
这篇文章是关于,如何修改hadoop的src以实现在client端上传大文件到HDFS的时候,
为了提高上传的效率实现将文件划分成多个块,将块并行的写入到datanode的各个block中
的初步的想法,本文会根据实时的进展不断的进行修改。
如果想实现并发写的话,应该先了解一下系统原始的工作原理
关于客户端向HDFS的写
在Java的写操作过程中大致遵循下面的流程:
首先会根据文件的路径和文件的名称,创建一个File实例,
然后根据该File的实例 创建 写出流 即OutputStream 对象,
基于该OutputStream 对象 调用write 方法。
所以按照该流程,分析一下客户端如何向 HDFS进行写操作:
1.文件的create
在上传一个文件 到HDFS,一般会在 Client端 调用DistributedFileSystem.create 方法,
关于 DistributedFileSystem.create 方法实现 伪码如下
FSDataOutputStream create ( Path f , FsPermission permission , boolean overwrite , int bufferSize ,
short replication , long blockSize, Progressable progress ) {
/*
Path : f 要创建的文件的路径
FsPermission : permission 用户权限,要在系统中创建文件的话,必须要权限满足
boolean : 是否已全覆盖的方式创建文件,即文件出现重名的时候,是否覆盖原来的文件
*/
return new FSDataOutputStream ( dfs.create ( getPathName ( f ) , permission,
overwrite , replication , blockSize , progress , bufferSize ) , statistics ) ;
}
//dfs is an instance of DFSClient used in DistributedFileSystem as a member variable
正如上文注释所说的, dfs 是在DistributedFileSystem中的DFSClient对象实例,
而DFSClient类中的create方法 会返回一个OutputStream对象,
而OutputStream 是 FSDataOutputStream 和 DFSOutputStream 的父类。
通过 return 方法之后 会通过塑性的方式,将其强制从 DFSClient.create 的DFSOutputStream转为
OutputStream 然后 再转为 FSDataOutputStream。
下面是DFSClient 中的 create 方法的部分代码:
OutputStream create ( String src, FsPermission permission , boolean overwrite , short replication , long blockSize , Progressable progress , int buffersize ) { checkOpen () ; ..... OutputStream result = new DFSOutputStream ( src, masked , overwrite, replication , blockSize , progress , buffersize ,
conf.getInt ( "io.bytes.per.checksum" , 512 )); ..... return result ; }
在上面的代码中 有conf.getInt("io.bytes.per.checksum",512) ;
这个实质上是在通过系统中的 Configuration 实例 conf 来访问hadoop的配置文件中的某个字段的值。
可以通过该实例来设置配置文件中的字段,也可以抽取字段的值进行访问。
而在上面的代码中,可以看到DFSClient.create 方法会调用到 DFSOutputStream的构造方法:
这也就是说到目前为止,create 文件的时候:
流的流向 是从 DFSOutputStream 通过 DFSClient.create 流向 Distribute.create
并从DFSOutputStream->OutputStream->FSDataOutputStream 最终 被Client所获得的。
如果想要知道,在create 文件的时候底层发生了什么,还需要查阅DFSOutputStream的构造方法。
下面是DFSOutputStream的构造方法:
DFSOutputStream ( String src , FsPermission masked , boolean overwrite , short replication ,
long blockSize , Progressable progress, int buffersize , int bytesPerChecksum ) { this (src , blockSize , progress, bytesPerChecksum ) ; //在此构造方法中调用其他的重构的 constructor ,但这个不是重点 computePacketChunkSize ( writePacketSize , bytesPerChecksum ) ; //调用 computePacketChunkSize 方法来计算 要发送的Packet的大小,
//以及为该报文加入了 校验和之后,相应的文件偏移量的变化,由于是创建文件阶段,
//此处应该是发送一个空的packet try { namenode.create ( src, masked , clientName, overwrite, replication , blockSize ) ; // 此处是研究的重点 本方法是通过DFSClient中实现了的ClientProtocol 接口的namenode
//通过RPC调用NameNode 的create方法来创建一个文件, 而真正RPC调用实现的是由
//FSNamesystem类中的create方法 } catch (...) {...} streamer.start () ; //在这里调用DataStreamer 来启动一个pipeline,用于执行写数据操作 }
既然上述代码是通过RPC调用NameNode的方法的那么接下来,来分析一下NameNode
NameNode的create方法实际上在方法内部调用的是 实现了NameNode大部分方法的
FSNamesystem 的 startFile 这一方法, 即 Client -> RPC ---> NameNode --> FSNamesystem.startFile
并且,FSNamesystem 在namenode 中是作为成员变量存在的。
继续来看 FSNamesystem.startFile ,在该方法内部实质调用的是 FSNamesystem.startFileInternal
所以Client端 在发送给NameNode 创建文件的命令的时候,实质上是调用
FSNamesystem.startFileInternal 这个方法
void startFielInternal ( String src , PermissionStatus permissions, String holder , String clientMachine , boolean overwrite , boolean append , short replication , long blockSize ) { //在这里仅仅创建一个文件存放实例: INodeFile ,它的状态是以INodeFile
//实例的子类: INodeFileUnderConstruction 所存在的
//系统仅仅为它在NameNode.FSNamesystem.FSDirectory.
//INodeDirectoryWithQuota.rootDir 上面分配一个INode
//(INode是 INodeFile 的父类) 所谓目录的一个节点,但是
//并未针对该INodeFile所对应的File 分配实际存放数据的实体 即Blocks
//即 INodeFile.blocks [] 数组是为空的。 long genstamp = nextGenerationStamp () ; INodeFileUnderConstruction newNode = dir.addFile ( src, perissions , replication, blockSize , holder, clientMachine , clientNode , genstame ) ;
//创建一个newNode(INodeFile) 将其加入到系统目录树中后, 将可以找到它的地址返回给newNode 进行存放 .... }
对于INodeFile 和INodeFile 都是INode的子类,
在INodeFile中有一个 继承自父类 INode 的成员变量: BlockInfo blocks []
这个BlockInfo blocks [] 其实是一个映射表, 在blocks 中记录了
该INodeFile 对应的文件实体 所对应的 存放文件数据的 所有blocks 在 整个HDFS中的 各个datanode上面的映射关系。
即INodeFile.blocks 中存放的 记录该文件的 所有blocks 在HDFS 中的 datanode上面的 分布情况。
但是,目前阶段,仅仅是 create阶段,所以 并不为该文件 对应的INodeFile 对应的blocks 分配任何的block实例。
如果想要实现并行写操作的话,先写、写好了提交,然后在分配下一个块,这样的工作机制是根本行不通的。
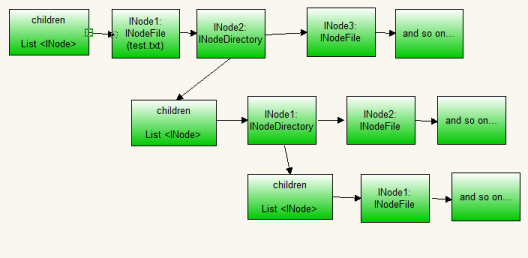
上面的图是用来描述Hadoop的NameNode端的 系统文件树的,
也就是NameNode.FSNamesystem.FSDirectory.INodeDirectoryWithQuota(INodeDirectory子类).children:
这是一个 INode的List:
如果某一个分分支节点下是一个文件夹,对应的是INodeDirectory,而INodeDirectory又有children又会映射新的分支,
于是递归下去...
如果某一个分支节点下是一个文件实体,对应的是INodeFile
所以如果创建一个文件的话, 该节点一定会被挂在到树的最后一个,并且由于还未写入数据
或是正在接受数据,所以该INodeFile 应该处于的是UnderConstruction的状态。
实际Hadoop的写一个块的情况是这样的,也就是为当前正在写的文件,增加一个block的话。
1. 需要通过文件系统树找到 树中的最后一个节点,最后这个节点必定是属于正在创建的File
2.允许添加block的文件的INodeFile一定是 UnderConstruction状态的
3.得到该INode list 上的最后一个节点后 将其从INode强制属性为 INodeFielUnderConstruction
4.访问它的blocks ,在blocks 的最添加上一个block,在修改其他的属性
上面介绍的是,在Client 向HDFS发送 create 文件的时候, NameNode 相应的一些列操作
接下来将介绍一下 在 Write的时候 DataNode 和NameNode上的一些列操作,以及类与方法间的操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号