Protecting Against Evaluation Overfitting in Empirical Reinforcement Learning
发表时间:2011(2011 IEEE symposium on adaptive dynamic programming and reinforcement learning (ADPRL))
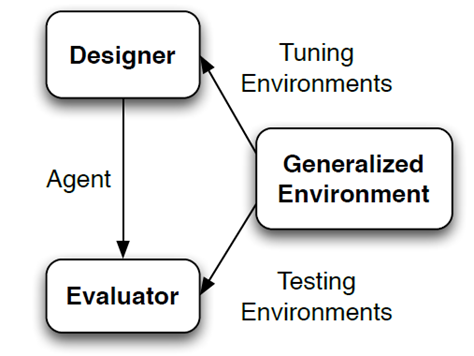
文章要点:文章想说RL算法很容易environment overfitting导致泛化性不足,比如设计者可能利用对环境的先验来设计算法等等。于是作者提出在evaluation的时候要用多个环境来评估。具体做法是我们想要解决某个问题,这个问题可能不只是一个环境,而是一堆服从某个target distribution的环境,那么我们就需要在这些环境上具有泛化性,所以我们需要evaluate agents on multiple environments drawn from the target distribution。就结束了。
总结:这篇文章看起来好像都是废话,考虑到文章发表的时间,可能当时比较创新吧。
疑问:无

 浙公网安备 33010602011771号
浙公网安备 33010602011771号