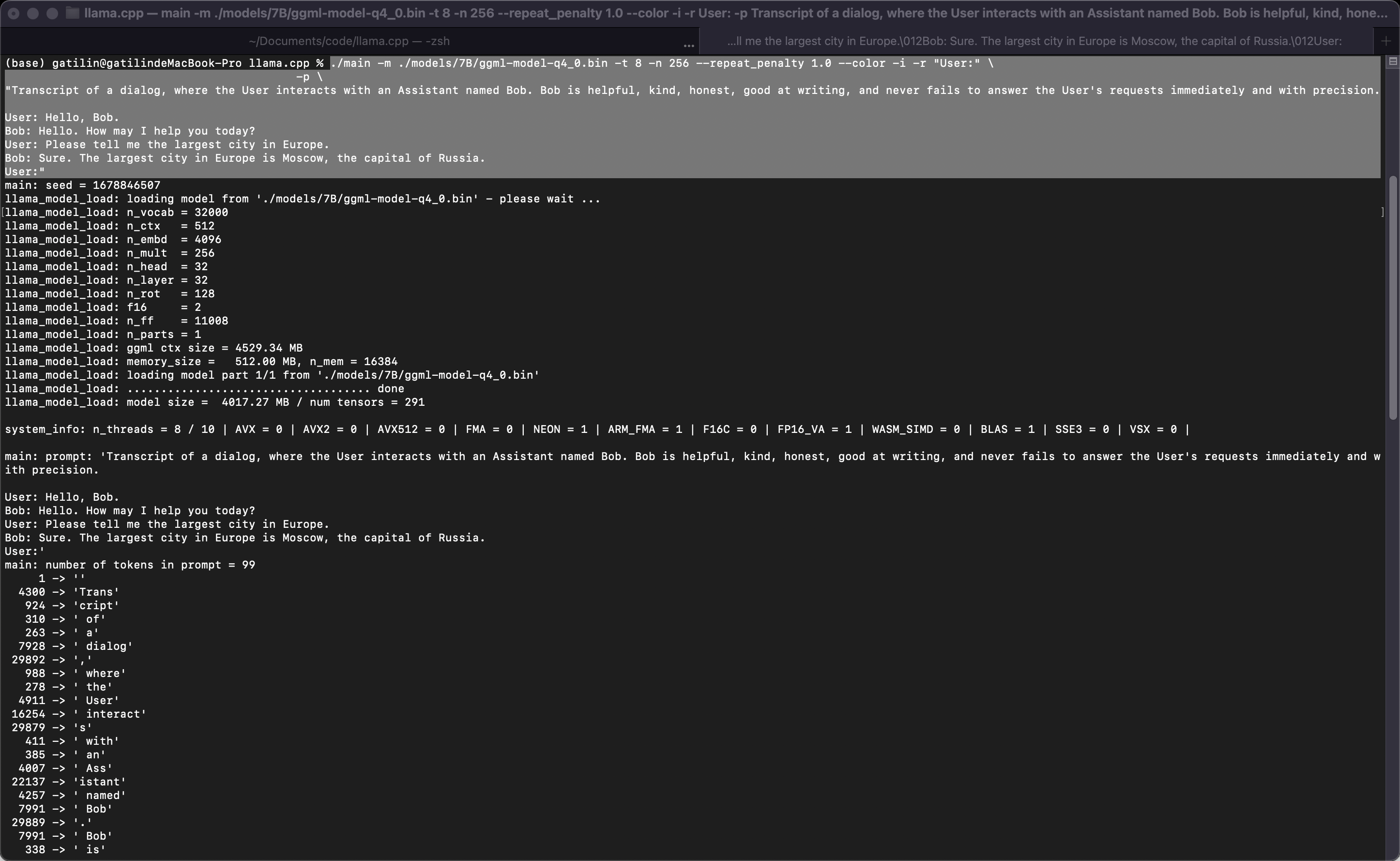
这是一个用命令调用的交互示例:
./main -m ./models/7B/ggml-model-q4_0.bin -t 8 -n 256 --repeat_penalty 1.0 --color -i -r "User:" \
-p \
"Transcript of a dialog, where the User interacts with an Assistant named Bob. Bob is helpful, kind, honest, good at writing, and never fails to answer the User's requests immediately and with precision.
User: Hello, Bob.
Bob: Hello. How may I help you today?
User: Please tell me the largest city in Europe.
Bob: Sure. The largest city in Europe is Moscow, the capital of Russia.
User:"
Talk is cheap. Show me the code

 浙公网安备 33010602011771号
浙公网安备 33010602011771号