milvus和faiss安装及其使用教程
写在前面
高性能向量检索库(milvus & faiss)简介
Milvus和Faiss都是高性能向量检索库,可以让你在海量向量库中快速检索到和目标向量最相似的若干个向量,这里相似度量标准可以是内积或者欧式距离等。这里借用milvus官方的话再次说明这两个库的特点:
Milvus 是一款开源的、针对海量特征向量的相似性搜索引擎。基于异构众核计算框架设计,成本更低,性能更好。 在有限的计算资源下,十亿向量搜索仅毫秒响应。
说白了就是速度快,暂且不说十亿向量,自己写代码去完成对100万300维向量的余弦相似度计算并排序就需要不小的响应时间吧,就本人测试而言,即便使用scipy库计算速度依然要比milvus和faiss慢很多。
本文主要内容
本文主要内容分为三块:
- 两个高性能搜索引擎的对比
- milvus安装及其使用教程
- faiss安装及其使用教程
milvus和faiss的对比
在milvus开源之前,也存在高性能向量相似性搜索引擎(库),这个引擎就是Facebook的Faiss,功能都是一样的,具体可以参考官网 。
就我个人而言,我是推荐使用milvus的,主要是在我个人看来,milvus有如下几个好处:
- 多平台通用,mac,windows和linux都是支持的,因为milvus可以通过docker部署,因此平台通用性好了不少。
- 支持编程语言多,Java,c,c++和python都支持,要知道Faiss是不支持java的,这一点简直让人抓狂,github上好几个项目就是关于把Faiss转成java的,因为我Java和python都是要使用的,我把github上关于faiss转java的项目都试了个遍,结论就是非常难安装,只要Faiss版本更新了,必须要重来一遍,即便最后java可以用了,也不敢保证其稳定性。所以想在Java上用Faiss还是放弃吧。
- 在速度方面,就我自己测试而言,milvus不输Faiss,但是我没有使用GPU测试,有兴趣的小伙伴可以试一下。
当然Faiss也并非一无是处,首先速度并不输于Milvus,而且使用起来更方便,不需要使用docker,代码写起来更为简洁(后面章节会有示例代码,大家看了就知道faiss比较简洁了),且有大厂做技术支持,如果部署环境就是python,Faiss也是一个很好的选择。
milvus安装及其使用教程
milvus 安装步骤
milvus 一共有两种安装方式:自己编译安装和使用docker安装。这里推荐大家使用docker安装,docker安装方便快捷,可在Windows上使用。自己编译安装,由于每个人环境不同,很容易出问题。本文只介绍基于docker的安装,另外因为我比较穷,所以只介绍cpu版本的安装,不过gpu安装也是大同小异。
Step1 安装docker
首先就是要安装docker,还不了解docker可以了解一波,非常好用的虚拟机工具,强力推荐真是太香了,直接去Docker官网下载对应平台的安装文件即可。
Step2 下载相应版本镜像
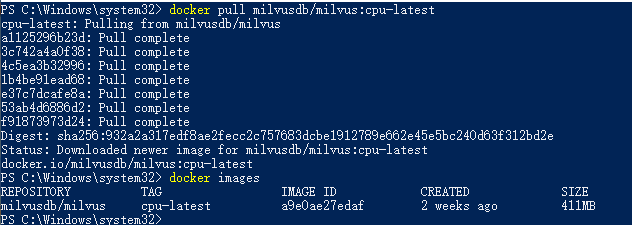
安装好docker后,要去pull对应的镜像(image),首先进到dockerhub官网,然后搜索milvus,第一个结果就是。因为我们安装的是CPU版本,所以在tags里找cpu-latest,然后pull下来就可以了,即在你的命令行窗口输入
docker pull milvusdb/milvus:cpu-latest。注意:随着版本迭代更新,这一条命令在未来可能会失效,建议先去dockerhub搜索一下,去看一下应该用什么tag。
pull好之后, 在docker images看一下应该会有该镜像,整个流程记录如下图:
Step3 设置配置文件和工作目录
在创建启动容器之前,我们要先设置配置文件。
在/home/$USER/milvus/conf 目录下创建 server_config.yaml 文件,然后将 server config 文件 的内容复制到你创建的配置文件中。
一般情况下 server_config.yaml文件不需要再修改,如果有个人配置需求,可根据官网教程进行修改。
然后就需要配置工作目录了,一共需要建立三个文件夹,在/home/$USER/milvus/目录下建立db,logs和wal文件夹。
注意上述目录均可根据自己需求进行修改,只是在启动docker服务是一定要映射到对的目录上!为了方便演示,我举个自己的目录例子,我的工作目录是C:\Users\Zhdun\milvus,我的目录结构是:
milvus
│
├─conf //配置文件目录
│ server_config.yaml //配置文件 搜索引擎配置都在这里修改
│
├─db //数据库存储目录 你的索引与向量存储的位置
│
└─logs //日志存储目录
│
└─wal // 预写式日志相关配置
Step4 启动docker服务
设置好工作目录后,就可以使用镜像创建容器了,以我自己工作目录为例,需要如下命令
docker run -td --name mymilvus -e "TZ=Asia/Shanghai" -p 19530:19530 -p 19121:19121 -v C:\Users\Zhdun\milvus\db:/var/lib/milvus/db -v C:\Users\Zhdun\milvus\conf:/var/lib/milvus/conf -v C:\Users\Zhdun\milvus\logs:/var/lib/milvus/logs -v C:\Users\Zhdun\milvus\wal:/var/lib/milvus/wal milvusdb/milvus:cpu-latest
命令看起来有点长, 我稍微解释下,-td是后台运行,--name是给自己的容器起个名字,-p是端口映射,不想用默认的话,可以去服务器配置文件里改,-v就是为了映射三个工作目录。具体可以参考docker的run命令。
执行完命令后,运行docker ps -a,如果发现自己创建的容器Exited的了,那就说明报错了,那就docker logs <container id>一下,看出了什么问题。如果发现容器在运行了,就代表基本没问题了。
正常启动记录如下截图:

接下来我会说一下常见的安装问题。
安装时的常见问题及解决
Config check fail: Invalid config version: . Expected config version: 0.1 遇到这种问题就在服务器的配置文件第一行加上version: 0.1。
Config check fail: Invalid cpu cache capacity: 1. Possible reason: sum of cache_config.cpu_cache_capacity and db_config.insert_buffer_size exceeds system memory.
这种问题就说明内存超出了限制,首先检查服务器配置里的 cpu_cache_capacity 和 insert_buffer_size 是不是过大了。
然后再检查给定docker设定的内存是多少,可以通过docker info来检查。
milvus 基本使用
安装完成后,终于可以开始使用milvus了,milvus支持python,java和c++。在这里我只介绍python的使用。
首先安装 pymilvus库:pip install pymilvus,然后就可以使用这个库来写代码了,接下来我会直接把自己写的范例代码贴上去,其中每一步的具体含义以及可能的扩展我会直接在注释里告诉大家,如有错误还请各位指出。
# -*- coding: utf-8 -*-
# 导入相应的包
import numpy as np
from milvus import Milvus, MetricType
# 初始化一个Milvus类,以后所有的操作都是通过milvus来的
milvus = Milvus(host='localhost', port='19530')
# 向量个数
num_vec = 5000
# 向量维度
vec_dim = 768
# name
collection_name = "test_collection"
# 创建collection,可理解为mongo的collection
collection_param = {
'collection_name': collection_name,
'dimension': vec_dim,
'index_file_size': 32,
'metric_type': MetricType.IP # 使用内积作为度量值
}
milvus.create_collection(collection_param)
# 随机生成一批向量数据
# 支持ndarray,也支持list
vectors_array = np.random.rand(num_vec, vec_dim)
# 把向量添加到刚才建立的collection中
status, ids = milvus.insert(collection_name=collection_name, records=vectors_array) # 返回 状态和这一组向量的ID
milvus.flush([collection_name])
# 输出统计信息
print(milvus.get_collection_stats(collection_name))
# 创建查询向量
query_vec_array = np.random.rand(1, vec_dim)
# 进行查询,
status, results = milvus.search(collection_name=collection_name, query_records=query_vec_array, top_k=5)
print(status)
print(results)
# 如果不用可以删掉
status = milvus.drop_collection(collection_name)
# 断开、关闭连接
milvus.close()
这里也推荐下官方示例代码,写的很好,更加权威,可借鉴学习。
faiss安装及其使用教程
faiss的安装
faiss有三种安装方式:
1 源码编译安装
根据官方教程来。做好踩坑的准备,这个能写好多,我就不写了,遇到问题私聊我吧
2 conda 安装
最为简单,但是需要conda。
# CPU version only
conda install faiss-cpu -c pytorch
# GPU version
conda install faiss-gpu cudatoolkit=8.0 -c pytorch # For CUDA8
conda install faiss-gpu cudatoolkit=9.0 -c pytorch # For CUDA9
conda install faiss-gpu cudatoolkit=10.0 -c pytorch # For CUDA10
3 第三方预编译库
有热心网友自己预编译了,可以直接pip install,私人编译,非官方,稳定性和成功率不保证,我自己用过没啥问题,详见https://pypi.org/project/faiss/
最后的最后,血和泪的教训,环境一定要安装openblas,注意不是blas,是openblas,那不然多核利用率会变得极差
faiss的使用
就像使用milvus一样,同样提供一份范例代码加以详细的注释,如有错误还请指正!
# 导入库
import numpy as np
import faiss
# 向量个数
num_vec = 5000
# 向量维度
vec_dim = 768
# 搜索topk
topk = 10
# 随机生成一批向量数据
vectors = np.random.rand(num_vec, vec_dim)
# 创建索引
faiss_index = faiss.IndexFlatL2(vec_dim) # 使用欧式距离作为度量
# 添加数据
faiss_index.add(vectors)
# 查询向量 假设有5个
query_vectors = np.random.rand(5, vec_dim)
# 搜索结果
# 分别是 每条记录对应topk的距离和索引
# ndarray类型 。shape:len(query_vectors)*topk
res_distance, res_index = faiss_index.search(query_vectors, topk)
print(res_index)
print(res_distance)
代码是为了抛砖引玉,大概介绍使用流程,高阶用法可以去看官网wiki。
最后感谢各位阅读, 希望能帮到你们.
文章可以转载, 但请注明出处:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号