HIERARCHICAL REINFORCEMENT LEARNING BY DISCOVERING INTRINSIC OPTIONS
发表时间:2021(ICLR 2021)
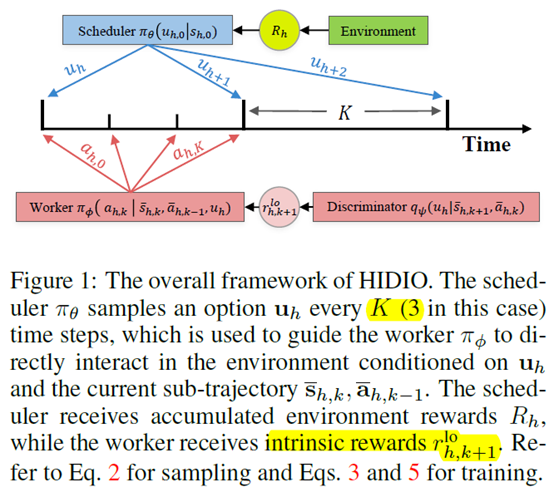
文章要点:这篇文章提出了一个分层强化学习算法HIDIO (HIerarchical RL by Discovering Intrinsic Options),用自监督的方式来学习任务无关的options,避免了人为设计,同时利用这些options来解决稀疏回报任务。这些options基于intrinsic entropy的目标函数来进行学习,所以这些options具有多样性,并且是任务无关的(These options are learned through an intrinsic entropy minimization objective conditioned on the option sub-trajectories. The learned options are diverse and task-agnostic)。Options就可以理解成一连串具体的动作(option is translated to a sequence of actions by an option-conditioned policy with a termination condition)。
具体的,上层policy(the scheduler \(\pi_\theta\))的目标是通过选择options最大化环境的reward,下层policy(the worker \(\pi_\phi\))的目标是通过自监督的方式有效地发现options。然后每隔K个step,上层policy就输出一个option,option是一个D维的latent representation \(u \in [-1,1]^D\)。如果每个episode的长度是T,那么上层policy的轨迹长度就是
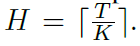
上层的优化目标就是最大化环境reward
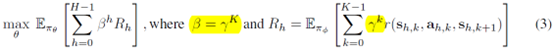
这里各个符号的含义定义如下
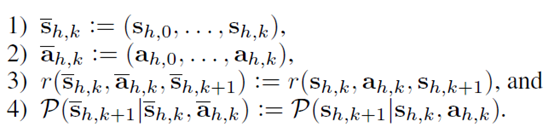
这里定义的符号都是和上层轨迹相关的,右边是下层的动作和状态,左边是上层的option,状态和reward。作者把上层的option和状态
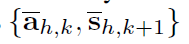
叫做option sub-trajectories。
然后下层policy就以这个option sub-trajectories作为输入,执行具体的动作

下层的目标就是最小化option的entropy
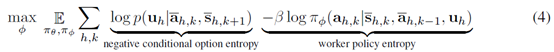
注意,这里的第一项就是最小化option \(u_h\)的entropy,作者的解释是,为了让下层更加坚定这个option的含义(the first term suggests that the worker is optimized to confidently identify an option given a sub-trajectory.)。第二项是最大化下层policy的entropy,作者的解释就是增加覆盖度,有点像增加探索。
具体做的时候,后验概率p是不知道的,所以搞一个网络q来估计,最后式子变成
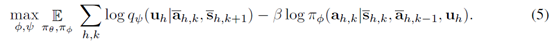
所以下层的reward就是
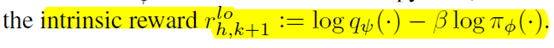
训练的时候上下层一起训练,用的SAC算法。
总结:想法是好的,自己去发现option,自己去把分层给做了。上层的训练还比较好理解,下层的训练不是很好理解。具体怎么就work了不太明白。
疑问:层这个优化目标真的有用吗,这样就能发现option?
文章里面K设成的3,这个分层的option长度是不是有点过于短了?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号