AMD核显运行DeepseekR1-7b:使用mlc-llm框架,利用vulkan推理
任何支持vulkan的显卡都能跑!
本文使用的是Radeon890M核显,内存有多大就等于显存有多大。劲啊
1. 安装mlc-llm
windows+vulkan:
conda activate your-environment
pip install --pre -U -f https://mlc.ai/wheels mlc-llm-nightly-cpu mlc-ai-nightly-cpu
linux+vulkan:
conda activate your-environment
conda install -c conda-forge gcc libvulkan-loader
pip install --pre -U -f https://mlc.ai/wheels mlc-llm-nightly-cpu mlc-ai-nightly-cpu
2. 下载模型
git lfs install
git clone https://huggingface.co/mlc-ai/DeepSeek-R1-Distill-Qwen-7B-q4f16_1-MLC
3. 运行
mlc本身可以用cli进行交互式问答,但是启动的时候识别核显内存大小会出错。我直接用server模式强行绕过该问题
mlc_llm serve ./DeepSeek-R1-Distill-Qwen-7B-q4f16_1-MLC/ --overrides "gpu_memory_utilization=3"
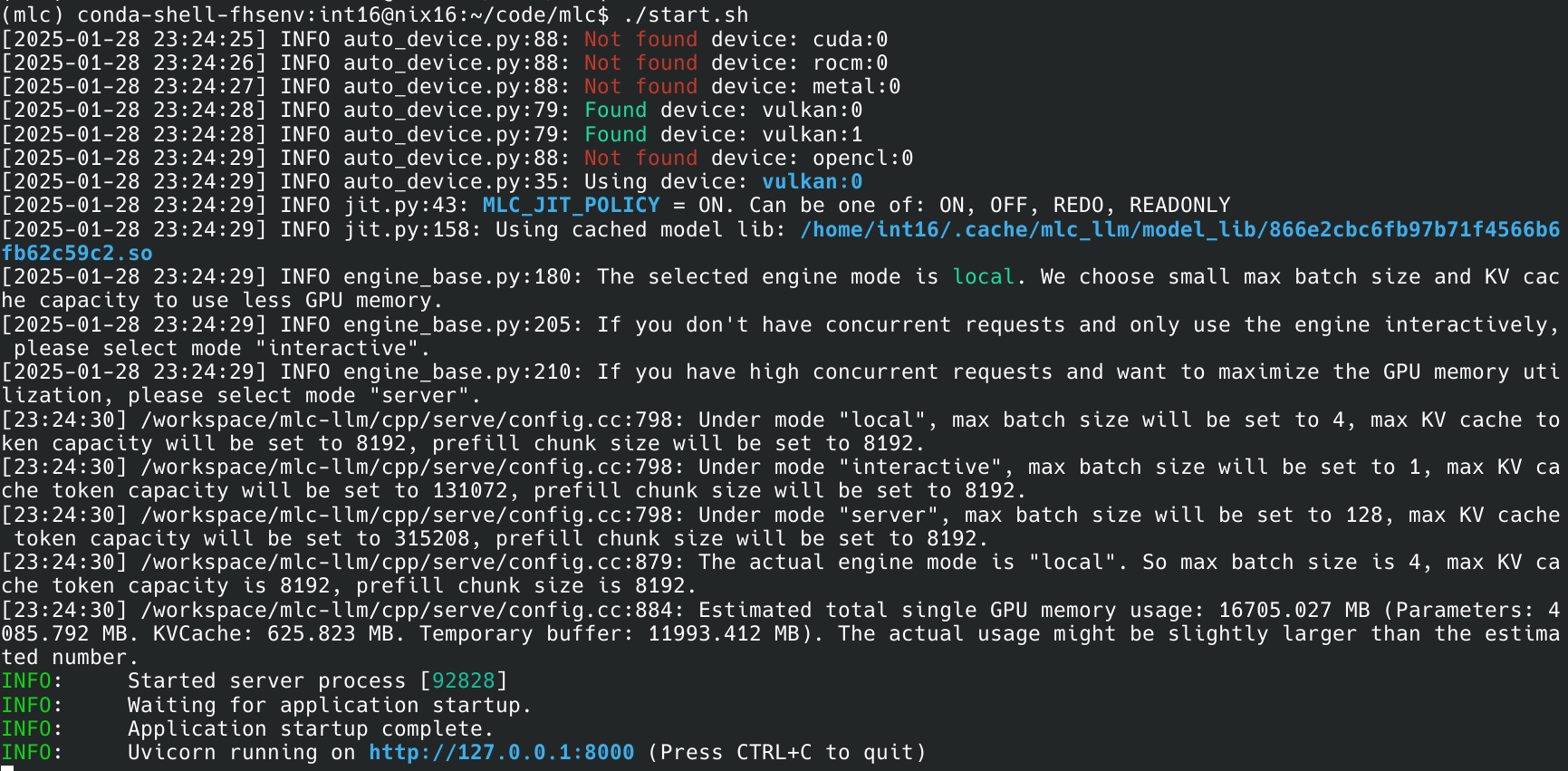
然后随便写个python脚本就能发送请求
import requests
import json
# Get a response using a prompt with streaming
payload = {
"messages": [{"role": "user", "content": "请简单介绍下deepseek。"}],
"stream": True,
}
with requests.post("http://127.0.0.1:8000/v1/chat/completions", json=payload, stream=True) as r:
for chunk in r.iter_content(chunk_size=None):
chunk = chunk.decode("utf-8")
if "[DONE]" in chunk[6:]:
break
response = json.loads(chunk[6:])
content = response["choices"][0]["delta"].get("content", "")
print(content, end="", flush=True)
print("\n")
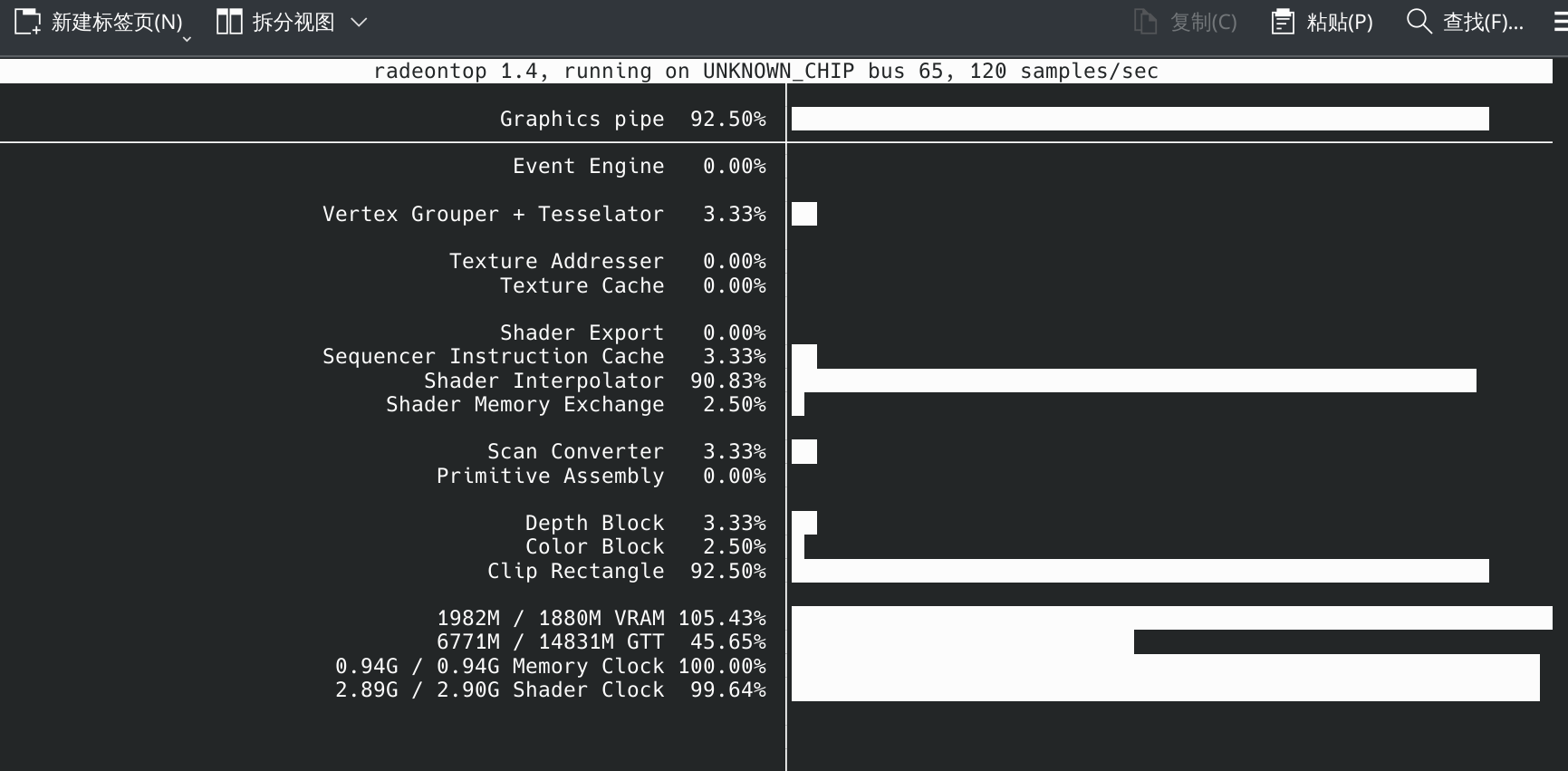
速度快的一笔

核显吃满了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号