登陆新浪微博&批量下载收藏内容[Python脚本实现]
今天开新浪微博,才发现收藏已然有2000+了,足足104页,貌似需要整理下了,可是一页页整理,难以想象
所以想下载,然后进行提取处理,转为文档
我们关注的:
1.微博正文+评论内容
2.图片
3.视频链接
用python实现
思路:
1.脚本模拟登陆新浪微博,保存cookie
2.有了cookie信息后,访问收藏页面url
3.从第一页开始,逐步访问,直到最后,脚本中进行了两步处理
A.直接下载网页(下载到本地,当然,要看的时候需要联网,因为js,图片神马的,都还在)
B.解析出微博需要的内容,目前只是存下来,还没有处理
后续会用lxml通过xpath读取,转换成文档,当然,图片和视频链接也会一同处理,目前未想好处理成什么格式。(困了,明后天接着写)
模拟登陆微博采用是http://www.douban.com/note/201767245/
里面很详细,直接拉来用了
步骤:
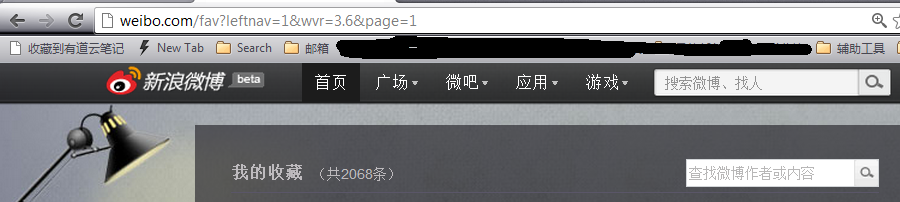
1.进入自己的微博,右侧,收藏,进入收藏页面
http://weibo.com/fav?leftnav=1&wvr=3.6&page=1
拿前缀
2.修改脚本填写\
用户名
密码
前缀http://weibo.com/fav?leftnav=1&wvr=3.6&page=
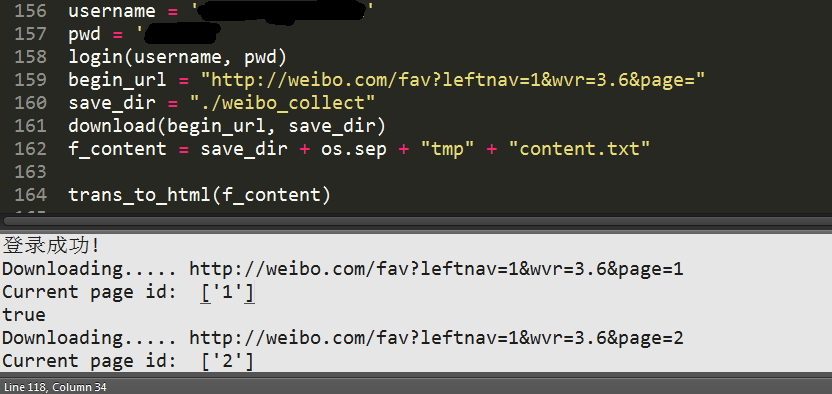
3.运行脚本
python weibo_collect.py
结果:
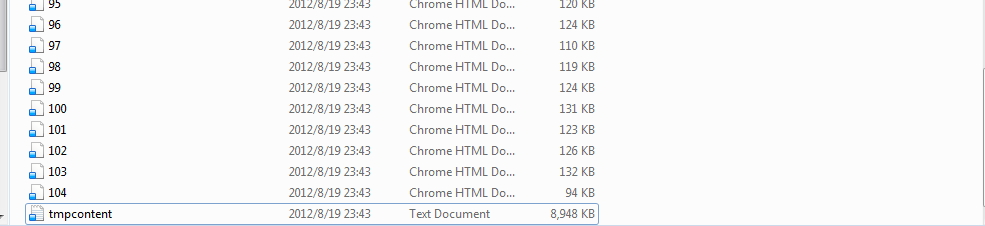
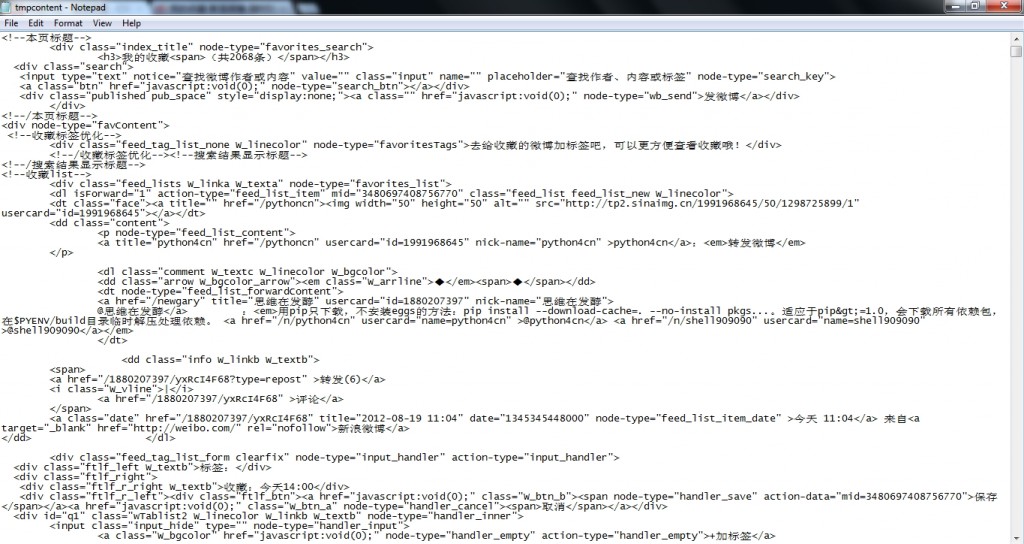
其中,带序号的,只能连网时点击打开有效
tmpcontent是包含所有微博内容信息,但目前还没有处理(还没想好提取成什么格式,容后再说)
附上脚本
#!/usr/bin/env python
#coding=utf8
import urllib
import urllib2
import cookielib
import base64
import re
import json
import hashlib
import os
#login code from: http://www.douban.com/note/201767245/
#加了下注释
# cookie -> opener -> urllib2.
# 然后,urllib2的操作相关cookie会存在
# 所以登陆成功之后,urllib2的操作会带有cookie信息,抓网页不会跳转到登陆页
cookiejar = cookielib.LWPCookieJar()
cookie_support = urllib2.HTTPCookieProcessor(cookiejar)
opener = urllib2.build_opener(cookie_support, urllib2.HTTPHandler)
urllib2.install_opener(opener)
postdata = {
'entry': 'weibo',
'gateway': '1',
'from': '',
'savestate': '7',
'userticket': '1',
'ssosimplelogin': '1',
'vsnf': '1',
'vsnval': '',
'su': '',
'service': 'miniblog',
'servertime': '',
'nonce': '',
'pwencode': 'wsse',
'sp': '',
'encoding': 'UTF-8',
'url': 'http://weibo.com/ajaxlogin.php?framelogin=1&callback=parent.sinaSSOController.feedBackUrlCallBack',
'returntype': 'META'
}
def get_servertime():
url = 'http://login.sina.com.cn/sso/prelogin.php?entry=weibo&callback=sinaSSOController.preloginCallBack&su=dW5kZWZpbmVk&client=ssologin.js(v1.3.18)&_=1329806375939'
data = urllib2.urlopen(url).read()
p = re.compile('\((.*)\)')
try:
json_data = p.search(data).group(1)
data = json.loads(json_data)
servertime = str(data['servertime'])
nonce = data['nonce']
return servertime, nonce
except:
print 'Get severtime error!'
return None
def get_pwd(pwd, servertime, nonce):
pwd1 = hashlib.sha1(pwd).hexdigest()
pwd2 = hashlib.sha1(pwd1).hexdigest()
pwd3_ = pwd2 + servertime + nonce
pwd3 = hashlib.sha1(pwd3_).hexdigest()
return pwd3
def get_user(username):
username_ = urllib.quote(username)
username = base64.encodestring(username_)[:-1]
return username
def login(username, pwd):
url = 'http://login.sina.com.cn/sso/login.php?client=ssologin.js(v1.3.18)'
try:
servertime, nonce = get_servertime()
except:
return
global postdata
postdata['servertime'] = servertime
postdata['nonce'] = nonce
postdata['su'] = get_user(username)
postdata['sp'] = get_pwd(pwd, servertime, nonce)
postdata = urllib.urlencode(postdata)
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux i686; rv:8.0) Gecko/20100101 Firefox/8.0'}
req = urllib2.Request(
url=url,
data=postdata,
headers=headers
)
result = urllib2.urlopen(req)
text = result.read()
#p = re.compile('location\.replace\(\'(.*?)\'\)') p = re.compile(r'location.replace\("(.*)"\)')
try:
login_url = p.search(text).group(1)
#print login_url
urllib2.urlopen(login_url)
print "登录成功!"
except:
print 'Login error!'
#收藏页网页源代码存在current,表示当前页,判断最后页
p4currentpageid = re.compile(r'page=(\d*)\\" \\n\\t\\t class=\\"current\\"')
#新增
def download(url, save_dir, frompid=1):
if not os.path.exists(save_dir):
os.mkdir(save_dir)
#os.mkdir(save_dir + os.sep + "tmp")
i = frompid
lastpage = ""
content = open(save_dir + os.sep + "tmp" + "content.txt", "w")
while True:
source_url = url + str(i)
print "Downloading.....", source_url
data = urllib2.urlopen(source_url).read()
#print data
#拿到当前页
current_pageid = p4currentpageid.findall(data)
print "Current page id: ", current_pageid
if current_pageid:
page_id = current_pageid[0]
#若是超出了,代表已经下载到最后一页了
if page_id == lastpage:
break
lastpage = page_id
#保存每一页微博主体部分,转汉字,utf-8,存文件,目前是html格式,尚未进行二次处理
lines = data.splitlines()
for line in lines:
if line.startswith('<script>STK && STK.pageletM && STK.pageletM.view({"pid":"pl_content_myFavoritesListNarrowPlus"'):
print "true"
n = line.find('html":"')
if n > 0:
j = line[n + 7: -12].encode("utf-8").decode('unicode_escape').encode("utf-8").replace("\\", "")
content.write(j)
if data:
f = open(save_dir + os.sep + str(i) + ".html", "w")
f.write(data)
f.close()
i += 1
content.close()
def trans_to_html(f_content):
f = open(f_content)
detail = f.read()
print len(detail)
#使用lxml进行处理,xpath读取对应的内容,清理转为目标格式
f.close()
username = 'your account'
pwd = 'your password'
login(username, pwd)
begin_url = "http://weibo.com/fav?leftnav=1&wvr=3.6&page="
save_dir = "./weibo_collect"
download(begin_url, save_dir)
f_content = save_dir + os.sep + "tmp" + "content.txt"
trans_to_html(f_content)
Ok,至于怎么转,后续再搞
to be continue.....
睡了,晚安
wklken
2012-08-19
Meet so Meet.
C plusplus
I-PLUS....

 浙公网安备 33010602011771号
浙公网安备 33010602011771号