数据采集与融合第二次作业
 爬爬爬爬
爬爬爬爬
第二次作业
作业①:
要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
1)Weather Forecast
代码:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import sqlite3
class weatherDB:
def openDB(self):
self.con = sqlite3.connect("weather.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute(
"create table weathers (wid varchar(16),wcity varchar(16),wdate varchar(16),wweather varchar(64),wtemp varchar(32),constraint pk_weather primary key(wcity,wdate))")
except:
self.cursor.execute("delete from weathers")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, id, city, date, weather, temp):
try:
self.cursor.execute("insert into weathers (wid,wcity,wdate,wweather,wtemp) values(?,?,?,?,?)",
(id, city, date, weather, temp))
except Exception as e:
print(e)
def show(self):
self.cursor.execute("select * from weathers")
rows = self.cursor.fetchall()
# 绘制表格
print("%-16s%-16s%-32s%-16s" % ("city", "data", "weather", "temp"))
for row in rows:
print("%-16s%-16s%-32s%-16s" % (row[0], row[1], row[2], row[3]))
class weatherforecast():
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/85.0.4183.121 Safari/537.36"}
self.citycode = {"北京": "101010100", "上海": "101020100", "杭州": "101210101", "深圳": "101280601"}
def forecastcity(self, city):
if city not in self.citycode.keys():
print(city + "code not found")
return
url = "http://www.weather.com.cn/weather/" + self.citycode[city] + ".shtml"
id = 1
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, 'html.parser')
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
date_ = li.select('h1')[0].text
weather_ = li.select('p[class="wea"]')[0].text
temp_ = li.select('p[class="tem"] span')[0].text + "/" + li.select("p[class='tem'] i")[0].text
self.db.insert(id, city, date_, weather_, temp_)
id += 1
except Exception as e:
print(e)
except Exception as e:
print(e)
def precess(self, cities):
self.db = weatherDB()
self.db.openDB()
for city in cities:
self.forecastcity(city)
self.db.show()
self.db.closeDB()
ws = weatherforecast()
ws.precess(["北京", '上海', '杭州', '深圳'])
print('finish')
爬取结果(只能说这个排名对福大并不是很友好):
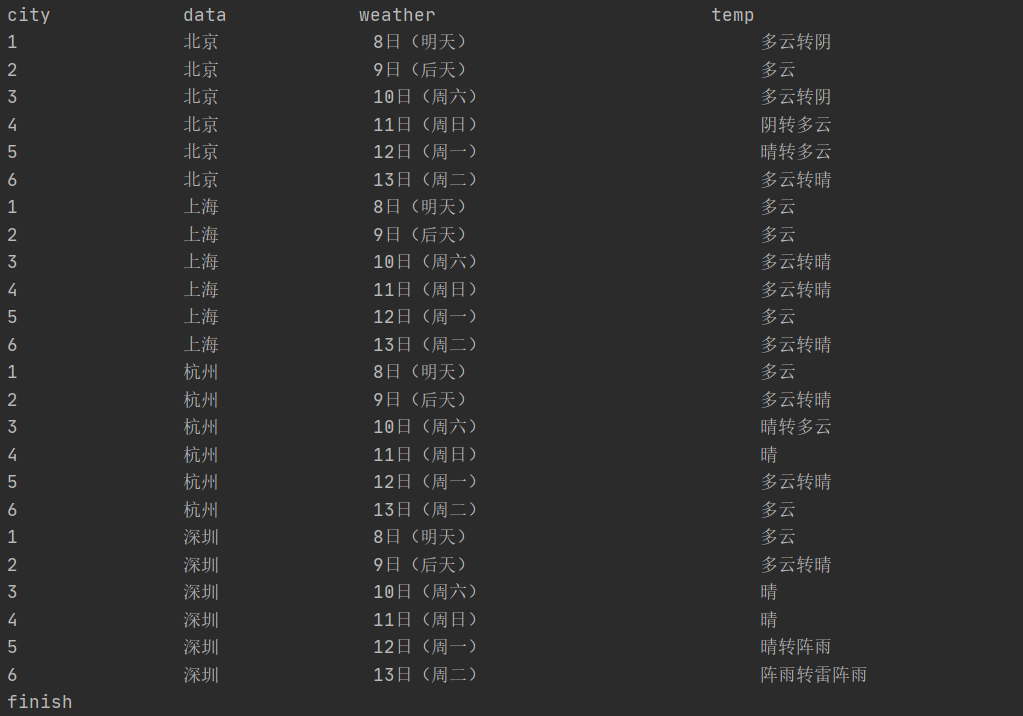
2)心得体会:
这份作业只是把书上的代码进行复现了一下,也第一次使用了数据库进行数据存处
作业②
-
要求:用requests和BeautifulSoup库方法定向爬取股票相关信息。
-
候选网站:东方财富网:https://www.eastmoney.com/
1)Stock Price
代码:
import prettytable as pt
import requests
import re
import pandas as pd
import time
import os
import xlwt
hearders = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36"
}
#用get方法访问服务器并提取页面数据
def getHtml(cmd):
url = "http://nufm.dfcfw.com/EM_Finance2014NumericApplication/JS.aspx?"\
"cb=jQuery112406115645482397511_1542356447436&type=CT"\
"&token=4f1862fc3b5e77c150a2b985b12db0fd&sty=FCOIATC"\
"&js""=(%7Bdata%3A%5B(x)%5D%2CrecordsFiltered%3A(tot)%7D)"\
"&cmd={cmd}&st=" \
"(ChangePercent)&sr=-1&p=1&ps=500&_={time_stamp}"
#下面的这个url用于作业③
#url = "http://push2.eastmoney.com/api/qt/stock/get?ut=fa5fd1943c7b386f172d6893dbfba10b&invt=2&fltt=2&fields=f44,f45,f46,f57,f58&secid={id}&cb=jQuery1124005936661807716215_1601615953071&_=={time_stamp}"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36"
}
time_stamp = int(round(time.time() * 1000)) # 获取时间戳
r = requests.get(url.format(cmd=cmd, time_stamp=time_stamp), headers=headers)
return r.content.decode()
#获取单个页面股票数据
def getOnePageStock(cmd):
data = getHtml(cmd)
colums = ['代码', '名称', '最新价格', '涨跌额', '涨跌幅', '成交量', '成交额', '振幅', '最高', '最低','今开', '昨收', '今开']
if(data!=[]):
datas = data.split('["')[1].split('"]')[0].split('","')
items = []
for i in range(len(datas)):
# 创建字典
item = dict(zip(colums, datas[i].split(',')[1:13]))
#x.add_row([i,datas[i].split(',')[1],datas[i].split(',')[2],datas[i].split(',')[3],datas[i].split(',')[4],datas[i].split(',')[5],datas[i].split(',')[6],datas[i].split(',')[7],datas[i].split(',')[8],datas[i].split(',')[9],datas[i].split(',')[10],datas[i].split(',')[11],datas[i].split(',')[12],datas[i].split(',')[13]])
items.append(item)
return items
else:
return []
#用于爬取指定代码的股票
def getMyStock(num):
data = getHtml(num)
if (data != []):
datas = re.findall(r"{\"f.*\"}", data)
item = eval(datas[0])
return item
else:
return []
def main():
cmd = {
"上证指数":"C.1",
"深圳指数":"C.5",
"沪深A股":"C._A",
"上证A股":"C.2",
"深圳A股":"C._SZAME",
"新股":"C.BK05011",
"中小板":"C.13",
"创业板":"C.80"
}
if not os.path.exists("Stock"):
os.makedirs("Stock")
for i in cmd.keys():
items = getOnePageStock(cmd[i])
# 返回一个字典列表,一个dict是一行数据。
df = pd.DataFrame(items)
try:
fp=open("Stock/"+i+".xls", "w")
df.to_excel("Stock/"+i+".xls")
except Exception as e:
print(e)
finally:
fp.close()
print("已保存"+i+".xls")
#print(x)
#def Get_My_Stock(num):
my_stock = getMyStock(num)
x = pt.PrettyTable()
x.field_names = ["股票代码", "股票名称", "今日开", "今日最高", "今日最低"]
try:
x.add_row([my_stock['f57'], my_stock['f58'], my_stock['f46'], my_stock['f44'], my_stock['f45']])
print(x)
except:
print("未找到股票!")
main()
#num = "0.123030"
#Get_My_Stock(num)
结果:
深圳A股的数据展示

2)实验心得:
这次是先用老师给的知乎专栏的代码进行复现,但是还是遇到了不少问题。比较重要的一点是要找到对应的js文件,找了半天。
作业③
根据自选3位数+学号后3位(123030)选取股票,获取印股票信息。抓包方法同作②。
1)GetMyStock
代码:
import prettytable as pt
import requests
import re
import pandas as pd
import time
import os
import xlwt
hearders = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36"
}
#用get方法访问服务器并提取页面数据
def getHtml(num):
#url = "http://nufm.dfcfw.com/EM_Finance2014NumericApplication/JS.aspx?"\
#"cb=jQuery112406115645482397511_1542356447436&type=CT"\
#"&token=4f1862fc3b5e77c150a2b985b12db0fd&sty=FCOIATC"\
#"&js""=(%7Bdata%3A%5B(x)%5D%2CrecordsFiltered%3A(tot)%7D)"\
#"&cmd={cmd}&st=" \
#"(ChangePercent)&sr=-1&p=1&ps=500&_={time_stamp}"
url = "http://push2.eastmoney.com/api/qt/stock/get?ut=fa5fd1943c7b386f172d6893dbfba10b&invt=2&fltt=2&fields=f44,f45,f46,f57,f58&secid={num}&cb=jQuery1124005936661807716215_1601615953071&_=={time_stamp}"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36"
}
time_stamp = int(round(time.time() * 1000)) # 获取时间戳
r = requests.get(url.format(num=num, time_stamp=time_stamp), headers=headers)
return r.content.decode()
def getItems(num):
data = getHtml(num)
if (data != []):
datas = re.findall(r"{\"f.*\"}", data)
item = eval(datas[0])
return item
else:
return []
def Get_My_Stock(num):
my_stock = getItems(num)
x = pt.PrettyTable()
x.field_names = ["股票代码", "股票名称", "今日开", "今日最高", "今日最低"]
try:
x.add_row([my_stock['f57'], my_stock['f58'], my_stock['f46'], my_stock['f44'], my_stock['f45']])
print(x)
except:
print("未找到股票!")
num = "0.123030"
Get_My_Stock(num)
结果:
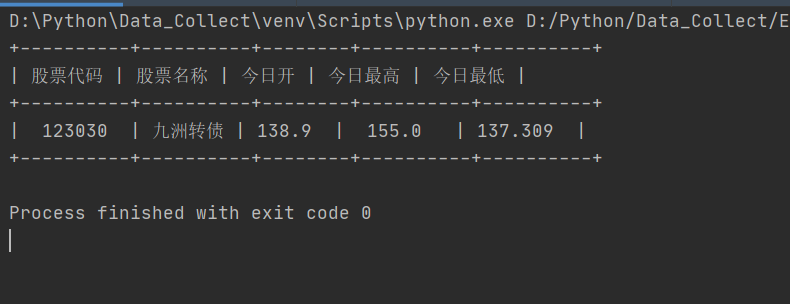
2)实验心得
这个和上一个作业类似,改变一些参数就可以了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号