17.ElasticSearch
介绍
Elasticsearch(以下简称 ES)是一个天生支持分布式的搜索、聚合分析和存储引擎。是一个基于 Java 语言开发的,基于 Lucene 的开源分布式搜索引擎。Elasticsearch 同时也是 Elastic 技术体系(Elastic Stack)中最核心的成员。
Elastic Stack 技术栈除了 ES 之外,还囊括了:
- Kibana:提供了功能强大的图形化工具。
- Logstash:动态数据收集管道
- Beats:轻量化数据采集器
“ELK”是三个开源项目的首字母缩写,这三个项目分别是:Elasticsearch、Logstash 和 Kibana。Elasticsearch 是一个搜索和分析引擎。Logstash 是服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到诸如 Elasticsearch 等“存储库”中。Kibana 则可以让用户在 Elasticsearch 中使用图形和图表对数据进行可视化。
Elasticsearch 是解决海量数据全文检索的不二之选!
特点
- 基于 Java 语言开发
- 基于 Lucene 框架
- 仅支持 Json 的数据格式
- 原生支持分布式
- 支持 PB 级数据量
- 跨语言
- 高性能、高可用、易扩展
- 开箱即用、上手简单
- 潜力巨大、可开发性强
- 开源、免费
下载安装
https://www.elastic.co/cn/downloads/past-releases#elasticsearch

windows
双击 bin 目录下的 elasticsearch.bat 文件
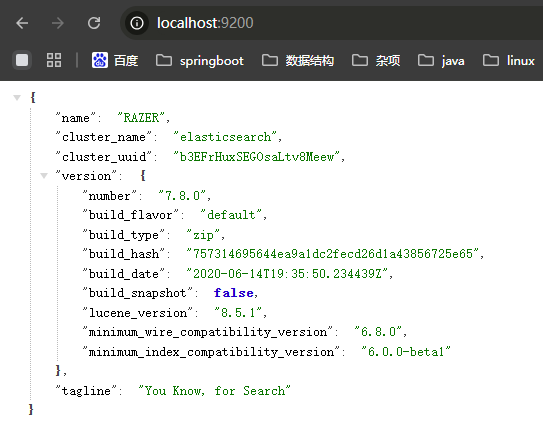
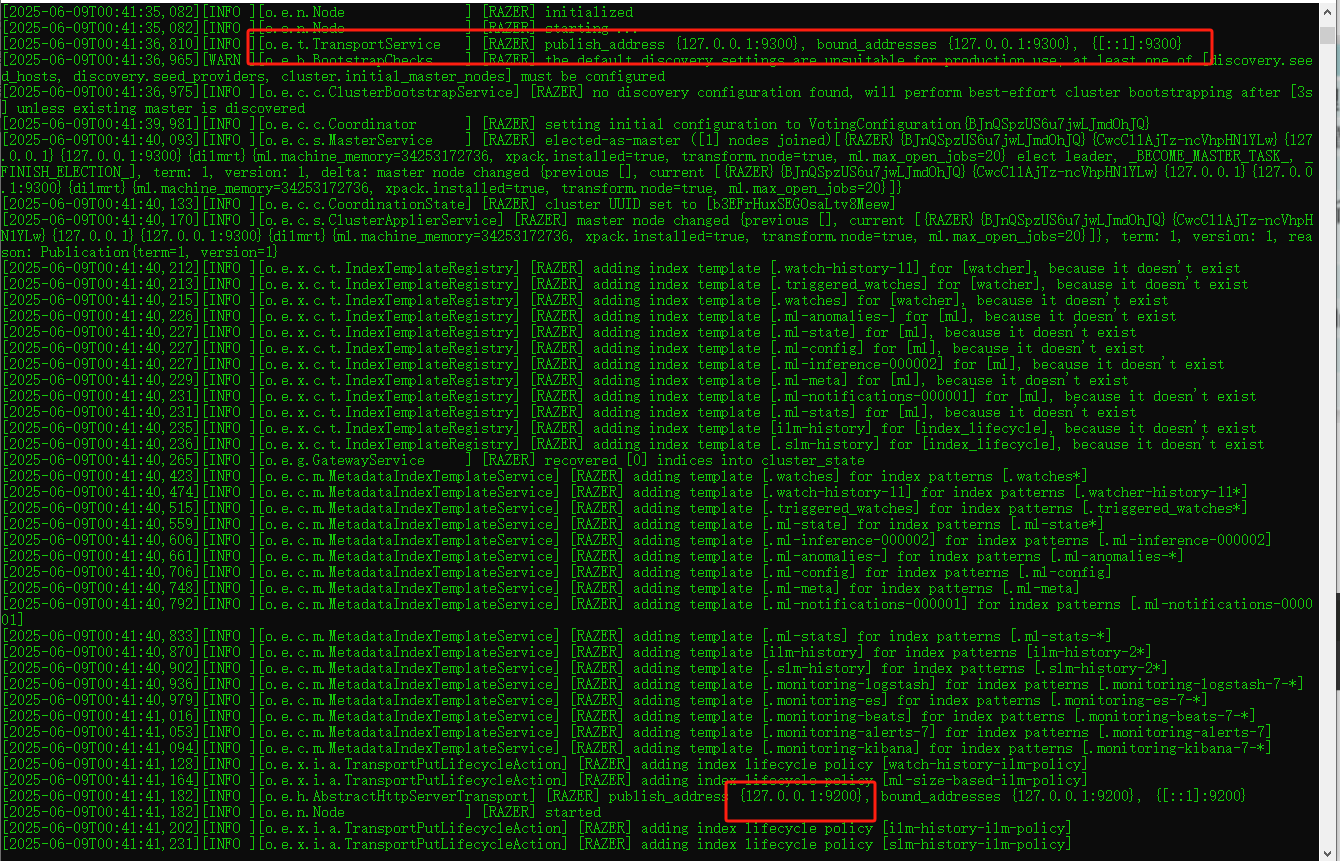
注意:9300端口为ES集群间组件的通信端口,9200端口为浏览器访问的http协议RESTful端口
数据格式
ES是面相文档型数据库,一条数据在这里就是一个文档,类比MySQL
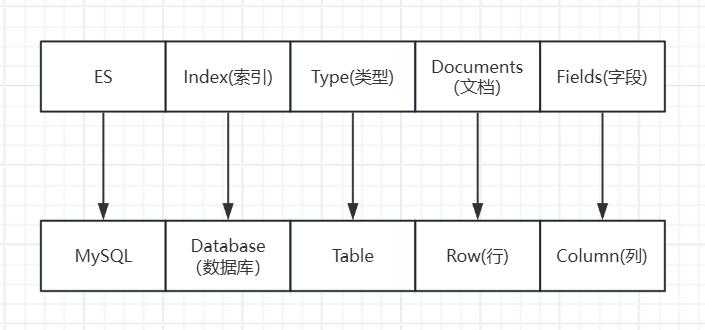
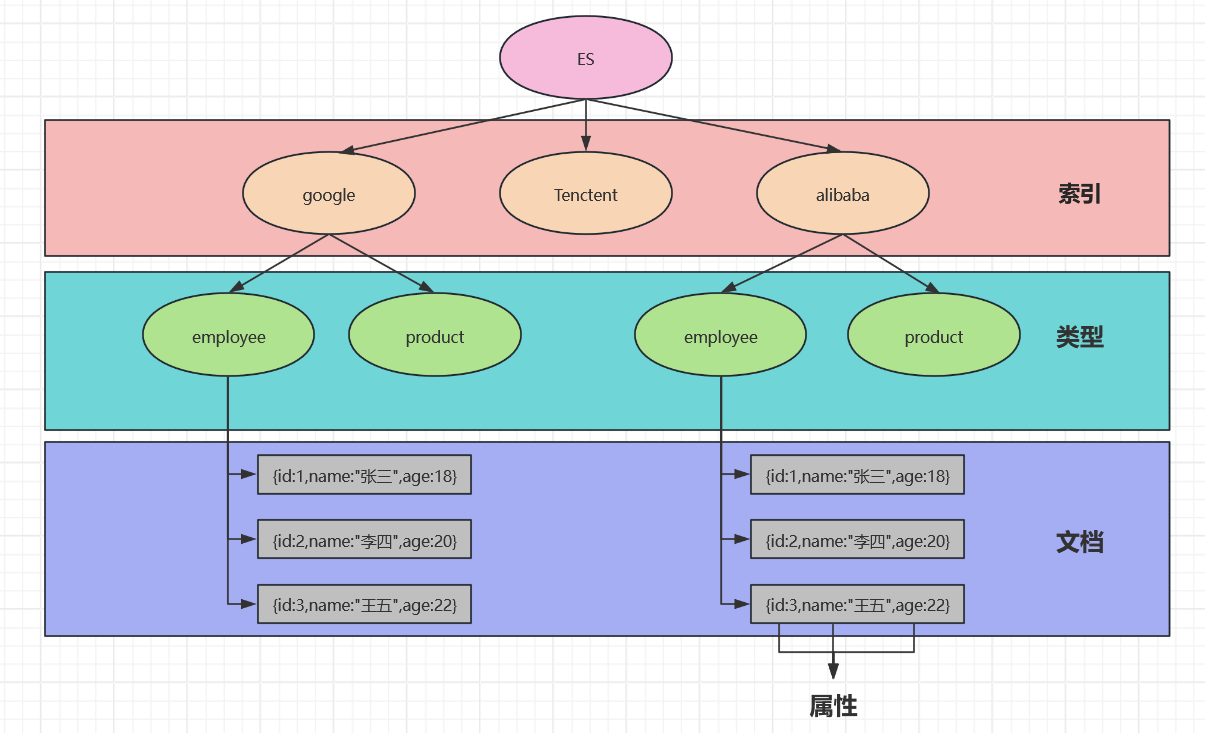
ES里的Index可以看做一个库,而Types相当于表,Documents相当于表的行,在ES7.x的版本中已经删除了Type的概念
基本使用
索引
在MySQL中,索引是加速我们查询的一种方式,而在ES这种搜索引擎中,索引就尤为重要,ES为了能够做到快速准确的查询,使用了一个特殊的概念进行存储和查询:倒排索引
正排(正向)索引
通过文章编号可以快速查询到文章内容,将文章编号设定为主键,生成主键索引,通过主键索引快速定位到存储信息
id content
-------------------
1001 my name is zhangsan
1002 my name is lisi
倒排索引
如果想要查询文章内容中包含了哪些热门词汇,正排索引的模糊查询需要遍历每条数据,效率性能都很差,且文章中的大小写、词态都可能影响查询的准确率,而倒排索引是反过来的,通过关键字来关联主键id
keyword id
-------------------
name 1001,1002
zhang 1001
索引命名规范
- 以小写英文字母命名索引
- 不要使用 驼峰 或者 帕斯卡 命名法则
- 如过出现多个单词的索引名称,以全小写 + 下划线分隔的方式:如 my_index
索引的不可变性
ES 索引创建成功之后,索引名称、主分片数量、字段类型、分词器等参数将不可被修改,造成项目后期难以维护和扩展。
- 运行时字段
- 索引别名
- Reindex
索引的基本组成
- alias:即 索引别名,参考:ES中索引别名(alias)的到底有什么用
- settings:索引设置,常见设置如分片和副本的数量等。
- mapping:即映射,定义了索引中包含哪些字段,以及字段的类型、长度、分词器等。
索引操作
1.创建索引
对比关系型数据库,创建索引就等于创建数据库
在Postman中,向ES服务器发PUT请求:http://localhost:9200/shopping
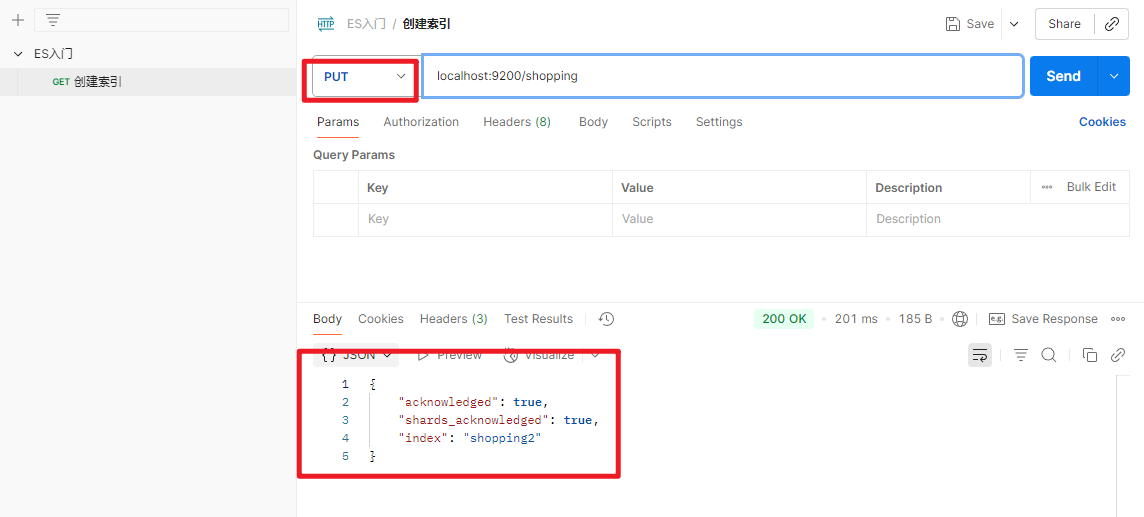
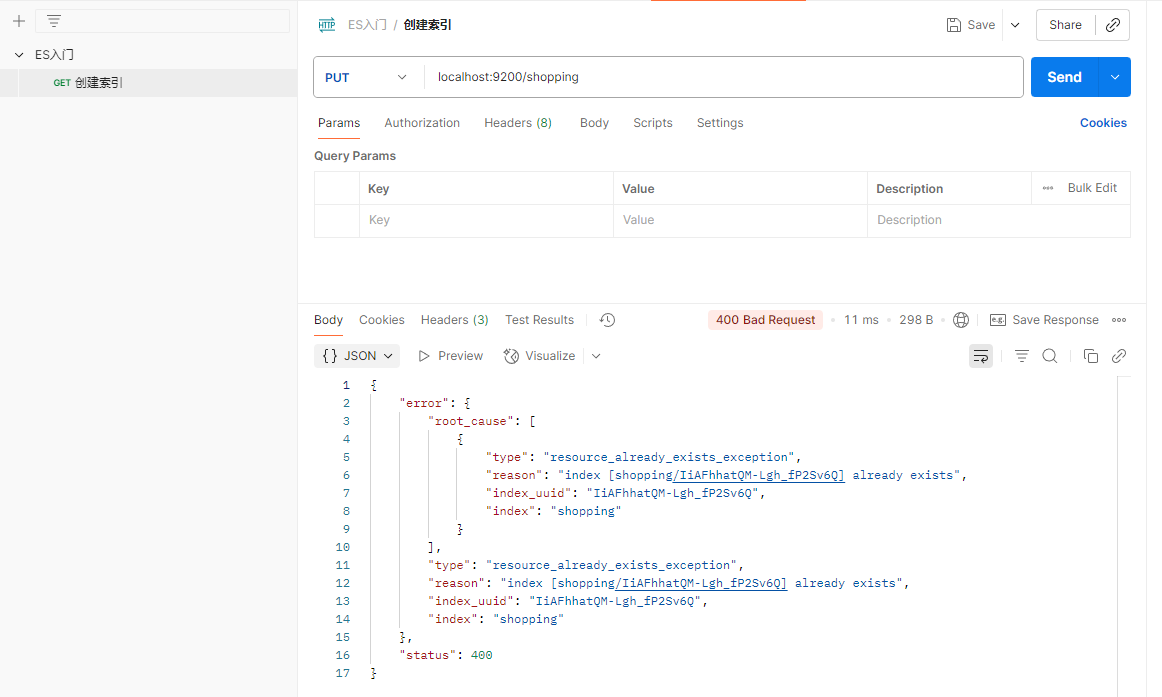
PUT请求具有幂等性,当该索引已经存在,再次发送请求就会返回错误
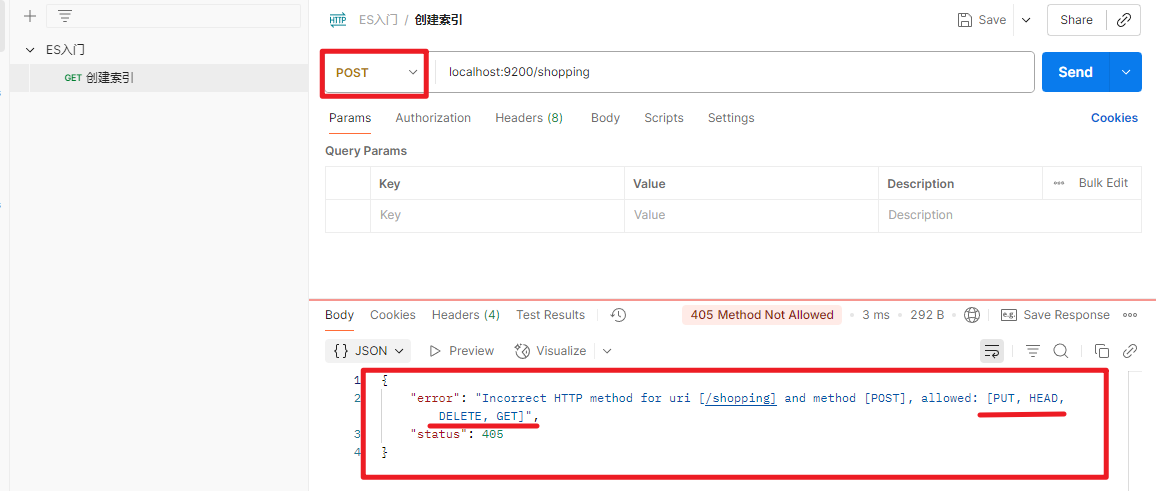
不支持POST请求
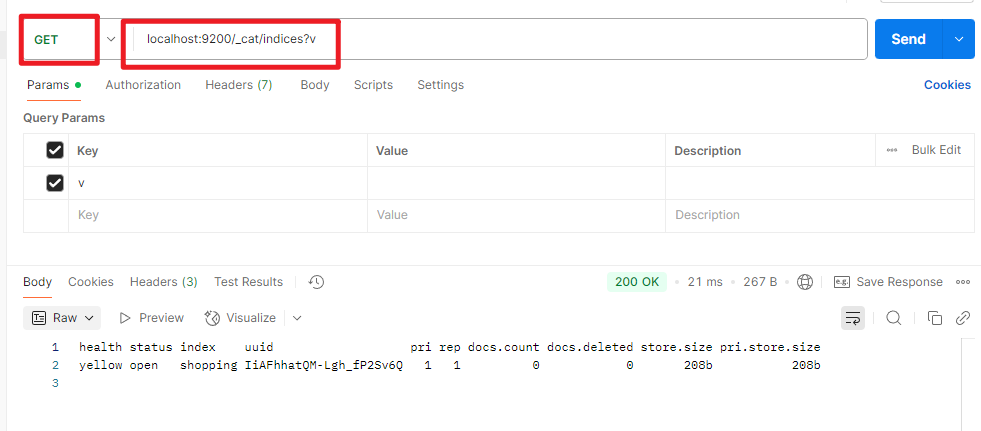
2.查看索引

查看全部索引
localhost:9200/_cat/indices?v
3.删除索引
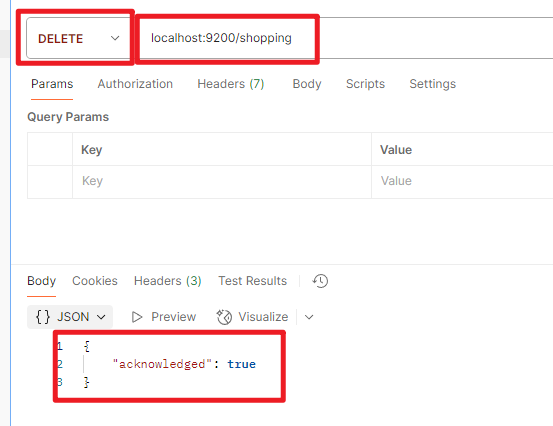
文档操作
1.创建文档
创建好索引之后,要在索引下创建文档,并添加数据,这里的文档可以类比为关系型数据库中的表数据,数据以JSON格式添加
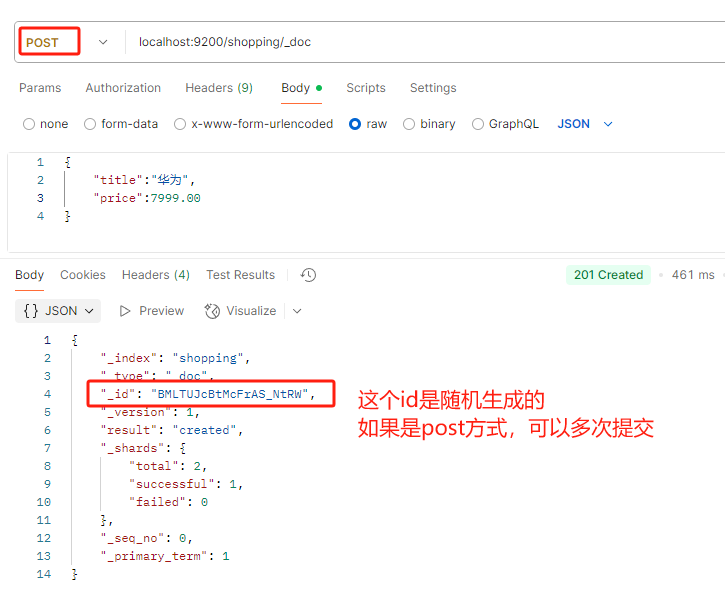
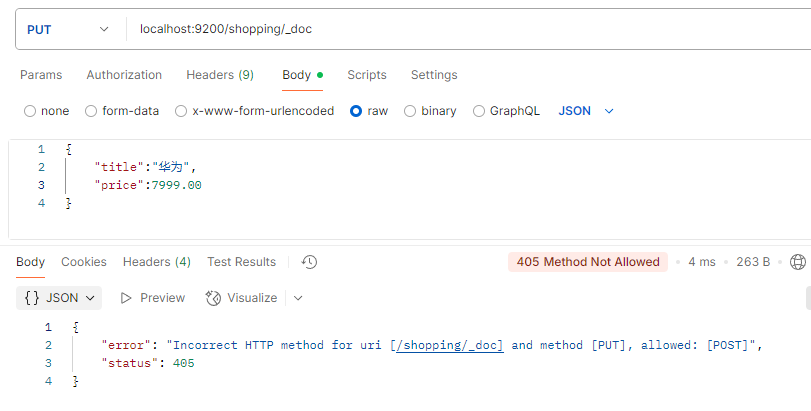
如果不指定索引,由ES自动生成,则必须使用post方式提交,多次提交都可以成功,这是由于post方式是非幂等性的,而put方式是幂等性的,所以提交失败
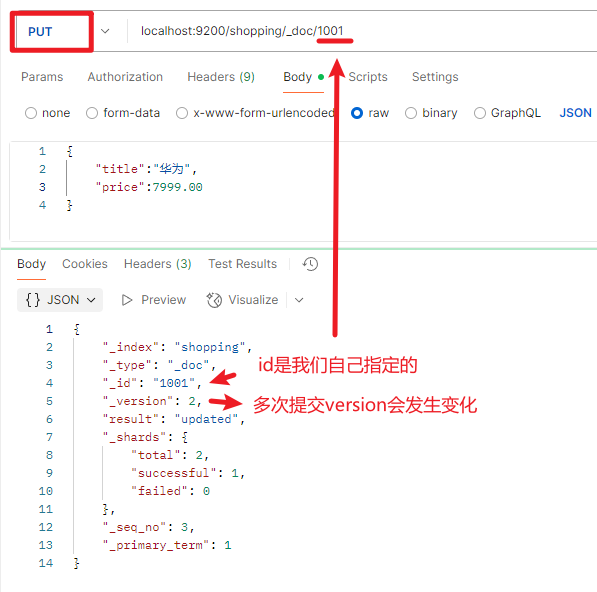
随机生成的id并不方便我们查询,此时我们可以在路径上自定义id,这样post和put方式都可以提交
2.查询文档
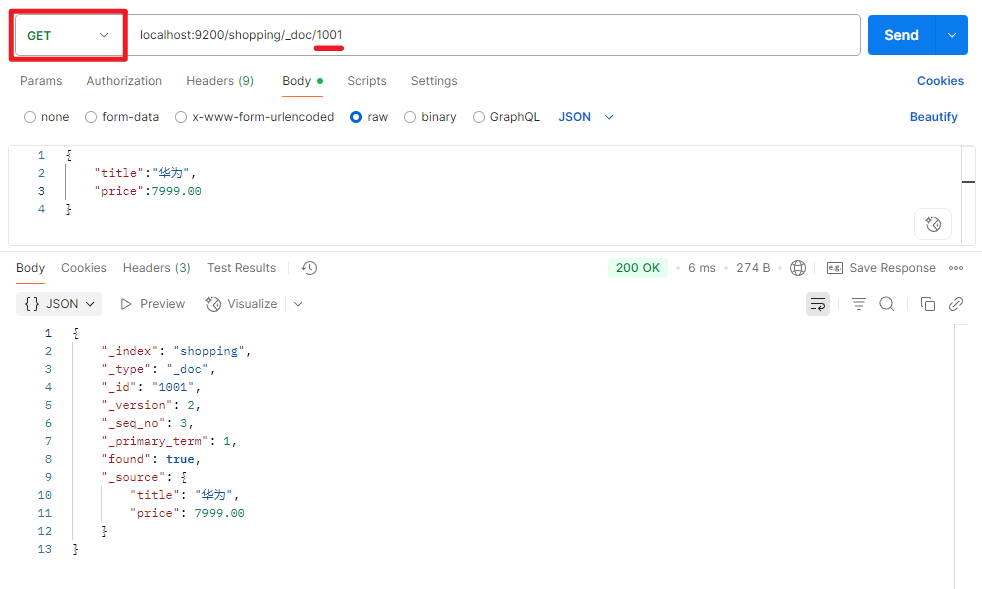
查询文档中所有数据
localhost:9200/索引/_search
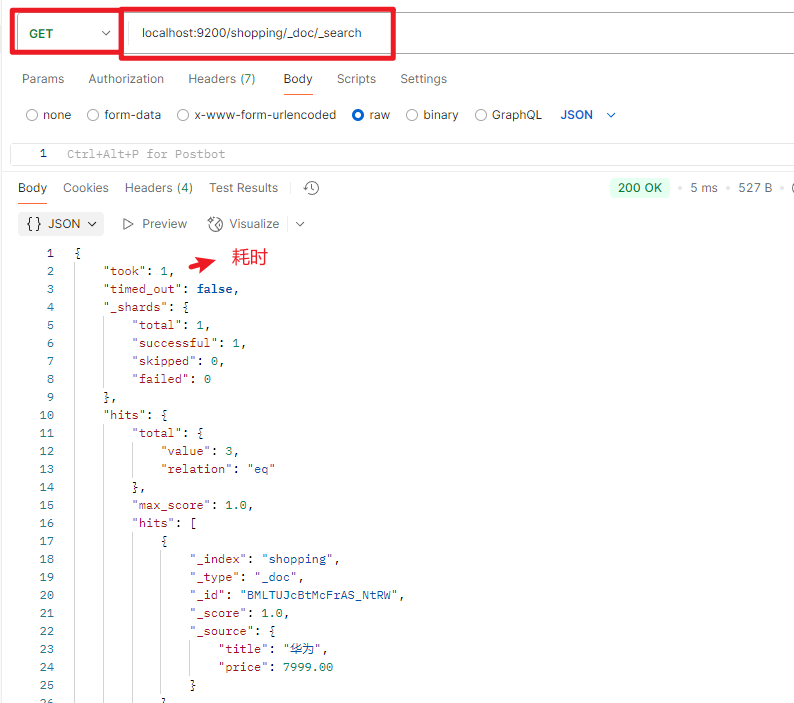
3.修改数据
全量数据更新(PUT)
相当于是覆盖原来的数据,幂等性操作,使用put方式提交
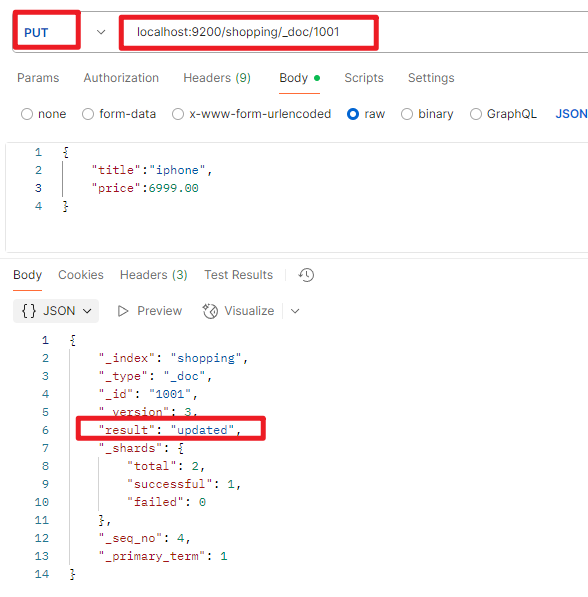
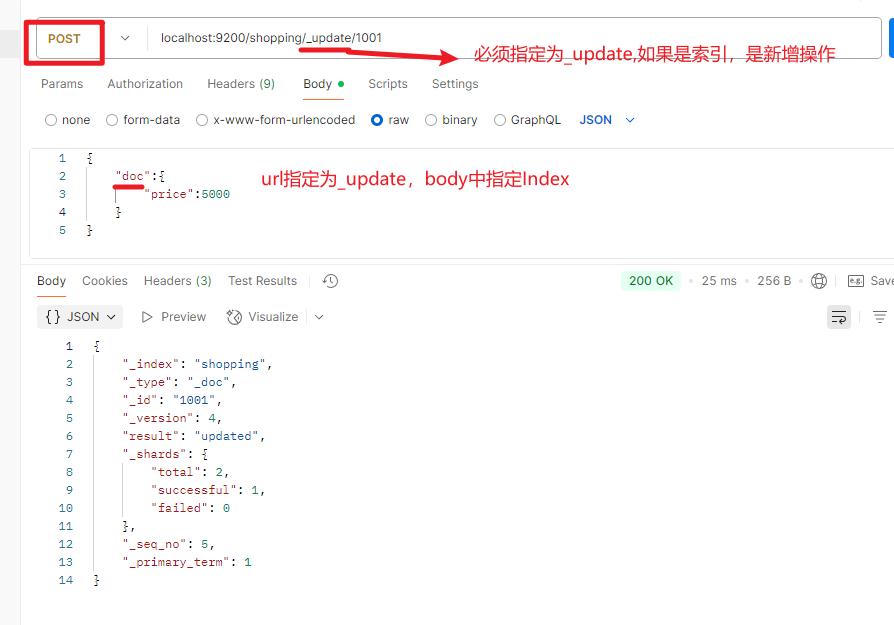
局部数据更新(POST)
4.删除数据
localhost:9200/索引/文档/id - delete请求
查询
条件查询(query)
- url拼接方式:这种方式拼接繁琐,且URL输入中文容易乱码
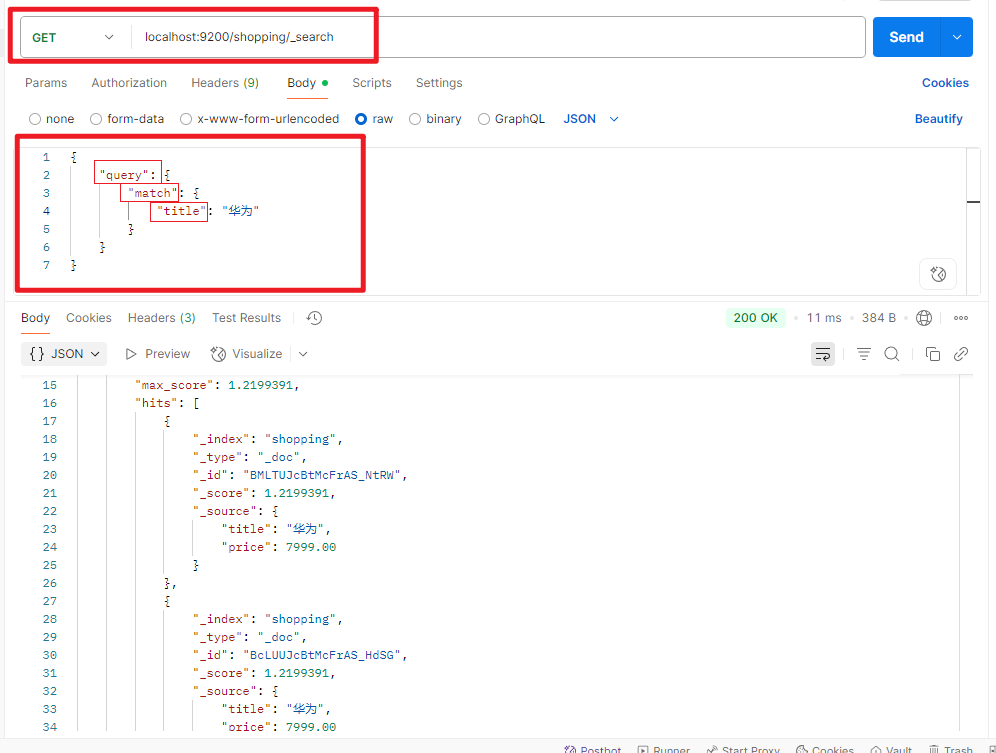
localhost:9200/shopping/_search?q=title:华为
- 请求体方式
localhost:9200/shopping/_search
分页 (from/size)
排序 (sort)
{
"query": {
"match_all": { //全量查询,相当于不带条件
}
},
"from": 0, //起始索引
"size": 1, //页大小
"_source":["title"], //要展示的数据
"sort":{ //排序
"price":{ //排序属性
"order":"desc" //排序规则
}
}
}
多条件 (should/must)
范围 (range)
{
"query": { //查询条件
"bool": {
"should": [ //条件数组 must必须同时满足 如果其一满足 使用should
{
"match": { //条件一匹配要求
"title": "iphone"
}
},
{
"match": { //条件二匹配要求
"price": 5000
}
}
],
"filter":{ //条件过滤
"range":{ //范围查询
"price":{
"gt": 5000 //gt 大于
}
}
}
}
}
}
全文检索 (match)
{
"query": {
"match": { //全量查询,相当于不带条件
“title”:"小华" // ES底层会进行分词,将关键字分成 小 华,只要满足其一就会被检索
}
}
}
完全匹配 (match_phrase)
{
"query": {
"match_phrase": {
"title":"小华"
}
}
}
高亮显示(highlight)
{
"query": {
"match": {
"title":"小华"
}
},
"highlight":{
"fields":{
"title":{}
}
}
}
聚合操作
{
"aggs": { // 聚合操作
"price_group": { // 统计结果的名称 随意起名
"terms":{ // 分组
"field":"price" // 分组字段
}
}
}
}

映射关系
Mapping 也称之为映射,定义了 ES 的索引结构、字段类型、分词器等属性,是索引必不可少的组成部分。
ES 中的 mapping 有点类似与RDB中“表结构”的概念,在 MySQL 中,表结构里包含了字段名称,字段的类型还有索引信息等。在 Mapping 里也包含了一些属性,比如字段名称、类型、字段使用的分词器、是否评分、是否创建索引等属性,并且在ES中一个字段可以有对个类型。分词器、评分等概念在后面的课程讲解。
1.创建索引
localhost:9200/user
2.创建映射
{
"properties": { // 属性
"name": { // 属性名
"type": "text", // 文本 可以被分词
"index": true // 该字段可以索引查询
},
"gender":{
"type":"keyword", // 关键字不可以分词 必须完整匹配
"index": true
},
"tel":{
"type":"keyword", // 关键字不可以分词 必须完整匹配
"index": false // 不能被索引查询
}
}
}

3.添加数据
{
"name":"张三",
"gender":"男的",
"tel":"1111"
}
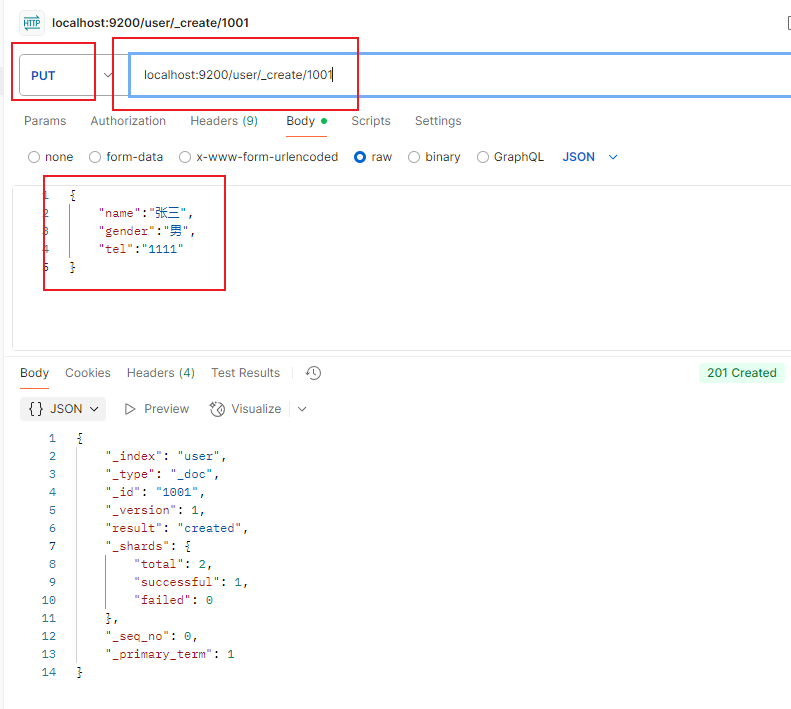
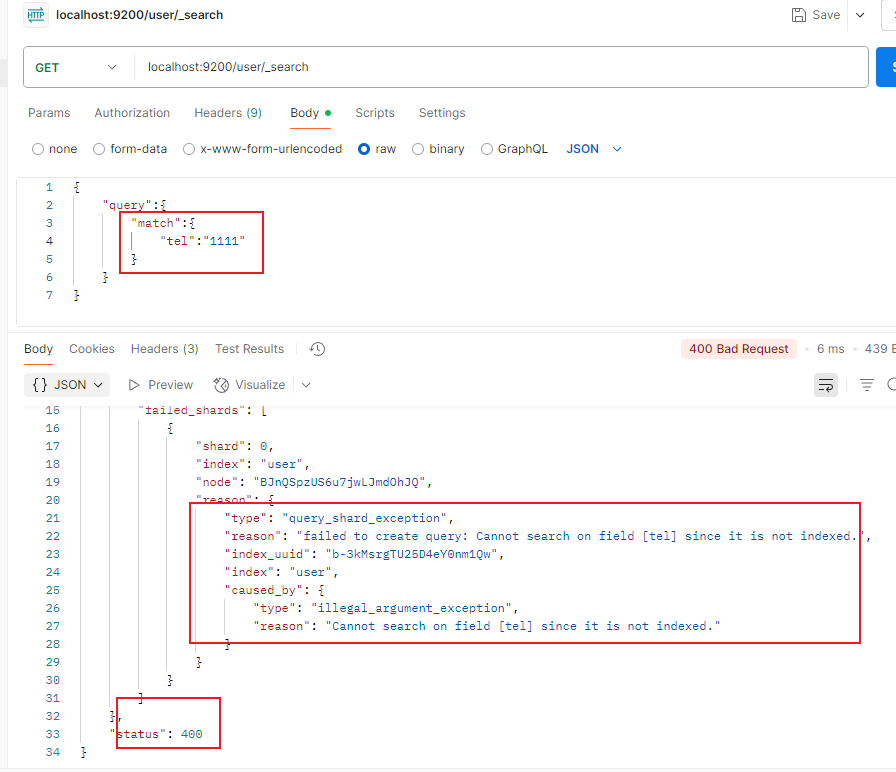
4.查询数据
name可以分词查询
gender不可以分词查询,就算用了match,也必须精确匹配
tel不能被索引,所以无法查询,
{
"query":{
"match":{
"tel":"1111"
}
}
}
分词器
分词器(Text Analysis),也称为词法分析器(Lexical Analyzer),是一种将文本(通常是自然语言文本)分解成一系列单独的词汇单元(Token)的程序。
在自然语言处理中,分词器通常用于将文本分解成单独的词汇单元,这些单元将作为后续处理步骤的输入。这些词汇单元可以是单词、短语或句子等文本元素,这取决于分词器的具体实现和应用场景。例如,在搜索引擎中,分词器将文本查询分解成关键词,以便于搜索引擎匹配相关文档。
分词器通常基于特定的规则或算法进行操作。这些规则或算法可能基于词汇表、语法规则或机器学习技术等。在一些分词器中,还可能涉及词干提取、停用词过滤、拼写纠正、同义词处理等操作,以提高分词的准确性和效果。
_analyze API
在 Elasticsearch 中,可以使用 _analyze API 对指定的文本进行分词和分析,以便于调试和优化分词器的性能。
要使用 _analyze API,可以使用以下 HTTP 请求:
GET /{index}/_analyze
{
"analyzer": "{analyzer_name}",
"text": "{text}"
}
其中,{index} 是要分析的索引名称,{analyzer_name} 是要使用的分词器的名称,{text} 是要分析的文本内容。这个请求将返回一个包含分析结果的 JSON 格式的响应。
例如,如果要对 “I am Teacher Li Jin, and I am familiar with technologies such as JVM and MQ” 进行分词,可以使用以下请求:
GET /message/_analyze
{
"text": "I am Teacher Li Jin, and I am familiar with technologies such as JVM and MQ",
"analyzer": "standard"
}
这个请求将使用标准分词器对 “Quick brown fox” 进行分词,并返回以下结果:
{
"tokens" : [
{
"token" : "i",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "am",
"start_offset" : 2,
"end_offset" : 4,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "teacher",
"start_offset" : 5,
"end_offset" : 12,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "li",
"start_offset" : 13,
"end_offset" : 15,
"type" : "<ALPHANUM>",
"position" : 3
},
{
"token" : "jin",
"start_offset" : 16,
"end_offset" : 19,
"type" : "<ALPHANUM>",
"position" : 4
},
{
"token" : "and",
"start_offset" : 21,
"end_offset" : 24,
"type" : "<ALPHANUM>",
"position" : 5
},
{
"token" : "i",
"start_offset" : 25,
"end_offset" : 26,
"type" : "<ALPHANUM>",
"position" : 6
},
{
"token" : "am",
"start_offset" : 27,
"end_offset" : 29,
"type" : "<ALPHANUM>",
"position" : 7
},
{
"token" : "familiar",
"start_offset" : 30,
"end_offset" : 38,
"type" : "<ALPHANUM>",
"position" : 8
},
{
"token" : "with",
"start_offset" : 39,
"end_offset" : 43,
"type" : "<ALPHANUM>",
"position" : 9
},
{
"token" : "technologies",
"start_offset" : 44,
"end_offset" : 56,
"type" : "<ALPHANUM>",
"position" : 10
},
{
"token" : "such",
"start_offset" : 57,
"end_offset" : 61,
"type" : "<ALPHANUM>",
"position" : 11
},
{
"token" : "as",
"start_offset" : 62,
"end_offset" : 64,
"type" : "<ALPHANUM>",
"position" : 12
},
{
"token" : "jvm",
"start_offset" : 65,
"end_offset" : 68,
"type" : "<ALPHANUM>",
"position" : 13
},
{
"token" : "and",
"start_offset" : 69,
"end_offset" : 72,
"type" : "<ALPHANUM>",
"position" : 14
},
{
"token" : "mq",
"start_offset" : 73,
"end_offset" : 75,
"type" : "<ALPHANUM>",
"position" : 15
}
]
}
这个响应包含了分析结果,其中包括了分词后的单词、单词的偏移量、类型和位置等信息。
总之,_analyze API 可以帮助您了解分词器的工作原理和分析结果,以便于优化分词器的性能和效果。
分词器的组成
Character Filter
- HTML 标签过滤器
- 字符映射过滤器:Mapping Character Filter
- 正则替换过滤器:Pattern Replace Character Filter
Tokenizer
可以把切词器理解为预定义的切词规则。官方内置了很多种切词器,默认的切词器为 standard。
Token Filter
在 Elasticsearch (ES) 中,Token Filter 是一种文本处理组件,用于对 Tokenizer 分割得到的词汇单元进行进一步的处理和修改。Token Filter 可以修改、删除或添加新的词汇单元,以改善索引和搜索的效果。
在 Elasticsearch 的查询 DSL (Domain Specific Language) 中,可以通过配置 Token Filter 来定义如何处理和修改文本数据。
常见的 token filter
synonym:用于将指定的词汇替换为其同义词。这对于扩展搜索能力或纠正拼写错误很有用。例如,将 “car” 替换为 “automobile”。ngram:将词汇单元拆分成 n-gram(连续的 n 个字符),用于支持部分匹配和模糊搜索。例如,“quick” 可以拆分成 “qu”、“qui”、“quic”、“quick”。stemmer:应用词干提取算法,将单词还原为其词干形式。例如,将 “running” 还原为 “run”。stop:移除停用词,这些词在搜索中往往没有实际意义或频繁出现。例如,“the”、“is”、“and”。trim:修剪词汇单元的前导和尾随空格。phonetic:生成音译代码,用于支持音译搜索。例如,将 “Smith” 转换为 “SM0”.
ik分词器
https://release.infinilabs.com/analysis-ik/stable/
重启es.bat
localhost:9200/my_zh_index/_doc/1
{
"message":"这是一段中文文本",
"messageId":1
}
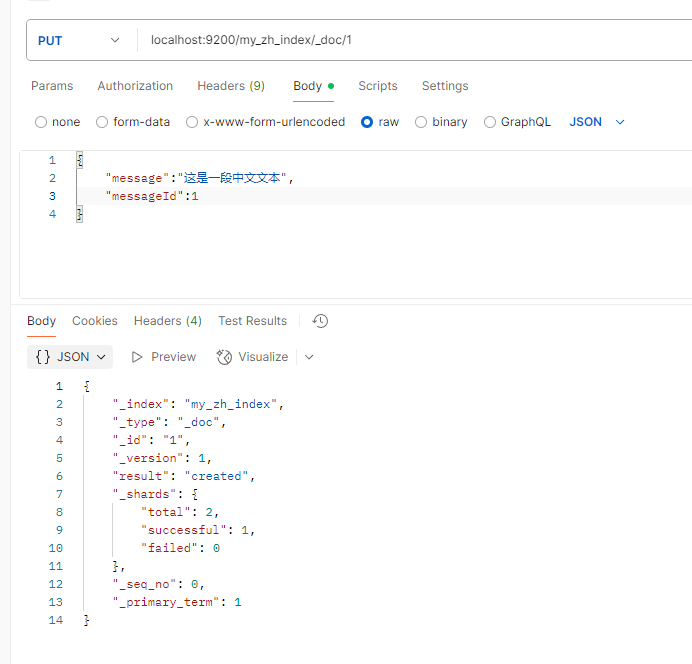
localhost:9200/my_zh_index/_analyze
{
"analyzer": "ik_smart",
"text": "这是一段中文文本"
}
springboot整合
引入依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<!-- jest连接 --> <dependency>
<groupId>io.searchbox</groupId>
<artifactId>jest</artifactId>
<version>6.3.1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.83</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
Jest连接ES
配置类
@Configuration
public class JestConfig {
@Bean
public JestClient jestClient(){
JestClientFactory factory = new JestClientFactory();
factory.setHttpClientConfig(new HttpClientConfig.Builder("http://localhost:9200")
.multiThreaded(true)
.build());
return factory.getObject();
}
}
实体类
@Data
@ToString
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class Article implements Serializable {
@JestId // 标识主键☆
private Integer id;
private String author;
private String title;
private String content;
}

测试
@SpringBootTest
public class Test01 {
@Resource
private JestClient jestClient;
@Test
public void test() {
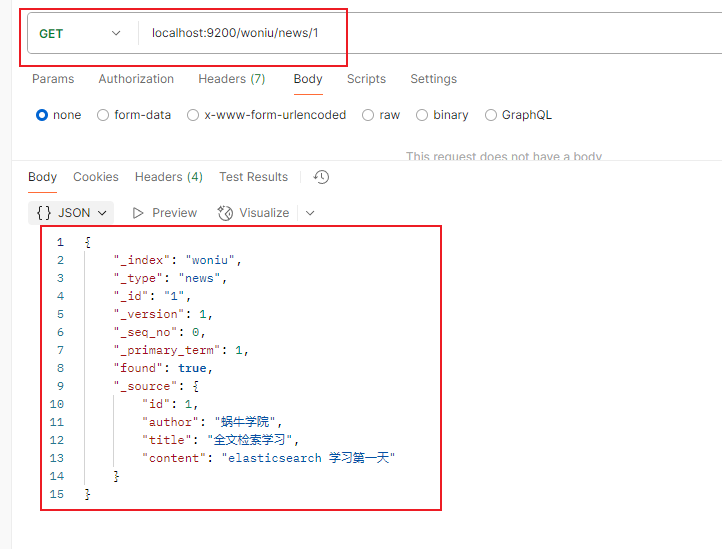
Article article = Article.builder().id(1)
.author("蜗牛学院")
.title("全文检索学习")
.content("elasticsearch 学习第一天")
.build();
// 构建一个索引
Index index = new Index.Builder(article)
.index("woniu") // 指定索引名称
.type("news") // 指定索引类型
.build();
try {
jestClient.execute(index);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
@Test
public void search(){
// 测试搜索
String json = "{\n" +
" \"query\":{\n" +
" \"match_all\":{\n" +
" \n" +
" }\n" +
" }\n" +
"}";
// 构建搜索条件
Search search = new Search.Builder(json)
.addIndex("woniu") // 指定索引
.addType("news").build(); // 指定类型
try {
SearchResult result = jestClient.execute(search);
System.out.println(result.getJsonString());
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
SpringData操作ES
配置文件
spring:
elasticsearch:
uris: http://localhost:9200
实体类
@Data
@ToString
@NoArgsConstructor
@AllArgsConstructor
@Document(indexName = "book") // 标识索引,项目启动会自动创建索引
public class Book implements Serializable {
@Id
private Integer id;
@Field(type = FieldType.Text)
private String bookName;
@Field(type = FieldType.Keyword) // 不分词
private String author;
@Field(type = FieldType.Double)
private Double price;
@Field(type = FieldType.Keyword,index = false) // 不分词且不做索引关联
private String img;
}
接口
// 泛型参数1 实体类类型 2主键类型
public interface BookMapper extends ElasticsearchRepository<Book,Integer> {
public List<Book> findByBookNameLike(String bookName);
}
测试
@SpringBootTest
public class Test02 {
@Resource
private ElasticsearchRestTemplate restTemplate;
@Resource
private BookMapper bookMapper;
@Test
public void test01(){
Book book = new Book(1,"一本书","作者1");
restTemplate.save(book);
}
@Test
public void test02(){
List<Book> bookList = bookMapper.findByBookNameLike("书");
bookList.forEach(System.out::println);
}
}
本文来自博客园,作者:icui4cu,转载请注明原文链接:https://www.cnblogs.com/icui4cu/p/18928030

 浙公网安备 33010602011771号
浙公网安备 33010602011771号