
位、字节、字符、bytes、str、编码(ascii/gbk/uft)
1.位bit
计算机中的概念。
数据存储的最小单位。每个二进制数字0或者1就是一个位。
2.字节byte
计算机中的概念。
8位组成一个字节,即:1 byte (字节)= 8 bit(位);
也就是8位0/1有序数值。每一个字节有256种状态。
3.字符
客户端可见的最小单元,如a、A、中、+、*、の...
是我们平时在文档中用到的最小单元。
4.bytes
python3中的一种数据类型,是多个字节的序列。它的内容都是0、1有序值。
每一个字节有256种状态。
类似于str是多个字符的有序序列。
4.encode编码
编码只发生在字符或者字符串与二进制之间,如果把字符串看做多个字符,那么可以理解编码为字符与二进制之间的转换规则,
而不是int/float/list等什么东西与二进制的转换。
有多种编码格式,ascii、gb2312、gbk、unicode、utf8、台湾大五码、日本jis码...后面的所有编码都是兼容ascii码的,但它们之间不一定兼容。
以汉字为例说明整个编码表的大体玩法。
一开始美国人发明了计算机,但计算机整个就是个0、1系统,其它的它什么都不会,于是美国人创造了ascii编码,把他们常用的字母、一些数学符号、标点
符号通过ascii全都用0、1表示,有96个打印字符,和32个控制字符组成;一共96+32=128个;
用7位二进制数来对每1个字符进行编码;
而由于7位还还不够1个字节,而电脑的内部常用字节来用处理,每个字节中多出来的最高位用0替代;
0 000 0000.........................0
0 111 1111..........................127; 从0----127,来表示128个ACSii编码;
比如:字符 'A'----------在计算器内部用0100 0001 (65)来表示;
字符'a'-----------在计算器内部用0 110 0001 (97)来表示;
注意:'10'在计算器内部是没有编码的,因为它是字符串,而不是单个字符。可以分别对1,0字符编码存储;这也就是上面标红处的意思,因为编码
都是对字符的编码,所以当10或404出现在文档中时,他分别把它们当做2字符串‘10’和3字符串‘404’来处理。这样基本上美国人可以做大部分它们想做的了。
但如果我们中国人想用电脑写汉字呢?写不了,因为电脑中没有汉字,只有0、1。于是我们也和美国人一样也编码,用特定的0、1序列和汉字对应起来,
这就是GB2312,1980年发布,GB/T 2312标准共收录6763个汉字,其中一级汉字3755个,二级汉字3008个;同时收录了包括拉丁字母、希腊字母、日文平
假名及片假名字母、俄语西里尔字母在内的682个字符。GB/T 2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的
使用频率。但对于人名、古汉语等方面出现的罕用字和繁体字,GB/T 2312不能处理,因此后来GBK及GB 18030汉字字符集相继出现以解决这些问题。
GB2312兼容ascii表。GBK是对GB2312的升级版,兼容gb2312。它们都是两字节编码系统,也就是用2个字节来表示一个字符,且每个字节最高位为1,这样
理论上可以有2^7 * 2^7=128*128=16384个字符。这样我们可以用这套编码在计算机上写汉字。
同时,其它国家也得做它们自己语言的编码,比如日本的jip码,韩国、俄罗斯也有它们自己的编码系统。
但这样也有个问题,如果你是做语言研究的,一篇文章中需要有中文、韩文、日文,那就不行了。
各个国家都像中国一样搞出自己的一套编码系统。这对于软件的国际化是一种转换上的灾难。ISO(国际标准化组织)决定着手解决这个问题,废除了所
有的地区性编码方案,重新搞一个包括了地球上所有文化、所有字母和符号的编码。跟以前现有的任何编码(除了ascii)都不兼容。UTF-8的特点是对不同范围
的字符使用不同长度的编码,多字节编码系统,1--6个字节,中文大部分落在了3个字节。
| 编码 | 特点 | ||
| ascii | 单字节编码系统,第一位为0,共128个字符。 | ||
| gb2312 | 两字节编码系统,共有6763个汉字+682个全形字符,每个字符最高位为1。 | 汉字两个字节 | |
| gbk | 对gb2312的扩展,gb扩展。 | 汉字两个字节 | |
| ANSI |
ANSI编码不是一种特定的编码。 在简体中文系统下,ANSI编码代表着GB2312 编码; 在日文操作系统下,ANSI编码代表着JIS编码 |
||
| utf8 |
它可以用一至四个字节对Unicode字符集中的所有有效编码点进行编码,属于Unicode标准的一部分 之前可以用到1-6个字符编码,后来调整为1-4个字节编码。 中文一般落在了3个字节。 对于0~127,完全跟 ASCII 相同。使用一个字节。 自2009年以来,UTF-8一直是万维网的最主要的编码形式,它逐渐成为电子邮件、网页及其他存储或发送文字优先采用的编码方式。 |
汉字三个字节 | |
| utf16 |
对于所有的字符都用两个字节来表示。 优点是长度固定。在Java语言中,字符就是采用了UTF-16的编码方式。缺点是跟ASCII不兼容。 |
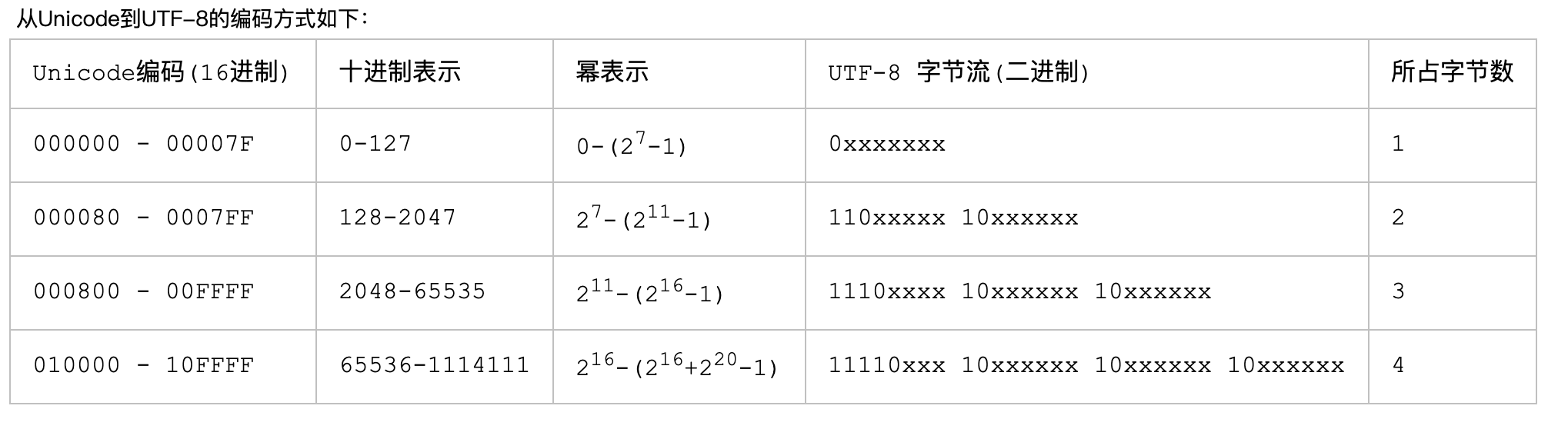
1、单字节的字符,字节的第一位设为0,对于英语文本,UTF-8码只占用一个字节,和ASCII码完全相同;
2、n个字节的字符(n>1),第一字节的前n位设为1,第n+1位设为0,后面字节的前两位都设为10;
3、2个字节,第一个字节的前2位是1;3个字节,第一个字节的前三位是1; 4个字节,第一个字节的前4位都是1;
当对一个文档指定了编码方式后,计算机可以自动的去识别0、1串,分别解析出相应的字符。
参考资料:
posted on 2020-05-11 15:07 静静的白桦林_andy 阅读(1392) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号