Flink系列(0)——准备篇(流处理基础)
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams.
Apache Flink是一个分布式、有状态的流计算引擎。
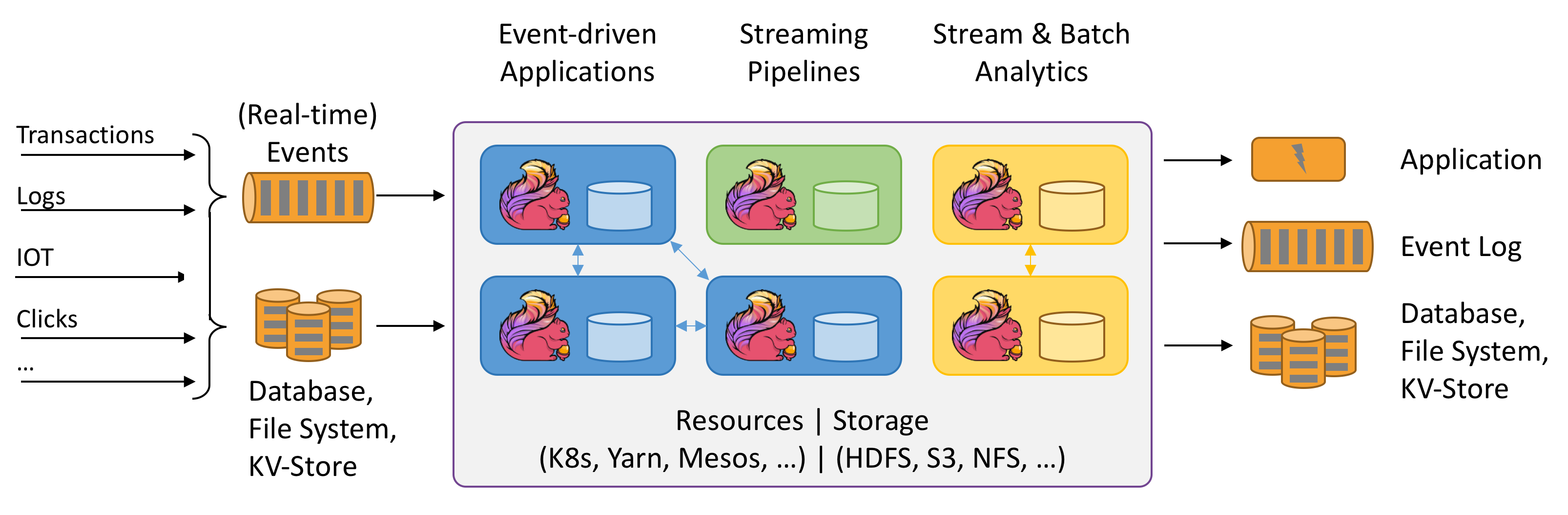
下面将正式开启Flink系列的学习笔记与总结。(https://flink.apache.org/)。此篇是准备篇,主要介绍流处理相关的基础概念。别小看这些理论,对后续的学习与理解很有帮助哦。
下面很多词汇来自flink官方:https://ci.apache.org/projects/flink/flink-docs-release-1.11/concepts/glossary.html
什么是数据流
An event is a statement about a change of the state of the domain modelled by the application. Events can be input and/or output of a stream or batch processing application.
Any kind of data is produced as a stream of events. Credit card transactions, sensor measurements, machine logs, or user interactions on a website or mobile application, all of these data are generated as a stream.
数据流:是一个可能无限的事件序列。这里的事件可以是实时监控数据、传感器测量值、转账交易、物流信息、电商网购下单、用户在界面上的操作等等。
流又可分为无界流和有界流。如下图所示:
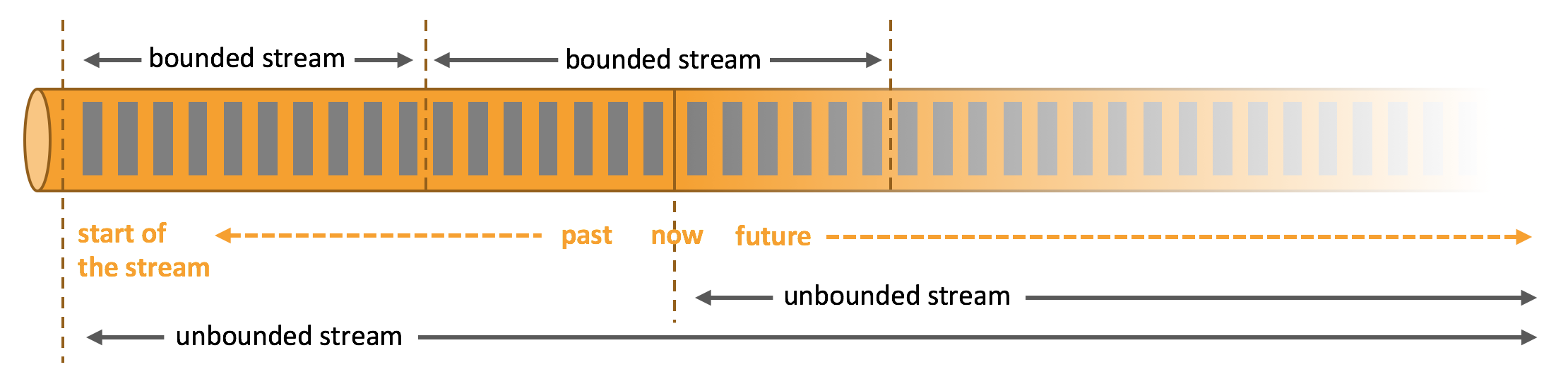
-
Unbounded streamshave a start but no defined end. They do not terminate and provide data as it is generated. -
Bounded streamshave a defined start and end. Bounded streams can be processed by ingesting all data before performing any computations
数据流上的操作
流处理引擎通常会提供一系列操作来实现数据流的获取(Source)、转换(Transformation)、输出(Sink)。
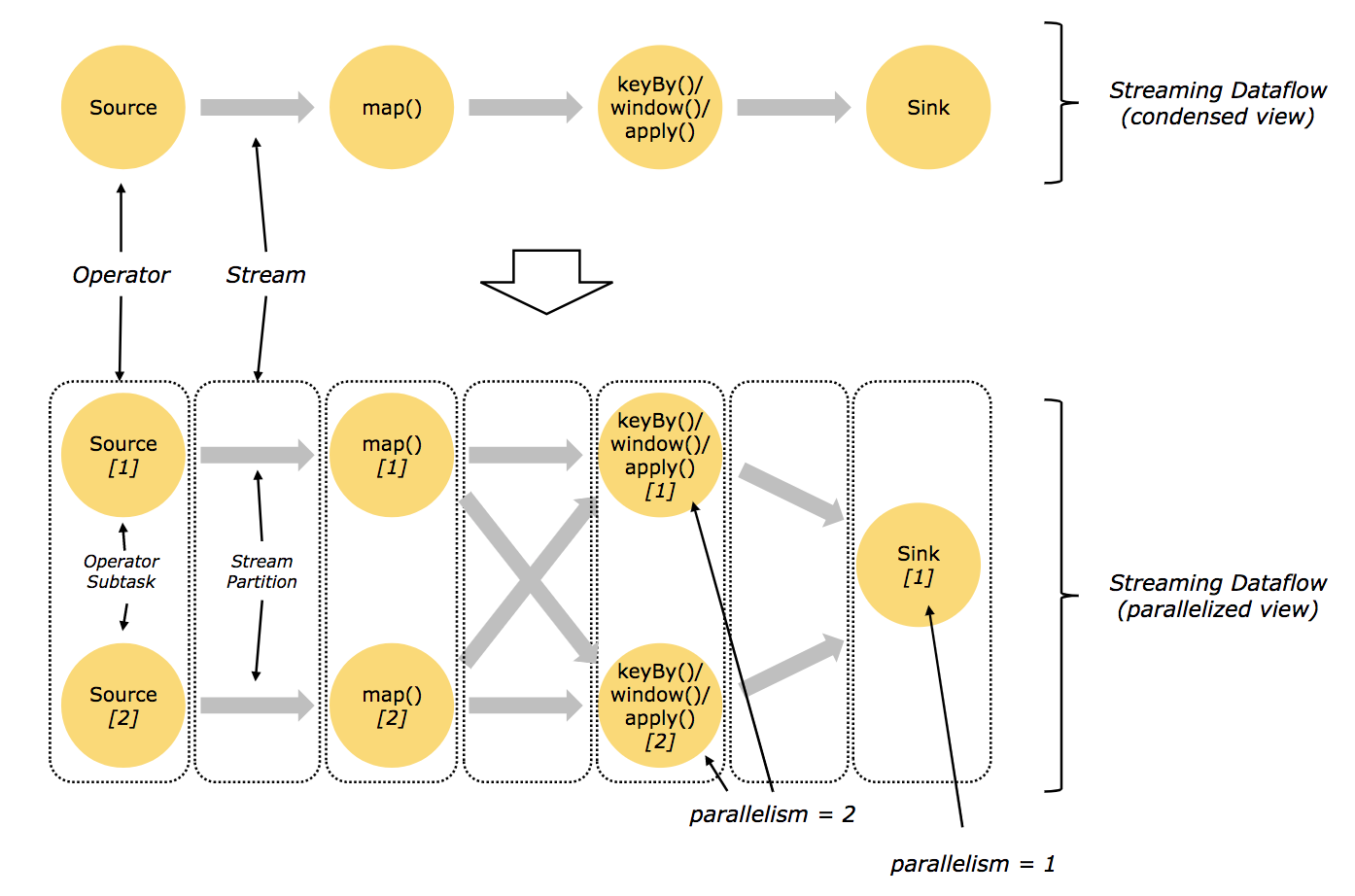
借用flink官方1.10版本的图https://ci.apache.org/projects/flink/flink-docs-release-1.10/concepts/programming-model.html,如下:
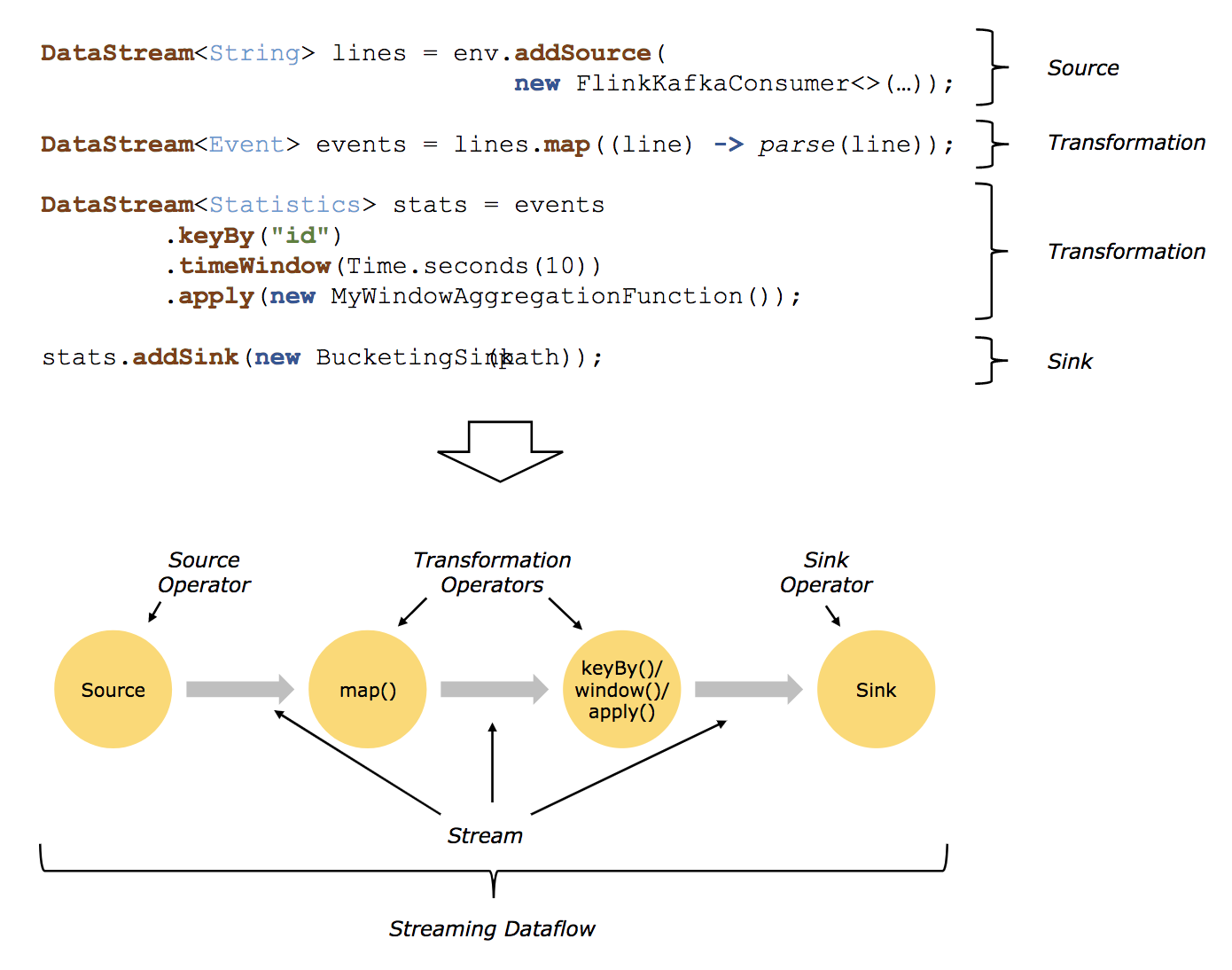
A
logical graphis a directed graph where the nodes are Operators and the edges define input/output-relationships of the operators and correspond to data streams or data sets. A logical graph is created by submitting jobs from a Flink Application.Logical graphsare also often referred to asdataflow graphs.
Operator: Node of a Logical Graph. An Operator performs a certain operation, which is usually executed by a Function. Sources and Sinks are special Operators for data ingestion and data egress.
dataflow图:描述了数据如何在不同的操作之间流动。dataflow图通常为有向图。图中节点称为算子(也常称为操作),表示计算;边表示数据依赖关系,算子从输入获取数据,对其进行计算,然后产生数据并发往输出以供后续处理。没有输入端的算子称为source,没有输出端的算子称为sink。一个dataflow图至少要有一个source和一个sink。
dataflow图被称作逻辑图(logical graph),因为仅仅表达的是计算逻辑,实际分布式处理时,每个算子可能会在不同机器上运行多个并行计算。
Source、Sink、Transformation
Sources are where your program reads its input from.
Data sinks consume DataStreams and forward them to files, sockets, external systems, or print them.
数据接入(Source)和数据输出(Sink)操作允许流处理引擎和外部系统进行通信。数据接入操作是从外部数据源获取原始数据并将其转换成适合流处理引擎后续处理的格式。实现数据接入操作逻辑的算子称为Source,可以来自socket、文件、kafka等。数据输出操作是将流处理引擎中的数据以适合外部存储格式输出,负责数据输出的算子称为Sink,可以写入文件、数据库、kafka等。
A Transformation is applied on one or more data streams or data sets and results in one or more output data streams or data sets. A transformation might change a data stream or data set on a per-record basis, but might also only change its partitioning or perform an aggregation.
在数据接入与数据输出中间,往往有大量的转换操作(Transformation)。转换操作会分别处理每个事件。这些操作逐个读取事件,对其应用某些转换并产生一条新的输出流。算子既可以同时接收多个输入流或产出多条输出流,也可以进行单流分割、多流合并等。
有状态怎么理解
在数据流上的操作可以是无状态的(stateless),也可以是有状态的(stateful),无状态的操作不会维持内部状态,即处理事件时无需依赖已处理过的事件,也不保存历史事件。由于事件处理互不影响而且与事件到来的时间无关,无状态的操作很容易并行化。此外,如果发生故障,无状态的算子可以很容易地重启并恢复工作。相反,有状态的算子可能需要维护之前接收到的事件信息,它们的状态会根据新来的事件更新,并用于未来事件的处理逻辑中。有状态的流处理应用在并行化和容错方面会更具挑战性。
有状态算子同时使用传入的事件和内部状态来计算输出。由于流式算子处理的都是潜在无穷无尽的数据,所以必须小心避免内部状态无限增长。为了限制状态大小,算子通常都会只保留到目前为止所见事件的摘要或概览。这种摘要可能是一个数量值,一个累加值,一个对至今为止全部事件的抽样,一个窗口缓冲或是一个保留了应用运行过程中某些有价值信息的自定义数据结构。
不难想象,支持有状态算子会面临很多实现上的挑战。有状态算子需要保证状态可以恢复,并且即使出现故障也要确保结果正确。
至多一次(At Most Once)
它表示每个事件至多被处理一次。
任务发生故障时最简单的措施就是既不恢复丢失的状态,也不重放丢失的事件。换句话说,事件可以随意丢弃,不保证结果的正确性。
至少一次(At Least Once)
它表示所有事件最终都会被处理,虽然有些可能会处理多次。
对大多数应用而言,用户期望是不丢事件。如果最终结果的正确性仅依赖信息的完整度,那重复处理或者可以接受。例如,确认某个事件是否出现过,就可以用至少一次保证正确的结果。它最坏的结果也无非就是重复判断了几次。但如果要计算某个事件出现的次数,至少一次可能就会返回错误的结果。
为了确保至少一次语义的正确性,需要想办法从源头或者缓冲区中重放事件。持久化事件日志会将所有事件写入永久存储,这样在任务故障时就可以重放它们。实现该功能的另一个方法是采用记录确认(ack)。将所有事件存在缓冲区中,直到处理管道中所有任务都确认某个事件已经处理完毕才会将事件丢弃。
精确一次(Exactly Once)
它表示不但没有事件丢失,而且每个事件对于内部状态的更新都只有一次。
精确一次是最严格,也是最难实现的一类保障。本质上,精确一次语义意味着应用总会提供正确的结果,就如同故障从未发生过一样。
精确一次同样需要事件重放机制。此外,流处理引擎需要确保内部状态的一致性,即在故障恢复后,计算引擎需要知道某个事件对应的更新是否已经反映到状态上。事务性更新是实现该目标的一个方法,但它可能会带来极大的性能开销。Flink采用了轻量级检查点机制(Checkpoint)来实现精确一次的结果保障。(flink系列后续会有文章重点分析,这里先知道有这么一回事即可。)
上面提到的“结果保障”,指的都是流处理引擎内部状态的一致性。也就是说,我们关注故障恢复后应用代码能够看到的状态值。请注意,保证应用状态的一致性和保证输出的一致性并不是一回事。一旦数据从Sink中写出,除非目标系统支持事务,否则最终结果的正确性难以保证。
窗口操作
官方有篇关于窗口介绍的博客:https://flink.apache.org/news/2015/12/04/Introducing-windows.html
windows相关的文档:https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/stream/operators/windows.html#windows
Windowsare at the heart of processing infinite streams. Windows split the stream into “buckets” of finite size, over which we can apply computations.
转换操作(Transformation)可能每处理一个事件就产生结果并(可能)更新状态。然而,有些操作必须收集并缓冲记录才能计算结果,例如流式Join或者求中位数的聚合(Aggregation)。为了在无界数据流上高效地执行这些操作,必须对操作所维持的数据量加以限制。下面将讨论支持该项功能的窗口操作。
此外,有了窗口操作,就能在数据流上完成一些具有实际语义价值的计算。比如说,最近几分钟某路口的车流量、某路口每10分钟的车流量等。
窗口操作会持续创建一些称为桶的有限事件集合,并允许我们基于这些有限集进行计算。事件通常会根据其时间或其他数据属性分配到不同桶中。为了准确定义窗口算子语义,我们需要决定事件如何分配到桶中以及窗口用怎样的频率产生结果。窗口的行为是由一系列策略定义的,这些窗口策略决定了什么时间创建桶,事件如何分配到桶中以及桶内数据什么时间参与计算。其中参与计算的决策会根据触发条件判定,当触发条件满足时,桶内数据会发送给一个计算函数,由它来对桶内的元素应用计算逻辑。这些计算函数可以是某些聚合(例如计数(count)、求和(sum)、最大值(max)、最小值(min)、平均值(avg)等),也可以是自定义操作。策略的指定可以基于时间(例如“最近5秒钟接收的事件”)、数量(例如“最新100个事件”)或其他数据属性。
接下来就重点介绍几种常见的窗口语义。
滚动窗口
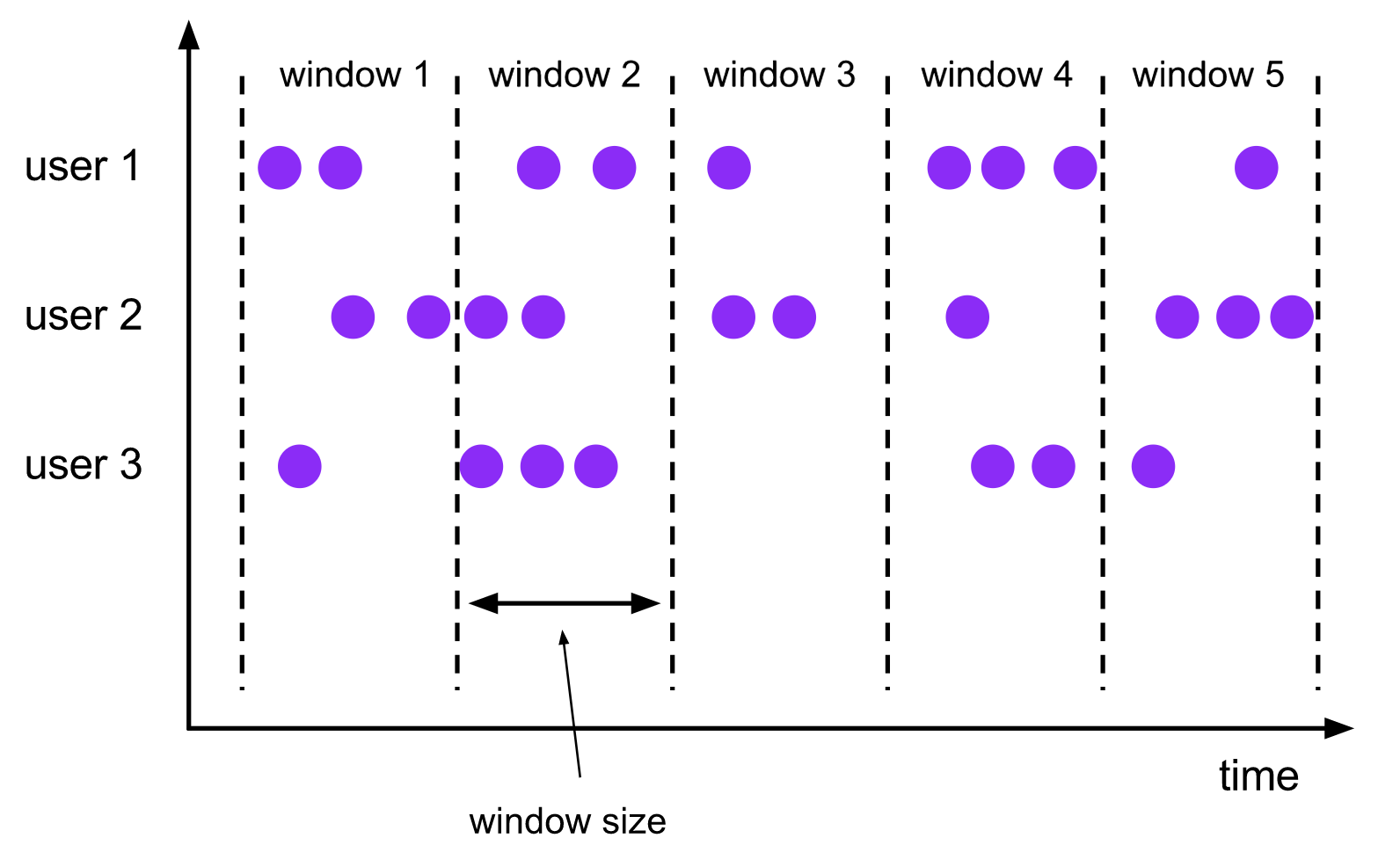
A
tumbling windowsassigner assigns each element to a window of a specified window size. Tumbling windows have a fixed size and do not overlap. For example, if you specify a tumbling window with a size of 5 minutes, the current window will be evaluated and a new window will be started every five minutes as illustrated by the following figure.
滚动窗口将事件分配到长度固定且互不重叠的桶中。
- 基于数量的(
count-based)滚动窗口定义了在触发计算前需要集齐多少条事件; - 基于时间的(
time-based)滚动窗口定义了在桶中缓冲事件的时间间隔。如上图所示,基于时间间隔的滚动窗口将事件汇集到桶中,每隔一段时间(window size)触发一次计算。
滑动窗口
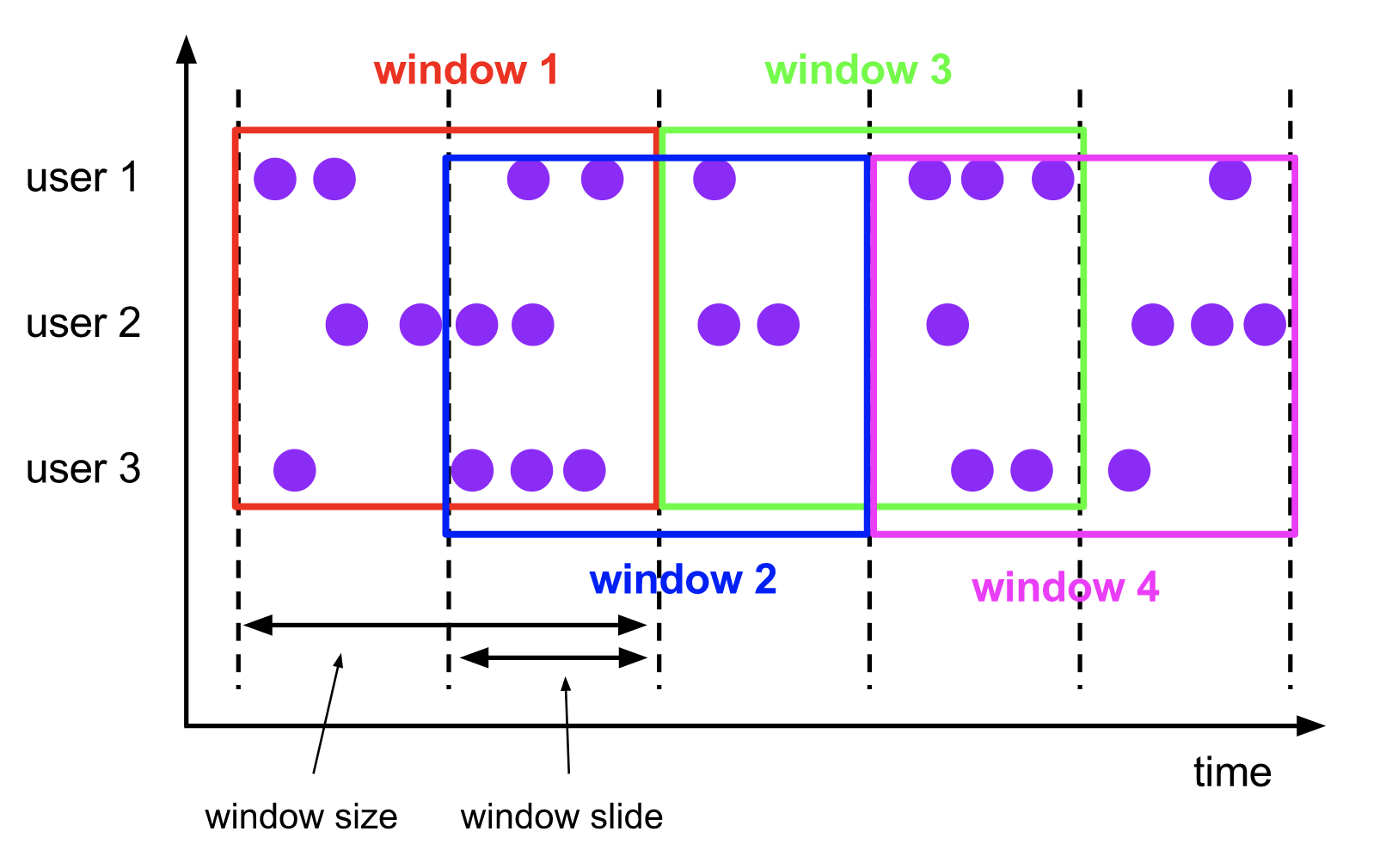
The
sliding windowsassigner assigns elements to windows of fixed length. Similar to a tumbling windows assigner, the size of the windows is configured by the window size parameter. An additional window slide parameter controls how frequently a sliding window is started. Hence, sliding windows can be overlapping if the slide is smaller than the window size. In this case elements are assigned to multiple windows.
滑动窗口将事件分配到大小固定且允许相互重叠的桶中,这意味着每个事件可能会同时属于多个桶。
For example, you could have windows of size 10 minutes that slides by 5 minutes. With this you get every 5 minutes a window that contains the events that arrived during the last 10 minutes as depicted by the following figure.
我们通过指定长度(size)和滑动间隔(slide)来定义滑动窗口。滑动间隔决定每隔多久生成一个新的桶。举个例子,SlidingTimeWindows(size = 10min, slide = 5min)表示的语义是每隔5分钟统计一次最近10分钟的数据。
会话窗口
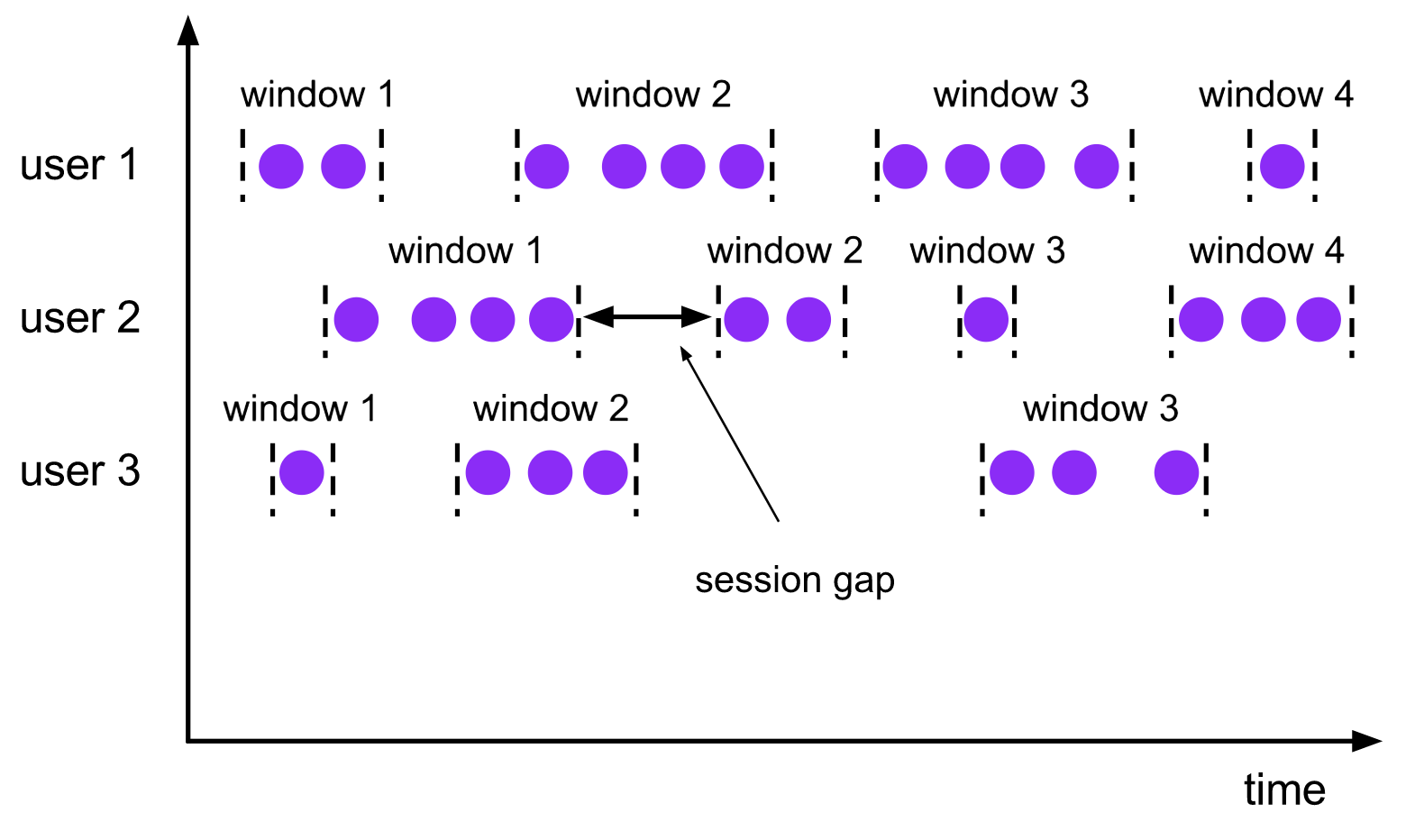
The
session windowsassigner groups elements by sessions of activity. Session windows do not overlap and do not have a fixed start and end time, in contrast to tumbling windows and sliding windows. Instead a session window closes when it does not receive elements for a certain period of time, i.e., when a gap of inactivity occurred. A session window assigner can be configured with either a static session gap or with a session gap extractor function which defines how long the period of inactivity is. When this period expires, the current session closes and subsequent elements are assigned to a new session window.
会话窗口在一些实际场景中非常有用,这些场景既不适合用滚动窗口也不适合用滑动窗口。比如说,有一个应用要在线分析用户行为,在该应用中我们要把事件按照用户的同一活动或者会话来源进行分组。会话由发生在相邻时间内的一系列事件外加一段非活动时间组成。具体来说,用户浏览一连串新闻文章的交互过程可以看做是一个会话。由于会话长度并非预先定义好,而是和实际数据有关,所以无论是滚动还是滑动窗口都无法适用该场景。而我们需要一个窗口操作,能将属于同一会话的事件分配到相同桶中。会话窗口根据会话间隔(session gap)将事件分为不同的会话,该间隔值定义了会话在关闭前的非活动时间长度。
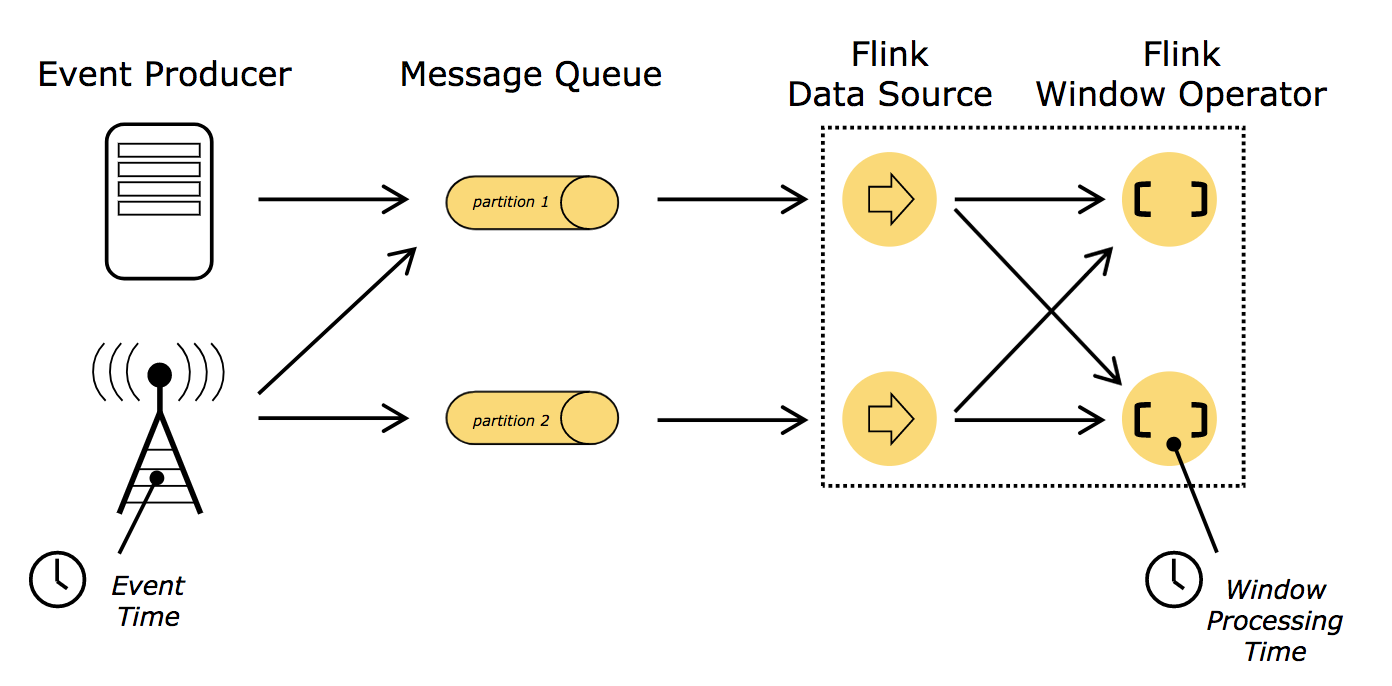
时间语义
相关文档:https://ci.apache.org/projects/flink/flink-docs-release-1.11/concepts/timely-stream-processing.html
上面介绍的几种窗口类型都要在生成结果前缓冲数据,不难发现时间成了应用中较为核心的要素。举例来说,算子在计算时是应该依赖事件实际发生的时间还是应用处理事件的时间呢?这需要根据具体的应用场景来分析。
流式应用中有两个不同概念的时间,即处理时间(Processing time)和事件时间(Event time)。如下图所示:
处理时间
Processing time: Processing time refers to the system time of the machine that is executing the respective operation.
处理时间是当前流处理算子所在机器上的本地时钟时间。
基于处理时间的窗口会包含那些恰好在一段时间内到达窗口算子的事件,这里的时间段是按照机器上的本地时钟时间测量的。
基于处理时间的操作结果是不可预测的,计算结果是不确定的。当数据流的处理速度与预期速度不一致、事件到达算子的顺序混乱、本地时钟不正确,基于处理时间的窗口事件可能就会不一样。
事件时间
Event time: Event time is the time that each individual event occurred on its producing device. This time is typically embedded within the records before they enter Flink, and that event timestamp can be extracted from each record.
事件时间是数据流中事件实际发生的时间。它附加在事件自身,在进入流处理引擎(Flink)前就存在。
即便事件有延迟,依赖事件时间也能反映出真实发生的情况,从而能准确地将事件分配到对应的时间窗口。
基于事件时间的操作是可预测的,其结果具有确定性。无论数据流的处理速度如何、事件到达算子的顺序怎样,基于事件时间的窗口都会生成同样的结果。
使用事件时间要克服的挑战之一是如何处理延迟事件。不能因为来了事件时间为一年前的事件,一年前的时间窗口就一直不关闭等待迟到事件的到来。这样就引出了一个重要的问题:怎么决定事件时间窗口的触发时机?换言之,需要等待多久才能确定已经收到了所有发生在某个特定时间点之前的事件?
The mechanism in Flink to measure progress in event time is
watermarks. Watermarks flow as part of the data stream and carry a timestamp t. A Watermark(t) declares that event time has reached time t in that stream, meaning that there should be no more elements from the stream with a timestamp t’ <= t (i.e. events with timestamps older or equal to the watermark).
水位线(watermark)是一个全局进度指标,表示确信不会再有延迟事件到来的某个时间点。本质上,水位线提供了一个逻辑时钟,用来通知系统当前的事件时间。当一个算子接收到时间为t的水位线,就可以认为不会再收到任何时间戳小于或者等于t的事件了。
水位线允许我们在结果的准确性和延迟之间做出取舍。激进的水位线策略保证了低延迟,但随之而来的是低可信度。该情况下,延迟事件可能会在水位线之后到来,我们必须额外加一些代码来处理它们。反之,如果水位线过于保守,虽然可信度得以保证,但可能会无谓地增加了处理延迟。
实际应用中,系统可能难以获取足够多的信息来完美确定水位线。流处理引擎需提供某些机制来处理那些晚于水位线的迟到事件。根据具体需求的不同,可能直接忽略这些事件,可能将它们写入日志,或者利用它们修正之前的结果。
小结
既然事件时间能解决大多数问题,为何还要去关心处理时间呢?事实上,处理时间也有其适用的场景。处理时间窗口能够将延迟降至最低。由于无需考虑迟到或乱序的事件,窗口只需简单地缓冲事件,然后在达到特定时间后立即触发窗口计算即可。因此,对于那些更重视处理速度而非准确度的应用,处理时间就会派上用场。另一种场景是,你需要周期性地实时报告结果而无论其准确性如何。例如,你想观察数据流的接入情况,通过计算每秒大致的事件数来检测数据中断,就可以使用处理时间来进行窗口计算。
总而言之,虽然处理时间提供了较低的延迟,但它的结果依赖处理速度,具有不确定性。事件时间则与之相反,能保证结果的相对准确性,并允许你处理延迟或无序的事件。
如何评测流处理的性能
对于批处理应用而言,作业的总执行时间通常会作为性能评测的一个方面。但流式应用事件无限输入、程序持续运行,没有总执行时间的概念,所以常用延迟和吞吐来评测流式应用的性能。通常,我们希望系统低延迟、高吞吐。
延迟:表示处理一个事件所需的时间。即从接收事件至观察到事件处理效果的时间间隔。比如说,平均延迟为10毫秒,表示平均每条数据会在10毫秒内处理;95%延迟为10毫秒则表示95%的事件会在10毫秒内处理。保证低延迟对很多流式应用(告警系统、网络监测、诈骗识别、风险控制等)至关重要,从而滋生出所谓的实时应用。
吞吐:表示单位时间可以处理多少事件。可用来衡量系统的处理速度。但要注意,处理速度还取决于数据到来速度,因此,吞吐低不一定意味着系统性能差。在流处理应用中,通常希望系统有能力应对以最大速度到来的事件,即系统满负载时的性能上限(峰值吞吐)。实际生产中,一旦事件到达速度过高导致系统处理不过来,系统就会被迫开始缓冲事件。若此时系统吞吐已到极限,再提高事件到达速度只会让延迟更大。如果系统还继续以力不能及的高速度接收事件,那么缓冲区可能会用尽。这种情况通常被称为背压(backpressure),我们有多种可选策略来处理它。flink系列后续会有文章重点介绍这块。
参考资料
- [1] [Fabian Hueske & Vasiliki Kalavri 著,崔星灿 译;基于Apache Flink的流处理(Stream Processing with Apache Flink);中国电力出版社,2020]
- [2] Apache Flink Documentation v1.11


 浙公网安备 33010602011771号
浙公网安备 33010602011771号