Decoupling Exploration and Exploitation for Meta-Reinforcement Learning without Sacrifices

发表时间:2021(ICML 2021)
文章要点:这篇文章想说,通常强化学习算法exploration和exploitation都是混在一起的,既探索环境的dynamics,同时也利用探索到的信息来提升策略。但是要想更好的更新策略,就需要好的探索来收集任务相关的信息;要想得到更好的探索策略,就需要基于当前学到的策略来指导探索。所以这就有一个chicken-and-egg problem,也就是汉语里面常说的鸡生蛋,蛋生鸡的问题。作者提出DREAM(Decoupling exploration and ExploitAtion in Meta-RL)算法,将exploration和exploitation两个过程分开考虑。首先定义exploration policy \(π^{exp}\),exploitation policy \(π^{task}\),然后exploration policy就在探索的episodes用,exploitation policy就在利用的episodes用。具体做法就是,先用exploration policy执行一个episode得到一条探索轨迹
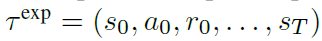
然后接下来的N个episodes就用exploitation policy,基于这个探索轨迹,来最大化return

注意这里的\(\mu\)是任务ID,相当于不同的任务都会有一个不同的ID来识别。
接下来的问题就是怎么去学这两个策略。首先学exploitation policy的时候,作者先搞了一个encoder

这个encoder的作用,作者说是为了从任务ID \(\mu\)里提取出和任务相关的信息,扔掉任务无关的信息。这里作者又扯了一下information bottleneck,其实不用管。更新的目标为
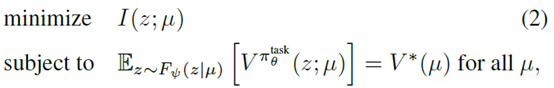
这里的I就是作者说的information bottleneck,其实在用的时候就是一个l2的正则项
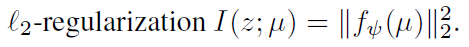
下面subject to的式子就是让return在这个情况下达到optimal。真正优化的时候其实是优化

这个式子用来更新encoder和exploitation policy。然后exploration policy的更新,就去最大化任务ID和exploration policy采的轨迹的互信息
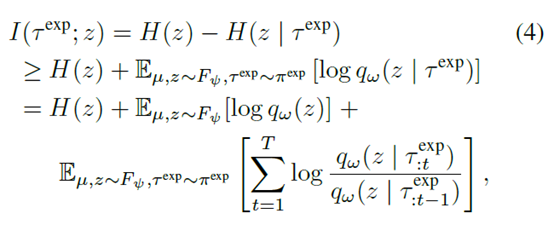
这里的z就是任务ID \(\mu\)经过encoder得到的。作者就想说,这个时候z包含的信息就是任务相关的了,那我的exploration policy要干的事情就是探索和这个任务相关的轨迹,所以目标函数就是最大化这两的互信息。具体更新的时候就是式子(4)里那个,最大化variational lower bound。然后两个policy最大化的目标都有了,剩下的就是用RL去做这个事情。文章里用的double DQN去更新。算法伪代码如下

总结:文章主要想说把exploration和exploitation拆开,然后做meta-RL的训练。整个过程感觉有点道理,但是又没明白为啥可以。没看懂。
疑问:这个强行说这个是meta-RL,感觉和meta关系不大啊,顶多算是考虑了一下RL的泛化性以及few-shot learning?
感觉exploitation policy那里,information bottleneck到底怎么保留任务相关信息的,还是不清楚啊。如果只是当成一个正则化项还好理解点,说成discard task-irrelevant information,不明白是怎么做到的。
Exploration policy那里,推到最后好像就是去比一下到时间t的轨迹相较于到时间t-1的轨迹,是不是更有可能得到encoder z,但是q又是随便初始化的一个,和encoder又不一样,这里不知道是啥意思。然后作者的解释是测试的时候,得不到问题ID \(\mu\),所以用这个q去生成z然后代替encoder生成的z。但是问题是q是基于探索策略的轨迹的,探索策略又是基于z去训练的,绕了一圈又绕回去了呀好像。感觉这中间的逻辑还是没捋清楚啊。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号