搜狐新闻文本分类与分析
【实验目的】
- 掌握数据预处理的方法,对训练集数据进行预处理;
- 掌握文本建模的方法,对语料库的文档进行建模;
- 掌握分类算法的原理,基于有监督的机器学习方法,训练文本分类器;
- 利用学习的文本分类器,对未知文本进行分类判别;
- 掌握评价分类器性能的评估方法。
【实验要求】
- 文本类别数:>=10类;
- 训练集文档数:>=500000篇;每类平均50000篇。
- 测试集文档数:>=500000篇;每类平均50000篇()
【实验内容】
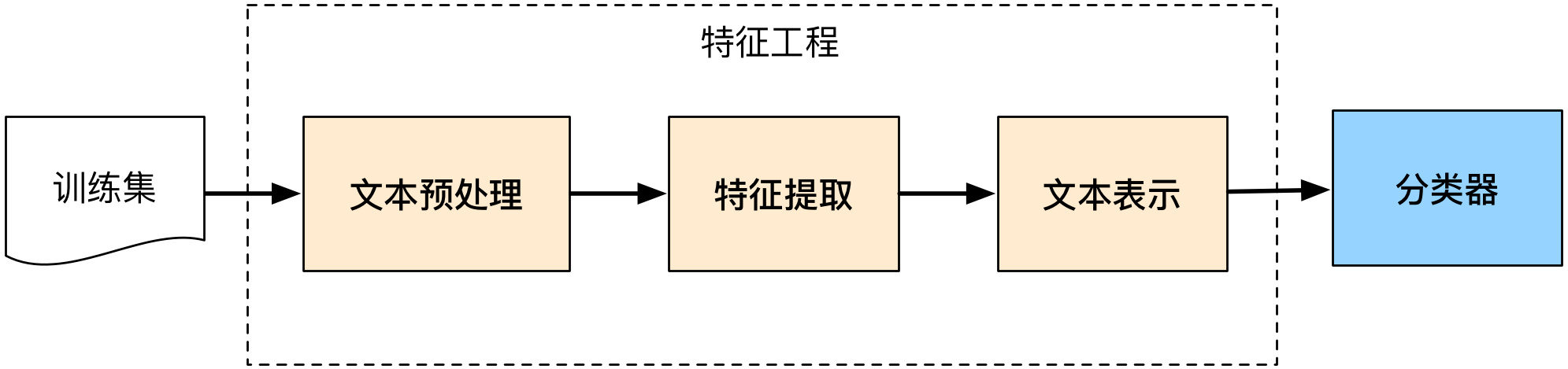
1.训练集获取
本次实验采用搜狗新闻语料库(http://www.sogou.com/labs/resource/list_news.php),本次实验使用的使搜狐新闻数据,历史完整版下载下来解压缩为3.3GB。下载完成后解压缩如图:
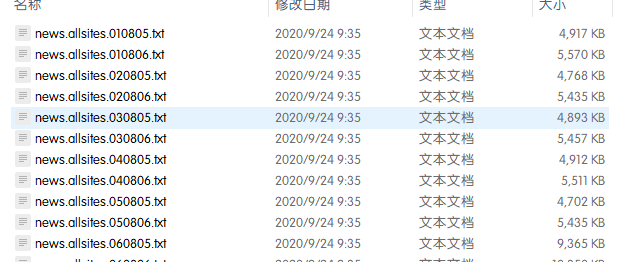
2.文本预处理
上图中每个文档大致内容如下:
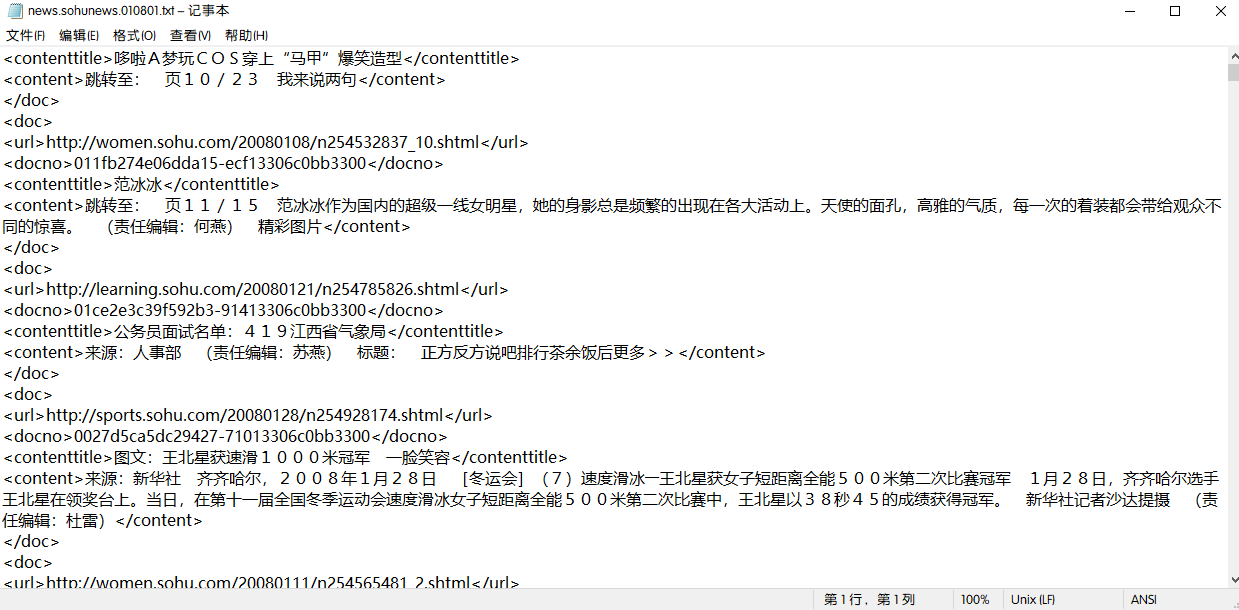
可以看到文件含有大量多余信息,文本预处理的目的是提取其中的文本并存入对应分类的文件夹中,这里确定分类标签的依据是 < url>标签中的字段,例如< url>http://sports.sohu.com/20080128/n254928174.shtml< /url>,则其文本对应的标签为sports。另外,需要注意原始文本为ANSI编码,在执行提取文本操作前应该转换其编码为UTF-8,否则后续执行会出错。下面贴上转换编码以及提取文本的python代码:
# -*- coding:UTF-8 -*- #转换编码
import os
import codecs
import chardet
def list_folders_files(path):
"""
返回 "文件夹" 和 "文件" 名字
:param path: "文件夹"和"文件"所在的路径
:return: (list_folders, list_files)
:list_folders: 文件夹
:list_files: 文件
"""
list_files = []
for root, dirs, files in os.walk(path):
for file in files:
list_files.append(path+'\\'+file)
return list_files
def convert(file, in_enc = "ANSI", out_enc = "utf-8"):
in_enc = in_enc.upper()
out_enc = out_enc.upper()
try:
print("convert [ " + file.split('\\')[-1] + " ].....From " + in_enc + " --> " + out_enc)
f = codecs.open(file, 'r', in_enc, "ignore")
new_content = f.read()
codecs.open(file, 'w', out_enc).write(new_content)
except IOError as err:
print("I/O error: {0}".format(err))
path = 'C:\Users\iloveacm\pytorch\sohu\sougou_all\SogouCS'
lists = list_folders_files(path)
for list in lists:
convert(list, 'GB2312', 'UTF-8')
import os
from xml.dom import minidom
from urlparse import urlparse
import codecs
import importlib
import sys
import re
import io
default_encoding = 'utf-8'
reload(sys)
sys.setdefaultencoding(default_encoding)
file_dir = 'C:\Users\iloveacm\pytorch\sohu\sougou_after2'
""" for root, dirs, files in os.walk('C:\Users\iloveacm\pytorch\sohu\sougou_before2'):
for f in files:
print(f)
print(f)
tmp_dir = 'C:\Users\iloveacm\pytorch\sohu\sougou_after2' + '\\' + f
text_init_dir = file_dir + '\\' + f
print text_init_dir
file_source = open(text_init_dir, 'r')
ok_file = open(tmp_dir, 'w')
ok_file.close() """
main_config = 'C:\Users\iloveacm\pytorch\sohu\sougou_after2'
for root, dirs, files in os.walk('C:\Users\iloveacm\pytorch\sohu\sougou_after2'):
for file in files:
text = open(main_config +'\\' + file, 'rb').read().decode("UTF-8")
content = re.findall('<url>(.*?)</url>.*?<contenttitle>(.*?)</contenttitle>.*?<content>(.*?)</content>', text, re.S)
for news in content:
url_title = news[0]
content_title = news[1]
news_text = news[2]
title = re.findall('http://(.*?).sohu.com', url_title)[0]
if len(title)>0 and len(news_text)>30:
print('[{}][{}][{}]'.format(file, title, content_title))
save_config = main_config + '\\' + title
if not os.path.exists(save_config):
os.makedirs(save_config)
else:
print('Is Exists')
f = open('{}/{}.txt'.format(save_config, (len(os.listdir(save_config)) + 1)), 'w')
f.write(news_text)
f.close()
转换后目录结构如下:
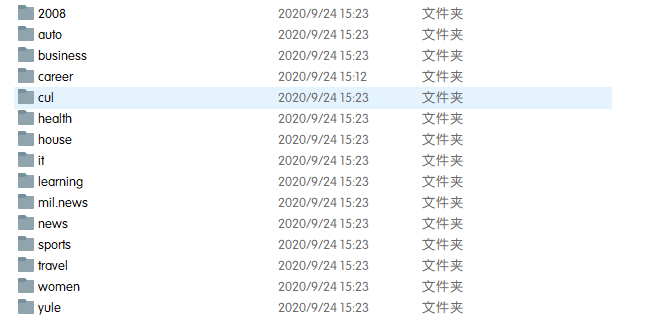

其中每个文件夹包含代表一个类,共18类。每个txt文档包含一则新闻消息。至此预处理完毕。
2.数据清洗与特征提取
查看数据特征
为了符合短文本分类的特性,用以下代码查看以数据集下各个文本在长度上的分类。
import os #此段代码依次读取各个文本分类文件夹中txt文档,获取长度后存入lists中
import numpy as np #lists[i],其中i表示文本长度,lists[i]的值表示文本长度为i的文本个数
import matplotlib.pyplot as plt
lists = [0]
lists = lists*20001
def EnumPathFiles(path, callback):
if not os.path.isdir(path):
print('Error:"',path,'" is not a directory or does not exist.')
return
list_dirs = os.walk(path)
for root, dirs, files in list_dirs:
for d in dirs:
print(d)
EnumPathFiles(os.path.join(root, d), callback)
for f in files:
callback(root, f)
def callback1(path, filename):
textpath = path+'\\'+filename
print(textpath)
text = open(textpath,'rb').read()
length = len(text)/3
if length <= 20000:
lists[length]+=1
if __name__ == '__main__':
EnumPathFiles(r'C:\\Users\\iloveacm\\pytorch\\sohu\\sougou_all', callback1)
m = np.array(lists)
np.save('demo.npy',m)
a=np.load('demo.npy')
graphTable=a.tolist()
print(graphTable)
根据上面得到的数组画图,结果如下
# -*- coding:UTF-8 -*-
import os
import numpy as np
import matplotlib.pyplot as plt
a=np.load('demo.npy')
graphTable=a.tolist()
#print(graphTable)
plt.plot(graphTable)
plt.ylabel('the number of texts') #x轴代表文本的长度,y轴代表文本长度为x的文本数量
plt.xlabel('the length of text')
plt.axis([0,3000,0,3000])
plt.show()
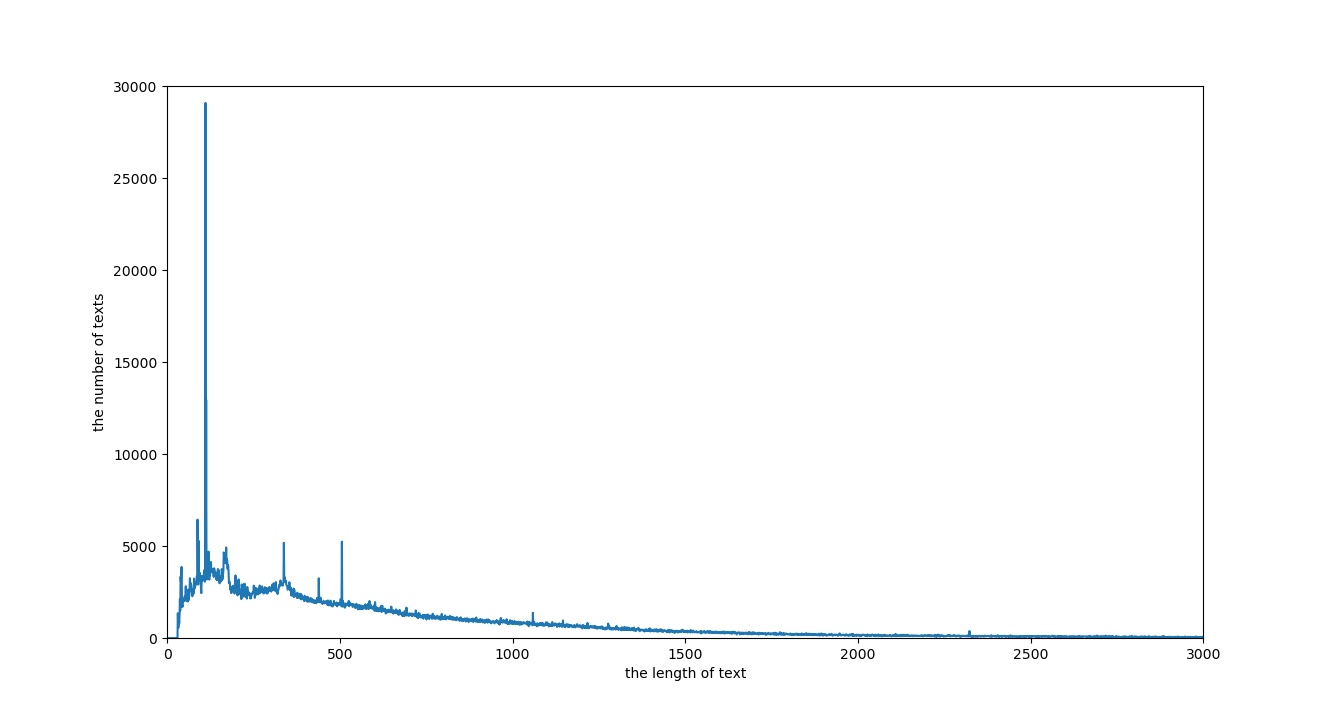
可以看到,绝大部分文档长度集中在小于等于500的长度范围内。
分词
本文采用结巴分词,分词的同时去除一次些中文停用词,即一些没有意义的词语,如:即,而已,等等。与此同时,去除标点符号,标点符号包含在停用词列表中。这是本实验采用的停用词列表。下面是处理停用词代码
#encoding=utf-8 #遍历文件,用ProsessofWords处理文件
import jieba
import os
import numpy as np
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
def EnumPathFiles(path, callback, stop_words_list):
if not os.path.isdir(path):
print('Error:"',path,'" is not a directory or does not exist.')
return
list_dirs = os.walk(path)
for root, dirs, files in list_dirs:
for d in dirs:
print(d)
EnumPathFiles(os.path.join(root, d), callback, stop_words_list)
for f in files:
callback(root, f, stop_words_list)
def ProsessofWords(textpath, stop_words_list):
f = open(textpath,'r')
text = f.read()
f.close()
result = list()
outstr = ''
seg_list = jieba.cut(text,cut_all=False)
for word in seg_list:
if word not in stop_words_list:
if word != '\t':
outstr += word
outstr += " "
f = open(textpath,'w+')
f.write(outstr)
f.close()
def callback1(path, filename, stop_words_list):
textpath = path+'\\'+filename
print(textpath)
ProsessofWords(textpath, stop_words_list)
if __name__ == '__main__':
stopwords_file = "C:\Users\iloveacm\pytorch\sohu\\stop_words2.txt"
stop_f = open(stopwords_file, "r")
stop_words = list()
for line in stop_f.readlines():
line = line.strip()
if not len(line):
continue
stop_words.append(line)
stop_f.close()
print(len(stop_words))
EnumPathFiles(r'C:\\Users\\iloveacm\\pytorch\sohu\sougou_all', callback1, stop_words)
结果示例如下

为了能够适应keras的读取数据格式,用以下代码整理并为每条数据打上标签。最后得到以下结果文件:
(1)新闻文本数据,每行 1 条新闻,每条新闻由若干个词组成,词之间以空格隔开,总共428993行,并且做了截断处理,只选取了前大约1000个汉字;
(2)新闻标签数据,每行 1 个数字,对应这条新闻所属的类别编号,训练标签428993行;
新闻标签如下
dict = {'2008': '1', 'business':'2', 'hourse': '3', 'it': '4', 'learning':'5', 'news':'6', 'sports':'7', 'travel':'8', 'women':'9', 'yule':'10'}
处理代码如下
#encoding=utf-8
import os
def merge_file(path):
files = os.listdir(path)
print(files)
dict = {'2008': '1', 'business':'2', 'hourse': '3', 'it': '4', 'learning':'5', 'news':'6', 'sports':'7', 'travel':'8', 'women':'9', 'yule':'10'}
outfile_train = 'C:\\Users\\iloveacm\\pytorch\\sohu\\train.txt'
outfile_label = 'C:\\Users\\iloveacm\\pytorch\\sohu\\label.txt'
result_train = open(outfile_train, 'a')
result_label = open(outfile_label, 'a')
for file in files:
text_dir = path + '\\' + file
texts = os.listdir(text_dir)
for text in texts:
txt_file_dir = text_dir + '\\' + text
print(txt_file_dir)
f= open(txt_file_dir,'r')
content = f.read()
if len(content) > 3000:
content = content.decode('utf8')[0:3000].encode('utf8') #截取字段
result_train.write(content+'\n') #合并文件
result_label.write(dict[file]+'\n')
result_label.close()
result_train.close()
if __name__=="__main__":
path = r"C:\\Users\\iloveacm\\pytorch\\sohu\\sougou_all"
merge_file(path)
至此,数据预处理,数据清洗以及数据集准备阶段完毕。
3.分类算法
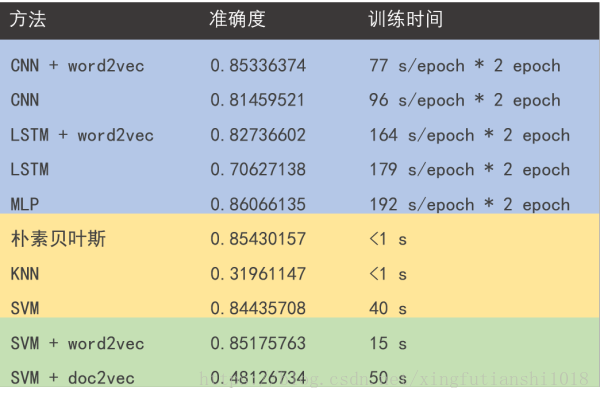
本实验机器学习算法的选择参考这篇文章(搜狐新闻文本分类:机器学习大乱斗),下图是文章给出的各个算法的比较:
CNN模型:
模型代码以及模型示意图如下:
跑起来发现验证集准确率异常低,仔细一想是因为数据集是按种类分割,所以验证集上的种类未被训练过。
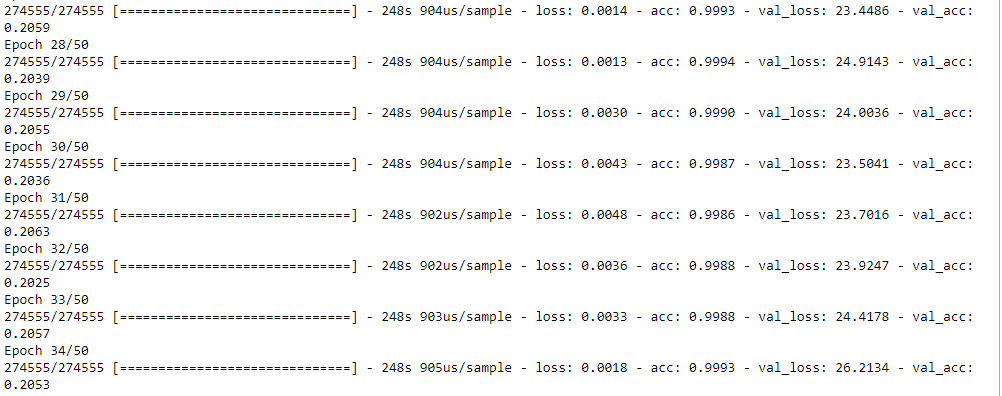
对模型进行改正后结果如下:
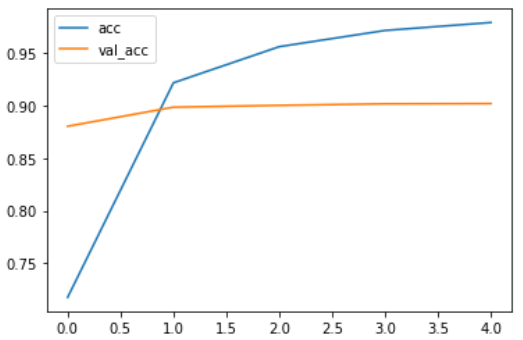
训练集上准确率0.9792,验证集准确率0.9020,训练集损失0.0596,验证集损失0.3829,用时22分钟,
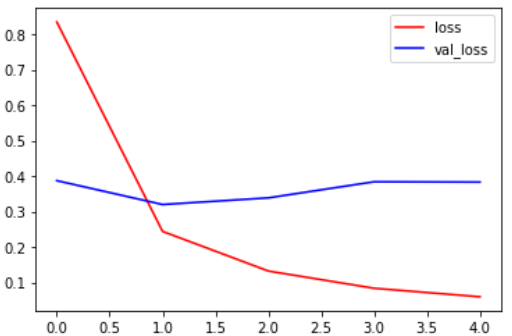
CNN_WORD2VEC:
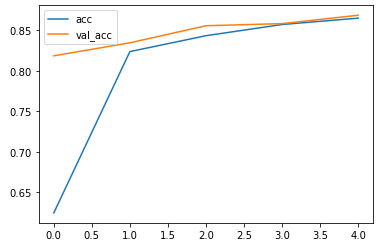
训练集上准确率达到了0.8648,验证集上达到了0.8683,训练集损失0.4064,验证集损失0.3978,用时8.75分钟
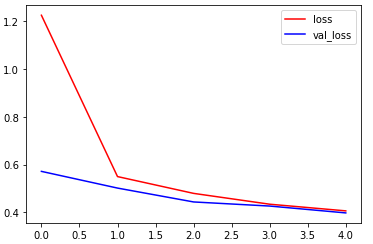
LSTM:
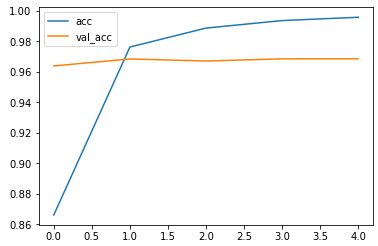
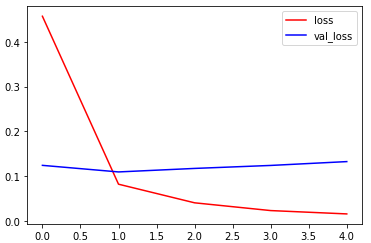
训练集上准确率达到了0.9957,验证集上达到了0.9684,训练集损失0.0158,验证集损失0.1326,用时32.7分钟
LSTM_W2V:
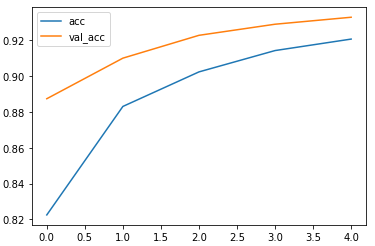
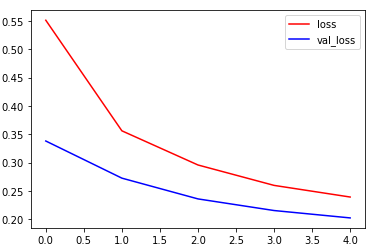
训练集上准确率达到了0.9206,验证集上达到了0.9327,训练集损失0.2390,验证集损失0.2021,用时21.3分钟
从上面四个例子可以看到,用了词向量模型节省了时间但是准确率反而有所下降。
MLP:
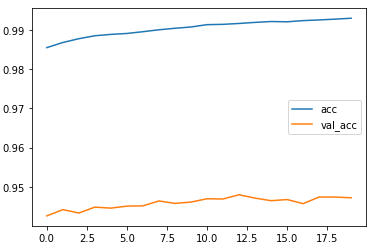
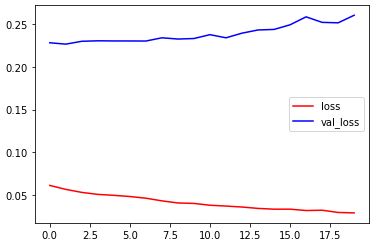
训练集上准确率0.9930,验证集准确率0.9472,训练集损失0.0287,验证集损失0.2608,用时22分钟
MLP这里由于内存不足,将Tokenizer(num_words)中num_words设置为5000,即取前5000个词作为训练目标。
对比表格如下
| 数据集准确率 | 验证集准确率 | 训练集损失 | 验证集损失 | 时间花费 | |
|---|---|---|---|---|---|
| CNN | 0.9792 | 0.9020 | 0.0596 | 0.3829 | 22分钟 |
| CNN_W2V | 0.8648 | 0.8683 | 0.4064 | 0.3978 | 8.75分钟 |
| LSTM | 0.9957 | 0.9684 | 0.0158 | 0.1326 | 32.7分钟 |
| LSTM_W2V | 0.9206 | 0.9327 | 0.2390 | 0.2021 | 21.3分钟 |
| MLP | 0.9930 | 0.9472 | 0.0287 | 0.2608 | 5分钟(20) |
其中MLP训练较快,大约15秒一个epoch,所以训练了20个epoch

 浙公网安备 33010602011771号
浙公网安备 33010602011771号