【探索】无形验证码 —— PoW 算力验证
先来思考一个问题:如何写一个能消耗对方时间的程序?
消耗时间还不简单,休眠一下就可以了:
Sleep(1000)
这确实消耗了时间,但并没有消耗 CPU。如果对方开了变速齿轮,这瞬间就能完成。
不过要消耗 CPU 也不难,写一个大循环就可以了:
for i = 0 to 1000000000
end
但这和 Sleep 并无本质区别。对方究竟有没有运行,我们从何得知?
所以,我们需要一个返回结果 —— 只有完整运行才有正确答案。
result = 0
for i = 0 to 1000000000
result = result + i
end
return result
通过返回结果,我们就能校验,对方是否完整运行了我们的程序。
不过上面这个问题,毕竟还是 too simple。小学生都知道,用数列公式就可以直接算出结果,根本不用花时间去跑循环。
有什么函数,是无法用公式推测的?也就是说,必须老老实实运行函数,才能得出结果。而找不到一种更快的算法,也能算出相同的结果。
显然「单向散列函数」就是。例如,一个经典的问题:
MD5(X) == X
就无法用公式来解决了。要找出答案,只能一个个试过去,需要大量的时间。
但对于验证者,是非常轻松的 —— 只需将收到的答案,计算一次就可判断对错。
Hashcash
当然,上面的那个例子太困难了,一时间根本找不到答案。但可以做一些改进,例如只要求结果前几位是 0 就可以:
Hash(X) == "0000......"
这样 0 的数量越少,满足条件的 X 就越容易找到。
同时,为了防止答案重复使用,还可以再增加一个盐值:
Hash(X, Salt) == "0000......"
盐可以由验证者提供,这样就可以充当一个「问题」。符合条件的 X,则可以当做问题的「答案」,提交给验证者鉴定。
这就是所谓的 PoW(Proof-of-Work),一种鉴定对方是否投入计算工作的机制。并且只需花费少量的资源,即可鉴定大量的工作。
使用散列函数实现的 PoW,就叫做 Hashcash。现实中比特币使用了类似的原理,它使用了 SHA-256 作为散列函数。有权威的密码学算法作为保障,因此只能暴力穷举,而无法使用投机取巧的方法获得结果,保障了挖矿工作的价值。
传统应用
当然,Hashcash 早不是新鲜事,很久以前就用在反垃圾邮件中。
例如,用户写完邮件时,客户端将「收件地址 + 邮件内容」作为 Salt,然后计算符合条件的答案:
Hash(X, Salt) == "000000..."
最后将找到的 X 附加在邮件中并发送。
服务端收到后,即可鉴定发送这封邮件,是否花费了计算工作。
对于正常用户来说,额外的几秒计算并不影响使用;但对于制造垃圾邮件的人,就大幅增加了成本。
传统的限制策略,大多通过 IP、账号,攻击者可以用大量的马甲和代理,来绕过这些限制;而使用了 PoW,就把瓶颈限制在硬件上 —— 计算有多快,操作才能多快。
Web 应用
同样,Hashcash 也能用于 Web。例如论坛,增加机器发帖的计算成本。
在发帖时,计算:
Hash(X, 帖子内容) == "000000..."
提交时,带上额外的参数 X。
后端即可判断,用户发这条帖子,是否付出了计算工作。
Web 改进
然而,网页不同于客户端。
例如写邮件的例子:
邮件写完后,客户端可以隐藏在后台自动计算,然后再发送。但网页就大不相同了。如果发帖时,网页卡上好几秒,将大幅降低用户体验。
因此,不能像邮件那样,拿「帖子内容」、「标题」等这些用户输入的内容来计算。而是选择一个始终固定的参数。
例如,可以参考传统验证码的方式:
# 后端 - 生成随机问题
ques = rand()
session["pow_ques"] = ques
echo(ques)
在页面初始化时,后端生成一个随机数,并下发到前端。
前端使用这个随机数作为盐值 —— 这样页面打开时,就可以开始计算了。
# 前端 - 挖矿
while Hash(X, ques) != "000000..."
X = X + 1
end
我们选择一个适中的难度,例如 10 秒。通过多线程,还可以更快的完成计算任务,同时不影响用户体验。
正常情况下,用户发帖前已完成计算。提交时,将答案 X 带上。
如果提交时答案还未算出,则等待计算完成。。。(发帖太快,有灌水嫌疑)
# 前端 - 提交
wait X
submit(..., X)
# 后端 - 校验
if hash(X, session["pow_ques"]) == "000000..."
ok
else
fail
end
这样,一个「测试机器算力」的验证码实现了。
目前也有不少 hashcash 的实际应用。例如 WordPress 的 hashcash 插件。甚至还有第三方的验证服务 hashcash.io。
Web 性能
当然在 Web 中使用,性能也是一大问题。如果 10 秒的脚本计算,用本地程序只需 1 秒,那攻击者就可以使用本地版的外挂了。
好在如今有 asm.js,可接近原生性能,让用户的劳动不至于贬值;对于较老的浏览器,也可以使用 Flash 作后补。在上一篇文章 0x08 节 中已详细讲解。
如果算力实在不够,也可以使用后备方案 —— 传统图形验证码。
这样,高性能用户可享受更好的体验,低性能用户也能保障基本功能。
这也算是鼓励大家使用现代浏览器吧:)
Hashcash 缺陷
不过,语言上的性能差距还是有限的,外挂不会纠结于此,而是使用更强力的武器 —— GPU。
Hashcash 的本质就是跑 hash,这是 GPU 最擅长的。例如著名的 oclHashcat,和 CPU 完全不在一个数量级。
对抗硬件的并行计算,大致有如下方案和思路:
-
硬件瓶颈
-
移植难度
-
CPU 算法
-
以暴制暴
-
自创加密
-
串行模式
前 3 个在上一篇文章 0x09 节 提到了,下面讨论一些不同的。
以暴制暴
如果我们也能在 Web 中调用显卡计算,那 GPU 版的外挂就毫无优势了。
不过,这个想法似乎有些遥远。尽管目前主流浏览器都支持 WebGL,但都只局限于渲染加速上,并未提供通用计算接口。
当然,也可以通过一些 hack 的方式,例如曾有人尝试用 WebGL 挖比特币,但效率并不高。
如果未来 WebCL 成为标准,或许还能考虑。
自创加密
不要自创加密算法 —— 这似乎是一条真理。
在账号安全里,这固然正确。但在对抗的场合下,就未必如此了。
经典的加密算法固然权威,但研究的人也多,破解的工具也多。
自创的算法,虽然在密码学上很弱,但可以把逻辑实现的很长很复杂,并且加以混淆,就可以在「隐蔽性」上占优势了。
这样,要将其移植到 GPU 上,就困难了。
同时还可以制作模板,定期变幻代码。在攻击者破解之前,逻辑又变化了。
在对抗中,随机应变的弱算法,显然比一成不变的强算法更好。
串行模式
Hashcash 的原理,决定了它是可以并行计算的。有什么样的算法,是无法并行计算的?
如果每次计算都依赖上次结果,就无法并行了。例如 slowhash:
function slowhash(x)
for i = 0 to 1000000000
x = hash(x)
end
return x
end
这种串行的计算,自然是无法拆分的。
但这能用到 PoW 上吗?显然不行!
因为 PoW 虽然计算困难,但得 容易鉴定。而这种方式,鉴定时也得重复算一遍,成本太大了。
但发挥一下想象:如果能够设计得当,这还是可以尝试的 —— 我们可以使用 UGC 的模式,让用户来贡献算力!
首先,需要一个访问量较大的网站,在其中悄悄放置一个脚本:
# 隐蔽的脚本
Q = rand()
A = slowhash(Q)
submit(Q, A)
我们利用在线的用户,来生成问题和答案!!
当然,这项工作必须足够隐蔽,防止被好奇的用户发现,提交错误的答案。
当后端题库有一定的积累时,就可以使用验证码的模式了。
用户访问时,后端从题库中抽取一个问题,安排给前端计算:
# 后端 - 分配问题
Q = select_key_from_db()
session["pow_ques"] = Q
# 前端 - 计算问题
A = slowhash(Q)
用户提交时,后端无需任何计算,直接通过查表,判断答案是否正确:
# 前端 - 提交
submit(..., A)
# 后端 - 鉴定
Q = session["pow_ques"]
if A == db[Q]
ok
else
fail
end
使用预先计算的方式,避免了耗时的鉴定工作。同时,把让用户来出题,可大幅节省硬件成本。
回顾之前的 hashcash,因为散列结果是不确定的,题解时间有一定的随机性。
但 slowhash 这种方式,只是重复执行散列函数 N 次,所以解题的时间更固定。
演示
出于简单,这里演示一个 hashcash-md5 版的:
https://github.com/EtherDream/proof-of-work-hashcash
如果想看算力速度,可以查看这里:
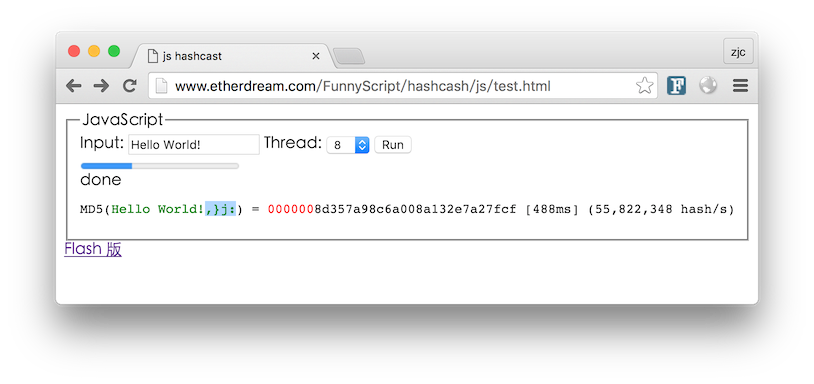
看起来好像不慢,不过对比 GPU 的速度 就相形见绌了。
所以 hashcash 如果使用经典算法,简直就是不堪一击的。或许自己写的「隐蔽式加密」算法,反而更能对抗一些。
至于 slowhash 那种串行模式的 PoW,涉及到较多策略和数据积累,本文就不演示了,下回再讨论。
(2017/03/01 补充)现在 WebGL2 出来了,着色器支持整数以及位运算,因此非常适合 PoW 计算:

Demo:https://www.etherdream.com/FunnyScript/glminer/glminer.html
用我的笔记本核显,每秒都能计算 2700 万次 SHA256 算法。换成好点的显卡例如泰坦,每秒可以 5 亿以上的 hash 计算~ (注意 SHA256 比 MD5 慢多了)
总结
最后来对比下,算力验证和传统图形验证的区别。
| 验证方式 | 验证对象 | 用户体验 | 拦截假人 | 实际意义 | |
|---|---|---|---|---|---|
| 传统验证 | 图像识别 | 人脑 | 有交互 | 部分拦截 | 杜绝假人 |
| 算力验证 | 问题解答 | 电脑 | 无感知 | 无法拦截 | 减少滥用 |
论效果,当然还是传统验证码更好;论体验,计算对于用户是透明的,无需任何交互。
简单来说,传统验证码是防止机器「不能使用」;而 PoW 防止的则是「不能滥用」。
当然上述提到发帖那个案例,并不恰当。即使用上 PoW,限制每 5 秒发一帖,那么一分钟仍有 12 贴 —— 这速度显然还是有点太快。更适合 PoW 的场合,应该类似找回密码、或者接收短信等功能,比较容易在短时间内被大量滥用,用于增加攻击者刷接口的成本。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号