三维计算机视觉 —— 中层次视觉 —— RCNN Family
RCNN是从图像中检测物体位置的方法,严格来讲不属于三维计算机视觉。但是这种方法却又非常非常重要,对三维物体的检测非常有启发,所以在这里做个总结。
1、RCNN - the original idea
—— <Rich feature hierarchies for accurate object detection and semantic segmentation>
这篇文章提出了用CNN网络来对物体进行检测的思路。
Q:
a. CNN网络中存在卷积层和池化层,每次池化都会弱化物体的位置信息,强化物体的特征信息,所以CNN网络最终会告诉我们是什么,而不是在哪儿
b. 要使用CNN网络来检测,直觉上我们可以训练一个识别某物体的网络,来对小方块进行分类。但是这需要大量的训练集,可能对于待检测物体,我们没有收集大量训练集的机会
c. CNN网络的图像输入层具有固定的维度,任意大小的小方块是无法直接输入到CNN网络里的
A:
a. 文章提出了可以在已经训练好的网络上利用小规模的训练集进行优化,也能达到很好的效果。
b.通过 selective search来确定可能含有物体的小方块
c.将消方块进行拉伸(warp),送入CNN进行分类,最终实现检测
细节:
1、使用了ILSVRC 2012对网络进行预训练,步长0.01
2、精训练使用的步长是0.001
3、mini-batch size = 128, 其中背景96,带东西的32。有意的bias,让网络更大概率判为背景
4、loss function 中,IoU超过50%判为1,否则为0
5、使用svm对物体类别进行判断
6、对box进行线性回归,获得更高的精度(后面还会提到)
2、SPPNet - 结合金字塔
—— <Spatial pyramid pooling in deep convolutional networks for visual recognition>
在第一步使用rcnn中,检测需要将图片拉伸成特定的大小,便于输入网络。这显然很不合理,很多东西拉伸以后就完全变形了,这会降低检测的精度。所以需要一种不拉伸方块的方法,来对物体进行检测。
Q:
a.拉伸图像会带来识别精度的下降,在r-cnn中尤其明显
A:
a.金字塔池化:将任意维度的图片池化成同一维度。例如,图片为256*256,金字塔接受的就是maxpool2dlayer(16,'stride',16),如果图片为128*128,金字塔接受的就是maxpool2dlayer(8,'stride',8)
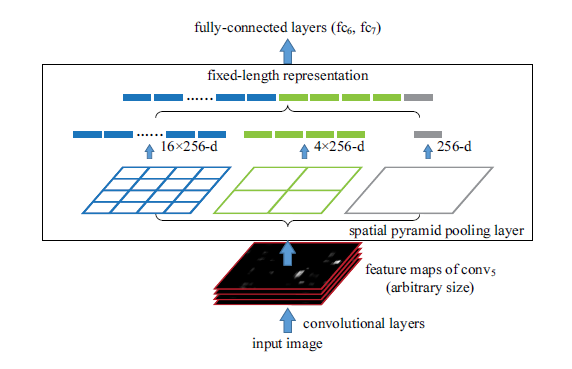
细节:
只用了两种bin size 来构建训练集,180 * 180, 224 * 224. 因为只有两种情况,所以可以很方便的构建bp函数
3、FastCNN - 要啥金字塔,一层就够啦
—— <Fast R-CNN>
Q:
a.对于每个 box/proposal 都需要进行一次feed forward.
b.训练时需要对分类函数和回归函数分开训练
A:
a.对图像进行一次整体的feed forward,得到总的卷积结果;对总结果中的box,每个box一次,分别进行ROI pooling (其实就是金字塔的第一层)
b. ROI pooling 后会得到固定维度的向量,送入多次全连接层,直接映射成类别和box的回归
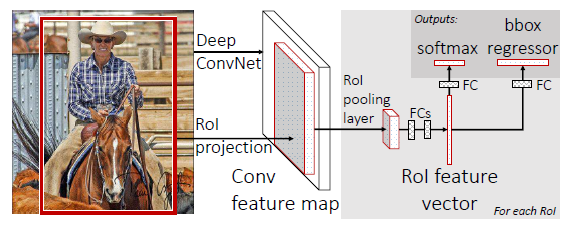
细节:
1、训练时,所有的权重都得到迭代
4、Faster R-CNN — 这才是颠覆
——<Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks>
Q:
a. 对每张图都要进行一次 selective search 以获得proposal太耗时了
A:
a.设计一个神经网络 Region Proposal Net 自动来提出proposal 吧!
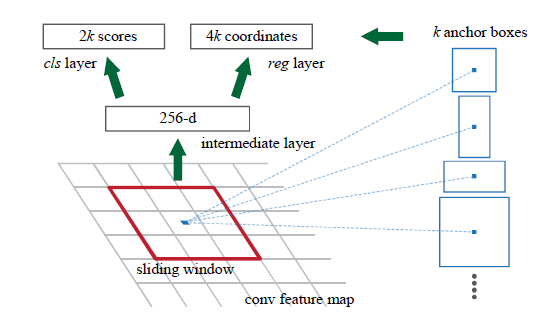
RPN 本质上可以看作一个非常独立的部分,虽然它号称使用了整幅图像的feature,但功能上RPN是独立的。RPN的任务是输入图像,输出一系列Proposal(四点坐标+是否有物体)
1、使用卷积网络的最后一个卷积层卷积完的结果 Last_Image * final_convolution2dlayer(n,d). 作为RPN的真正输入(前面都是公用的,后面才是RPN)
2、使用一个3*3的小卷积掩模将1中的结果抽象成d 维向量。
3、将该向量送入2个全连接层——分类全连接(2K输出)和坐标全连接(4K输出)————k个proposal (3 scale,2 aspect ratio)
4、在2中,掩模的位置决定了全连接输出参数的"原点"
5、总结
在神经网络中,全连接是最强的非线性映射方式,也是花费最重的。在结果层少量的使用全连接以换取强大的映射方程是很有意义的。
说了那么多,和三维视觉有毛关系?其实关系在这里,在二维图像中检测物体位置和在三维图像中检测物体位姿是对偶的。不信?见 <Deep Sliding Shapes for amodal 3D object detection in RGB-D images>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号