PROCEDURAL GENERALIZATION BY PLANNING WITH SELF-SUPERVISED WORLD MODELS
发表时间:2022(ICLR2022)
文章要点:这篇文章基于muzero来度量model-based agent的泛化能力。主要研究了三个因素:planning, self-supervised representation learning, and procedural data diversity。Planning就是指MCTS,self-supervised representation learning就是指learned model,procedural data diversity就是指我的训练集有多少个MDP,相当于我在多少个环境或者任务上训练的,多就说明procedural data diversity大,这样泛化就会相对容易。
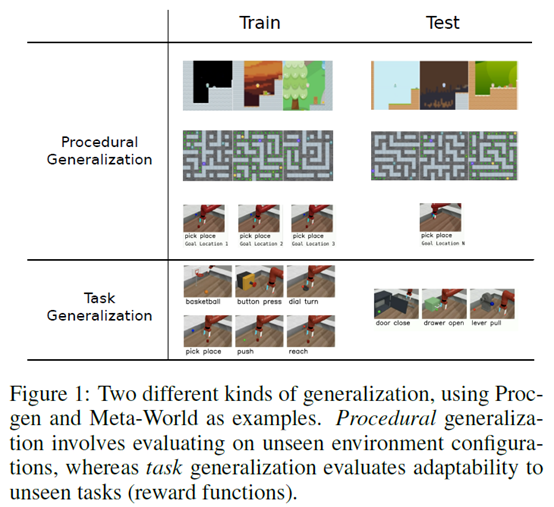
然后主要考虑两种泛化性:procedural and task。Procedural generalization指的是reward function不变,但是观测发生改变,比如显示方式、地图地形、目标位置等等。Task generalization就是说环境是一样的,但是reward function(task)发生改变。得出了结论是,muzero在这两种泛化性问题上总体来说表现都很好。Planning对泛化性很重要,主要来源于动作选择和策略优化(while simply learning a value-equivalent model can bring representational benefits, the best results come from also using this model for action selection and/or policy optimization)。self-supervised representation learning对于performance和data efficiency很有帮助,对数据多样性的要求也变低了,这得益于学到了一个更准确的world model,对细节的学习更精确(the primary benefit brought by self-supervision is in learning a more accurate world model and capturing more fine-grained details such as the position of the characters and enemies.),学到的表征更稳健(self-supervision leads to more robust representations)。但是在ML-45这个任务上,发现效果不行,得出的结论是对于不同的泛化问题需要不同的方法。
总结:问题挺好的,但是单单从performance来说泛化性好坏,以及解释原因,总觉得有点站不住脚。就是这之间好像没有必然的因果关系,内部原理还是不清楚。
疑问:无。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号