Planning to Explore via Self-Supervised World Models
发表时间:2020(ICML 2020)
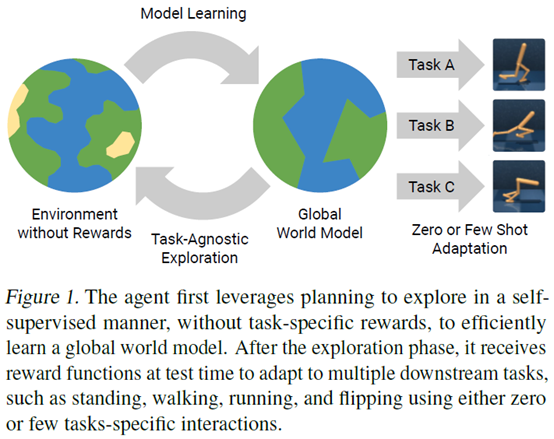
文章要点:这篇文章提出了一个Plan2Explore的model based方法,通过self-supervised方法来做Task-agnostic的探索,在这个过程中有效学习了world model,然后可以迁移到下游的具体任务上,实现zero or few-shot RL。具体的,world model包含encoder,dynamics,reward,decoder几个部分
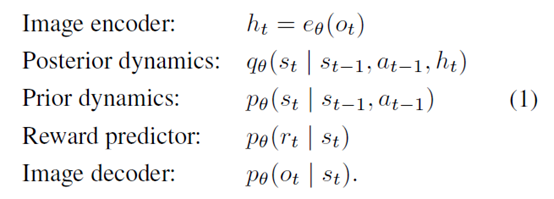
然后RL部分有actor和value
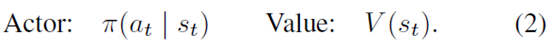
在做exploration的时候,reward就是model的uncertainty。实现的方式是ensemble,通过学多个one-step predictive models,得到下一个图像的embedding预测
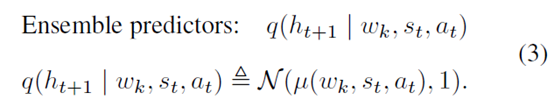
然后通过计算方差得到reward

整个结构长这样
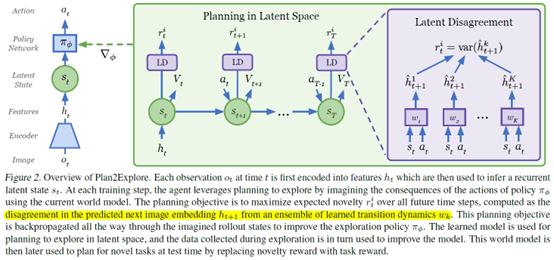
然后就可以用RL进行训练了,训练的方式和Dreamer算法一样,就是把RL用到world model上训练更新policy,同时在environment上交互,收集数据更新model。算法伪代码如下

有了这个之后,当需要学习某个具体的任务的时候,就根据任务构造一个新的reward function,基于这个reward function来学习policy。需要注意的是,这里的训练都是在world model里进行的,可以不用和真实环境交互

总结:model-based planning的好处还是在于可以探索没有见过的状态,而不是像count-based和prediction error based方法那样只能返回之前见过的状态,还是会有优势的(unlike prior methods which retrospectively compute the novelty of observations after the agent has already reached them, our agent acts efficiently by leveraging planning to seek out expected future novelty.)。explore部分还是很make sense的,就是不知道后面few shot RL效果具体如何,感觉model不管怎么训练,应该都会有误差,不知道对训练policy影响如何。
疑问:Model里面已经有了posterior dynamics
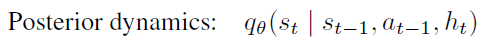
为啥还要搞个prior dynamics?

而且这里区分了一下features和latent state,这两有啥关系,为啥要搞两个东西?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号