6.Redis
redis介绍
属于非关系型数据库,NoSQL (Not noly SQL)不仅仅是SQL,为什么需要NoSQL,主要应对以下问题,传统关系型数据库力不从心
- High performance -高并发读写
- Huge Storage-海量数据的高效率存储和访问
- High Scalablility && High Availability 高可扩展性和高可用性
NoSQL 产品 MongoDB Redis等等 Redis目前主流,NoSQL的特点
- 易扩展
- 灵活的数据模型
- 大数据量,高性能
- 高可用
- 高性能键值对内存数据库,支持的键值数据类型
应用场景
- 缓存
- 任务队列
- 网站访问统计
- 数据过期处理
- 应用排行榜
- 分布式集群架构中的session分离
- 分布式锁
redis为什么快
- 运行在内存中 redis是C语言 cpu 内存 磁盘
- 采用多路复用I/O模型
- 内置很多高效的数据类型(算法)
- redis的主线程是单线程,没有多线程上下文切换的性能消耗
通用操作
keys *、keys ?、exists 、rename 、expire 、ttl 、type 、select 1
基本数据类型
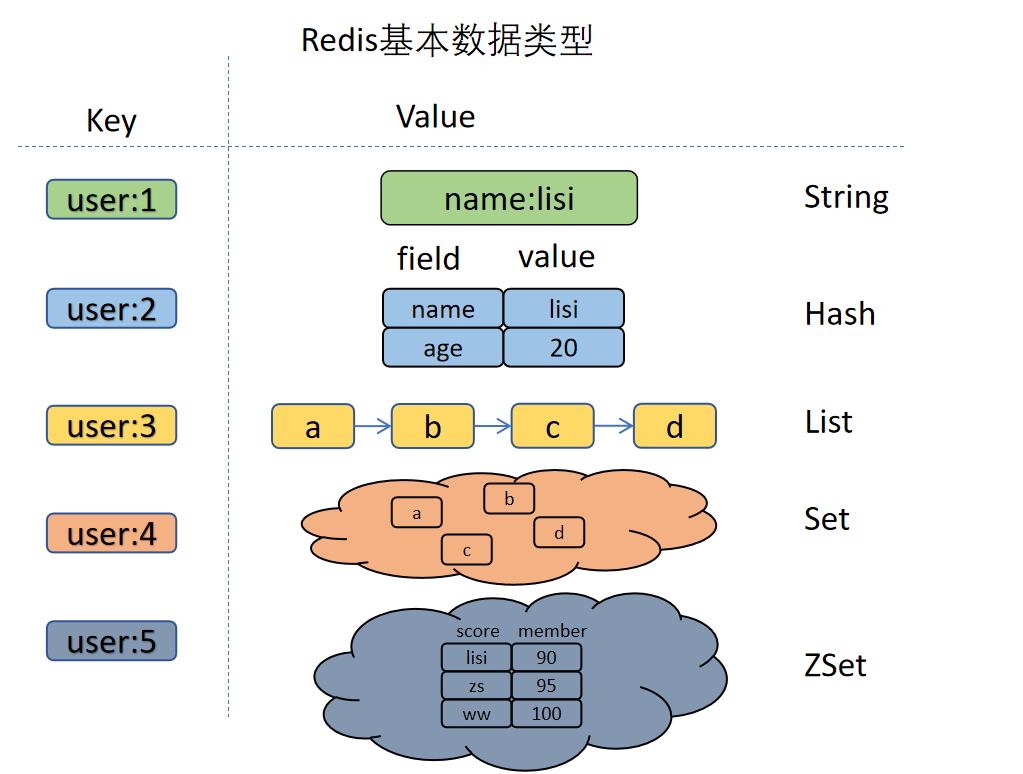
String
- 字符串类型
- 常用指令:set、get、setget、del、incr、incrby、decr、decrby、append
List
- 列表类型可以两头插入,索引始终从左向右计算,从0开始,有序可重复,可做消息队列
- 常用指令:lpush、lpushx、rpush、rphshx、lange、lpop、rpop、llen、lrem、lset、linsert..before、linsert..after、rpoplpush
Hash
- 类似于java中的 Map<String,Map<String,String>>
- 常用指令:hset、hget、hmset、hmget、hgetall、hdel、hincrby、hexists、hlen、hkeys、hvals
Set
- 同java中的set,无序不重复、可以统计差集、交集、并集,可以跟踪一些唯一性数据
- 常用指令:sadd、smembers、srem、sismember、sdiff、sinter、sunion、scard、srandmember、sdiffstore 、sinterstore、sunionstore
Zset
- sorted-set,是有序的set集合,每一个元素包含了评分和值,插入元素的时候需要带评分,默认评分从小到大排列,可用于实时排行
- 常用指令:zadd、zrange、zrange...withscores、zscore、zrem 、zrevrange、zrangebyscore...limit、zremrangebyrank、zincrby、zcount
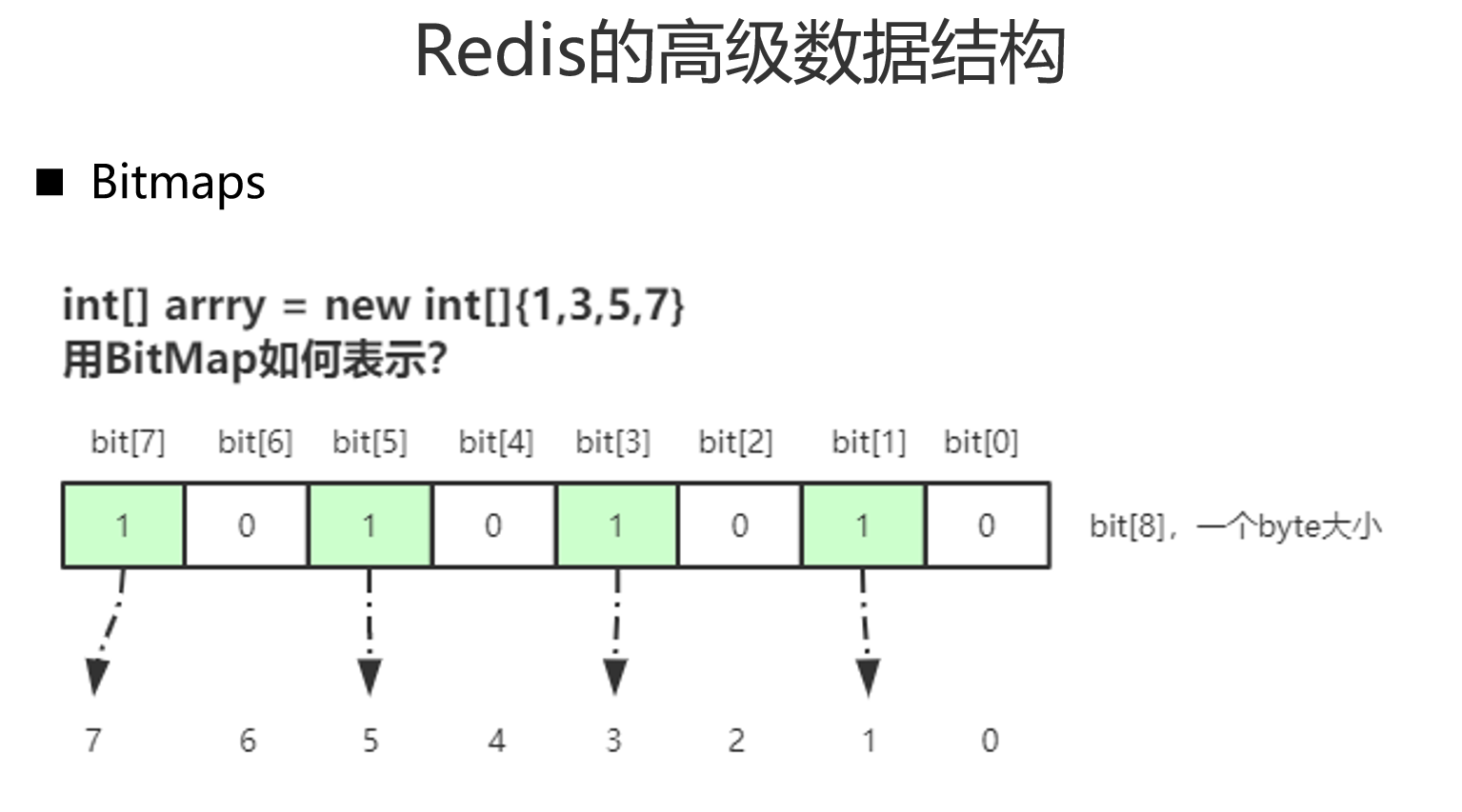
高级数据类型
Bitmaps
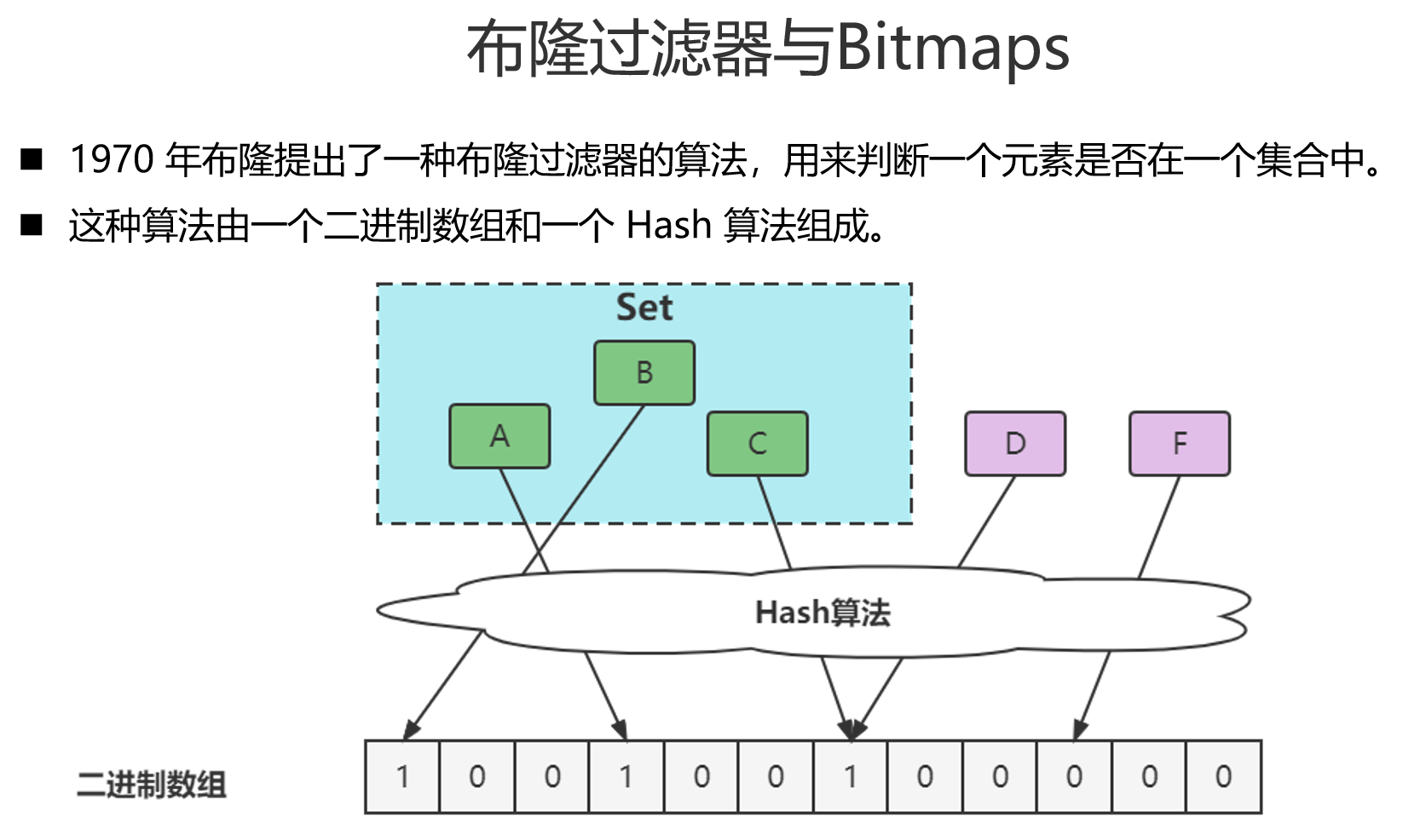
布隆过滤器
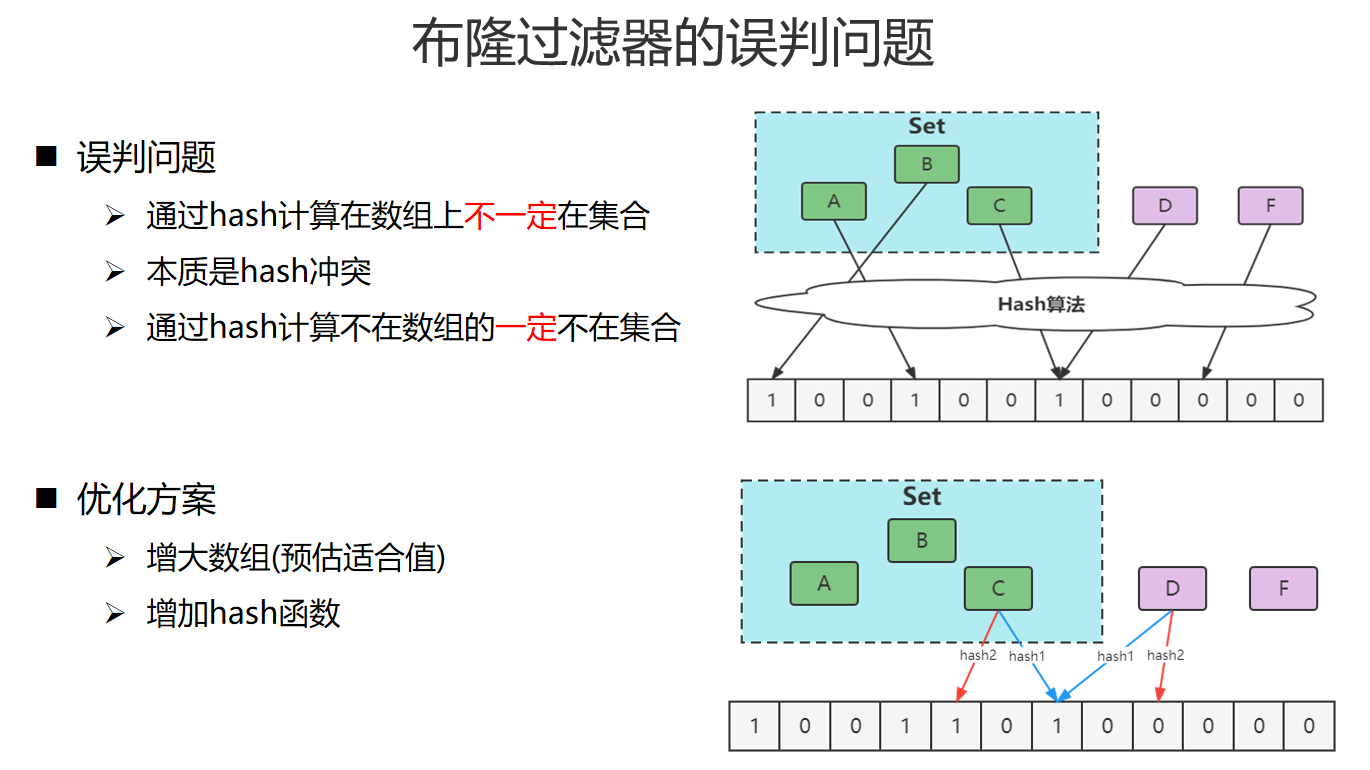
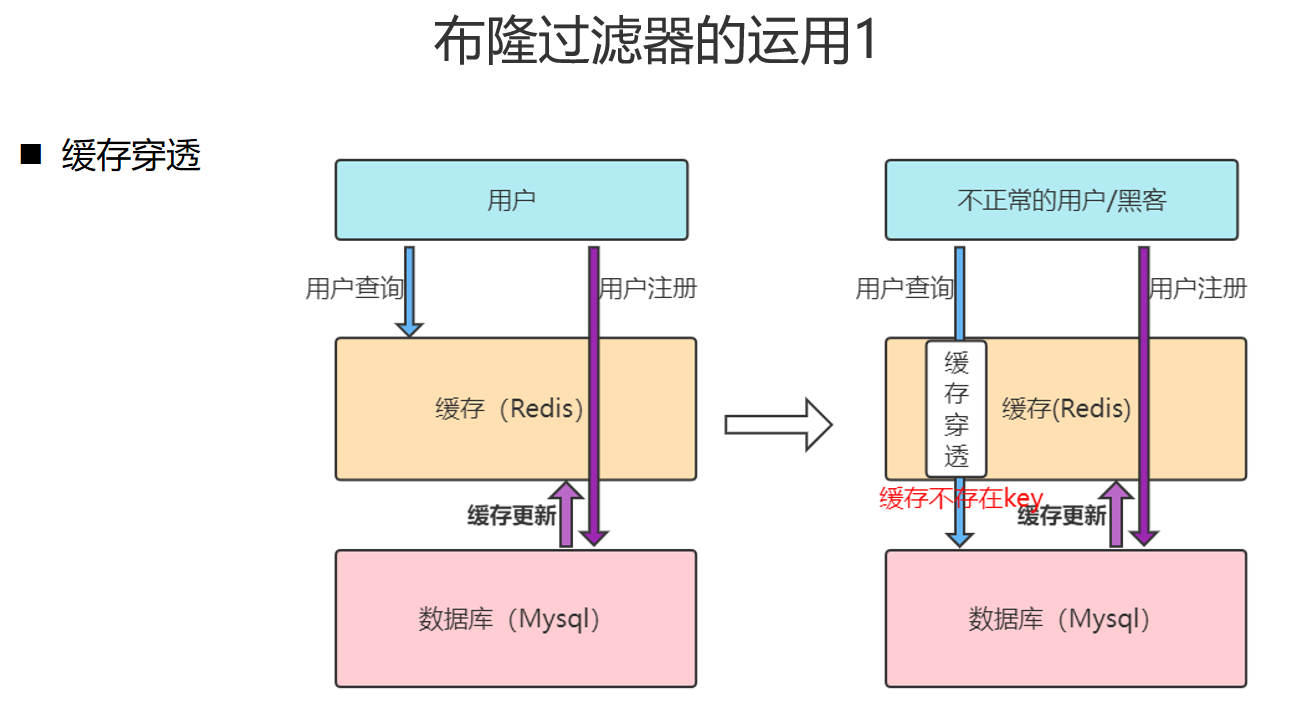
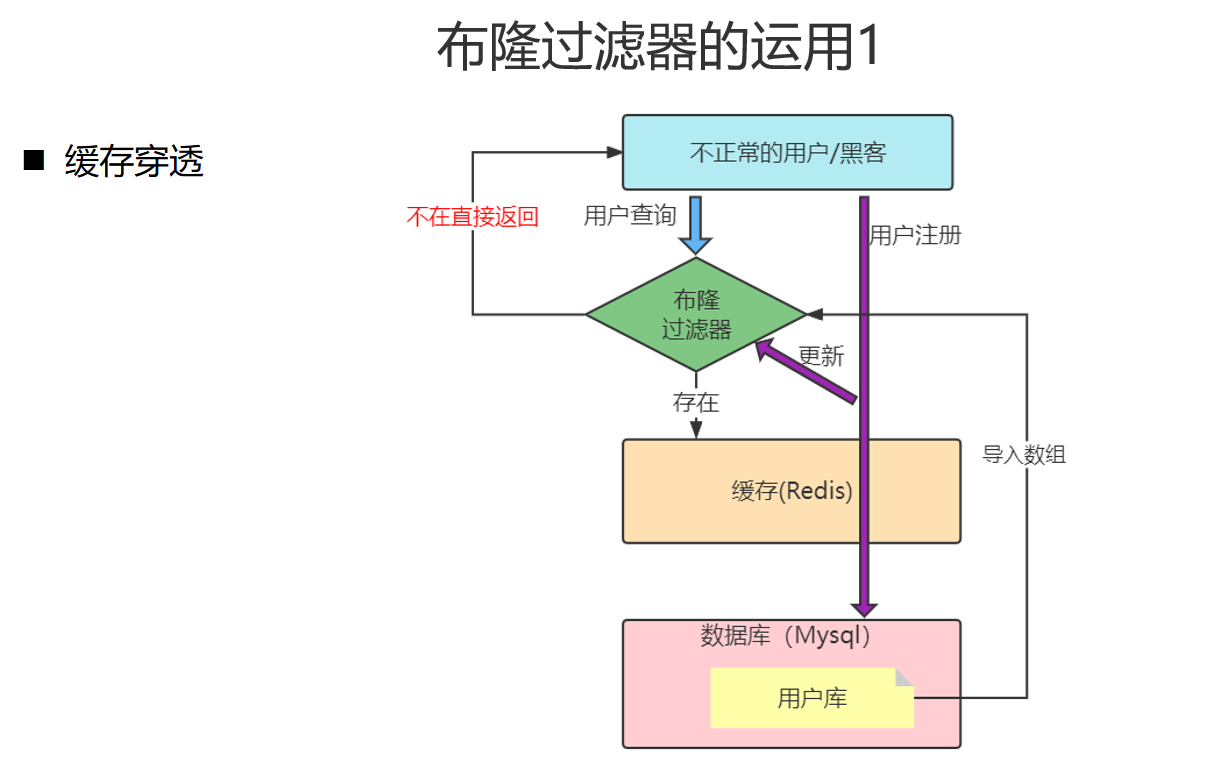
实现
Guava实现
dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.1-jre</version>
</dependency>
/*单机下无Redis的布隆过滤器:使用Google的Guava的BloomFilter*/
public class GuavaBF {
public static void main(String[] args) {
long expectedInsertions = 100000;
double fpp = 0.00005;
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), expectedInsertions, fpp);
bloomFilter.put("10081");
bloomFilter.put("10082");
bloomFilter.put("10083");
bloomFilter.put("10084");
bloomFilter.put("10085");
bloomFilter.put("10086");
System.out.println("123456:BF--"+bloomFilter.mightContain("123456"));//false
System.out.println("10086:BF--"+bloomFilter.mightContain("10086"));//true
System.out.println("10084:BF--"+bloomFilter.mightContain("10084"));//true
}
}
Google的实现
/*仿Google的布隆过滤器实现,基于redis支持分布式*/
public class RedisBloomFilter {
public final static String RS_BF_NS = "rbf:";
private int numApproxElements; /*预估元素数量*/
private double fpp; /*可接受的最大误差*/
private int numHashFunctions; /*自动计算的hash函数个数*/
private int bitmapLength; /*自动计算的最优Bitmap长度*/
@Autowired
private JedisPool jedisPool;
/**
* 构造布隆过滤器
* @param numApproxElements 预估元素数量
* @param fpp 可接受的最大误差
* @return
*/
public RedisBloomFilter init(int numApproxElements,double fpp){
this.numApproxElements = numApproxElements;
this.fpp = fpp;
/*位数组的长度*/
//this.bitmapLength = (int) (-numApproxElements*Math.log(fpp)/(Math.log(2)*Math.log(2)));
this.bitmapLength=128;
/*算hash函数个数*/
//this.numHashFunctions = Math.max(1, (int) Math.round((double) bitmapLength / numApproxElements * Math.log(2)));
this.numHashFunctions=2;
return this;
}
/**
* 计算一个元素值哈希后映射到Bitmap的哪些bit上
* 用两个hash函数来模拟多个hash函数的情况
* * @param element 元素值
* @return bit下标的数组
*/
private long[] getBitIndices(String element){
long[] indices = new long[numHashFunctions];
/*会把传入的字符串转为一个128位的hash值,并且转化为一个byte数组*/
byte[] bytes = Hashing.murmur3_128().
hashObject(element, Funnels.stringFunnel(Charset.forName("UTF-8"))).
asBytes();
long hash1 = Longs.fromBytes(bytes[7],bytes[6],bytes[5],bytes[4],bytes[3],bytes[2],bytes[1],bytes[0]);
long hash2 = Longs.fromBytes(bytes[15],bytes[14],bytes[13],bytes[12],bytes[11],bytes[10],bytes[9],bytes[8]);
/*用这两个hash值来模拟多个函数产生的值*/
long combinedHash = hash1;
for(int i=0;i<numHashFunctions;i++){
//数组下标
indices[i]=(combinedHash&Long.MAX_VALUE) % bitmapLength;
combinedHash = combinedHash + hash2;
}
System.out.print(element+"数组下标");
for(long index:indices){
System.out.print(index+",");
}
System.out.println(" ");
return indices;
}
/**
* 插入元素
*
* @param key 原始Redis键,会自动加上前缀
* @param element 元素值,字符串类型
* @param expireSec 过期时间(秒)
*/
public void insert(String key, String element, int expireSec) {
if (key == null || element == null) {
throw new RuntimeException("键值均不能为空");
}
String actualKey = RS_BF_NS.concat(key);
try (Jedis jedis = jedisPool.getResource()) {
try (Pipeline pipeline = jedis.pipelined()) {
for (long index : getBitIndices(element)) {
pipeline.setbit(actualKey, index, true);
}
pipeline.syncAndReturnAll();
} catch (Exception ex) {
ex.printStackTrace();
}
jedis.expire(actualKey, expireSec);
}
}
/**
* 检查元素在集合中是否(可能)存在
*
* @param key 原始Redis键,会自动加上前缀
* @param element 元素值,字符串类型
*/
public boolean mayExist(String key, String element) {
if (key == null || element == null) {
throw new RuntimeException("键值均不能为空");
}
String actualKey = RS_BF_NS.concat(key);
boolean result = false;
try (Jedis jedis = jedisPool.getResource()) {
try (Pipeline pipeline = jedis.pipelined()) {
for (long index : getBitIndices(element)) {
pipeline.getbit(actualKey, index);
}
result = !pipeline.syncAndReturnAll().contains(false);
} catch (Exception ex) {
ex.printStackTrace();
}
}
return result;
}
@Override
public String toString() {
return "RedisBloomFilter{" +
"numApproxElements=" + numApproxElements +
", fpp=" + fpp +
", numHashFunctions=" + numHashFunctions +
", bitmapLength=" + bitmapLength +
'}';
}
}
Redisson实现
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.12.5</version>
</dependency>
/*Redisson底层基于位图实现了一个布隆过滤器,使用非常方便*/
@Test
public void testBloomFilter(){
Config config = new Config();
config.useSingleServer().setAddress("redis://localhost:6379");
//构造Redisson
RedissonClient redisson = Redisson.create(config);
RBloomFilter<Object> bloomFilter = redisson.getBloomFilter("userList");
// 初始化布隆过滤器:预计元素为100000000L,误差率为3%
bloomFilter.tryInit(100000000L,0.03);
// 将号码10081~10086插入到布隆过滤器中
bloomFilter.add("10081");
bloomFilter.add("10082");
bloomFilter.add("10083");
bloomFilter.add("10084");
bloomFilter.add("10085");
bloomFilter.add("10086");
// 判断下面号码是否存在布隆过滤器中
System.out.println("123123:BF--"+bloomFilter.contains("123123"));//false
System.out.println("10086:BF--"+bloomFilter.contains("10086"));//true
System.out.println("10084:BF--"+bloomFilter.contains("10084"));//true
}
缓存问题
缓存原则
1、热点数据必须放入缓存中;
2、对于缓存场景,推荐使用本地缓存与分布式缓存相结合的方案;
3、优先读取本地缓存,以本地缓存为主,分布式缓存为辅;
4、为所有缓存设置过期时间,本地缓存的过期时间应控制在秒级;
5、本地缓存应同时设置容量驱逐和时间驱逐两种策略;
6、缓存键值对应业务逻辑,避免不同场景使用相同的键;
7、缓存列表数据时,仅缓存第一页,且缓存数量不超过20;
8、避免并发更新缓存,以防缓存击穿;
9、空数据也应放入缓存中,防止缓存穿透;
10、读取数据时,先从缓存中读取,若无则从数据库中读取;
11、写入数据时,先写入数据库,再更新缓存。
缓存穿透
客户端请求的数据缓存和数据库中都不存在,永远不会有缓存生效,请求直接到达数据库
解决方案
- 缓存空对象,实现简单,会有多余的空对象
- 布隆过滤器,存在误判的情况
/*
* 缓存数据详情
* 1.根据id去redis中查询
* 2.如果缓存中没有,查询数据库,放缓存
*
* 出现的问题:如果用户查询一个数据库和缓存都没有的数据,缓存无效,这些数据都会直达数据库,缓存穿透
* 1.缓存一个空对象:可以解决缓存穿透问题,但是缓存中会出现很多垃圾数据
* 2.布隆过滤器:可以把所有的书籍id放在bitmap数据中,用户查询可以立刻筛选出这个id是否在数据库的表中,如果不存在可以
*/
@Override
public ResponseUtil queryById(Long id) {
TBook cacheBook = (TBook) redisTemplateInit.opsForHash().get(ConstantUtil.REDIS_BOOK_Detail, id + "");
if (cacheBook != null) {
//缓存中存在,直接返回缓存的结果
return ResponseUtil.get(ResponseEnum.OK, cacheBook);
}
//如果缓存中没有,去数据库查询
TBook book = tBookMapper.selectByPrimaryKey(id);
//缓存到数据库
redisTemplateInit.opsForHash().put(ConstantUtil.REDIS_BOOK_Detail, id + "", book == null ? new TBook() : book);
//设置不同的过期时间,解决缓存雪崩问题
redisTemplateInit.expire(ConstantUtil.REDIS_BOOK_Detail, 30 + RandomUtil.randomInt(10), TimeUnit.DAYS);
return ResponseUtil.get(ResponseEnum.OK, book);
}
缓存雪崩
同一时间大量的缓存key失效,或者redis宕机,导致大量的请求达到数据库
解决方案
- 给不同的key添加不同的过期时间
- redis集群提高服务可用性
- 给业务添加多级缓存,redis缓存、本地缓存等
缓存击穿
当前key是一个热点key(例如一个秒杀活动),并发量非常大,在缓存失效的瞬间,有大量线程来重建缓存,造成后端负载加大
解决方案
查询缓存未命中时,去查询数据库的代码前加互斥锁(可以用redis分布式锁),从数据库查询数据并且写入缓存完毕后释放锁
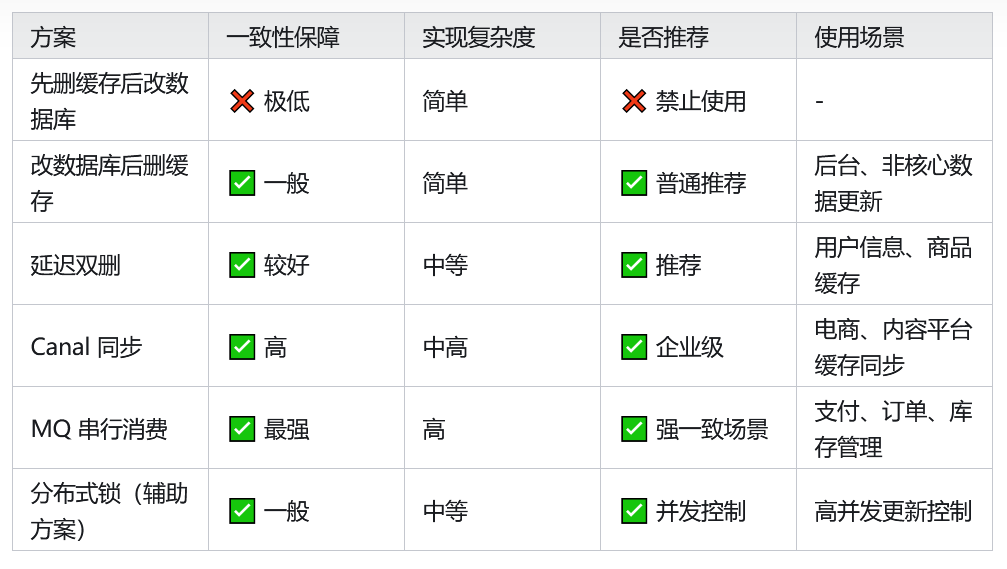
数据一致性
对缓存对应的数据库数据,发生了增删改操作,会导致数据库数据和redis缓存数据不一致的问题
解决方案
- 先删除缓存,再操作数据库
- 先删除缓存再修改数据库数据,可能出现修改之前,其他线程查询了该数据并存入了旧数据在缓存中
- 先操作数据库,再删除缓存
- 如果缓存中没有数据,修改了数据库数据,没有缓存可以删除,此时另一条线程查询该条数据,在放入缓存之前查询到的是修改之前的数据,然后将老数据放入了缓存,后续查到的缓存都是脏数据
- 延迟双删
- 删除缓存
- 修改数据库
- 延迟一段时间 (目的是等待其他操作存入缓存)
- 再删除缓存
public void updateBook(Book book){
// 1.先删除缓存
redisTemplateInit.delete("bookDetail:"+book.getId());
// 2.修改数据库数据
// bookMapper.updateBook(book);
// 3.延迟 100-200ms 时间过长会脏数据的可能性更大
// Thread.sleep(200);
// 4.再次删除缓存
redisTemplateInit.delete("bookDetail:"+book.getId());
}
- 基于 Binlog的异步缓存更新(Canal)

此方案通过监听 MySQL 的 Binlog(操作日志),实现数据库变更时自动推送消息到缓存层更新数据,解耦业务逻辑和缓存维护。
1.MySQL 触发数据变更写入 Binlog
2.Canal 订阅 Binlog 并解析变更事件
3.Canal 推送到 MQ(如 Kafka)
4.消费者订阅 MQ,更新缓存
-
通过 MQ 串行化写请求实现强一致
适用于订单、库存等强一致业务场景。所有写操作不再直接写库,而是通过 MQ 队列串行消费,消费者统一处理更新数据库 + 清理缓存。
1.应用将写操作封装为消息发送到 MQ
2.消费者串行消费消息
3.消费者更新数据库后删除缓存 -
分布式锁辅助方案(Redisson)
在高并发修改同一资源(如用户余额)时,通过 Redisson 提供的可重入锁限制并发更新,确保操作串行化
- 加锁(分布式锁)
- 执行更新数据库与缓存删除操作
- 解锁
RLock lock = redissonClient.getLock("user:lock:1");
lock.lock();
try {
updateDB();
redis.del();
} finally {
lock.unlock();
}1
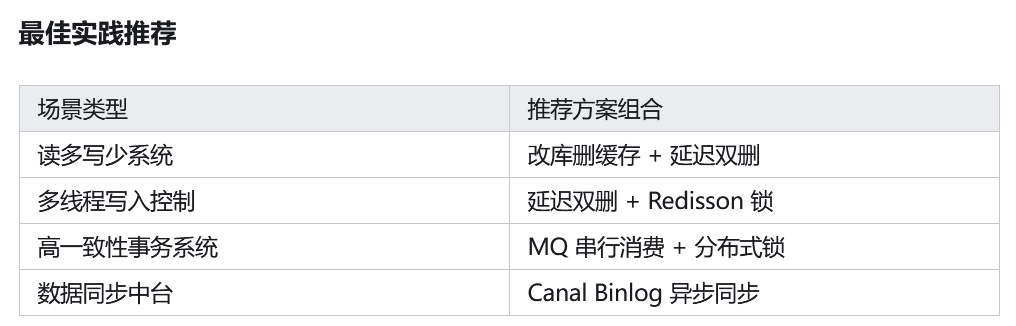
- 改库删缓存是基础,延迟双删是加强版
- Canal 和 MQ 提供企业级异步一致保障
- Redisson 锁则是并发控制的利器
redis删除策略
数据删除策略
定时删除
创建一个定时器,当key设置有过期时间,且过期时间到达时间,由定时器任务立即执行对键的删除操作
- 优点:节约内存,到时就删除,快速释放掉不必要的内存占用
- 缺点:CPU压力很大,无论CPU此时负载量多高,均占用CPU,会影响rdis服务器响应时间和指令吞吐量
- 总结:用处理器性能换取存储空间(拿时间换空间)
惰性删除
不主动删除过期键,每次从数据库访问key 时,都检测 key 是否过期,如果过期则删除该 key。
- 优点:对CPU时间友好
- 缺点:过期键占用的内存不会及时释放,造成了一定的内存浪费
定期删除
每隔一段时间「随机」从数据库中取出一定数量的 key 进行检查,并删除其中的过期key。
- 优点:通过限制删除的时长和频率,减少因为删除对cpu的占用,同时也能删除一部分过期键释放内存
- 缺点:
- 内存清理没有定时删除好,同时没有惰性删除使用的资源少
- 难以确定删除操作执行的时长和频率,如果执行的太频繁,和定时删除一样;如果执行的太少,又和惰性删除一样,占用的key不能及时释放
淘汰策略
当 Redis 内存超出物理内存限制(maxmemory)时,内存的数据会开始和磁盘产生频繁的交换(swap),使 Redis 的性能急剧下降。Redis 提供了配置参数 maxmemory 来限制内存超出期望大小。当实际内存超出 maxmemory 时, Redis 提供了几种可选策略(maxmemory-policy)来让用户自己决定该如何腾出新的空间以继续提供读写服务。
- volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
- volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
- volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
- allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
- allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
- allkeys-lfu:淘汰所有 key 中 “热度” 最低的 key。
- volatile-lfu:淘汰设置了过期时间的 key 中 “热度” 最低的 key。
- no-enviction(驱逐):禁止驱逐数据
volatile-xxx 策略只会针对带过期时间的 key 进行淘汰, allkeys-xxx 策略会对所有的key 进行淘汰。
redis持久化
RDB
Redis DataBase 给内存数据做快照
-
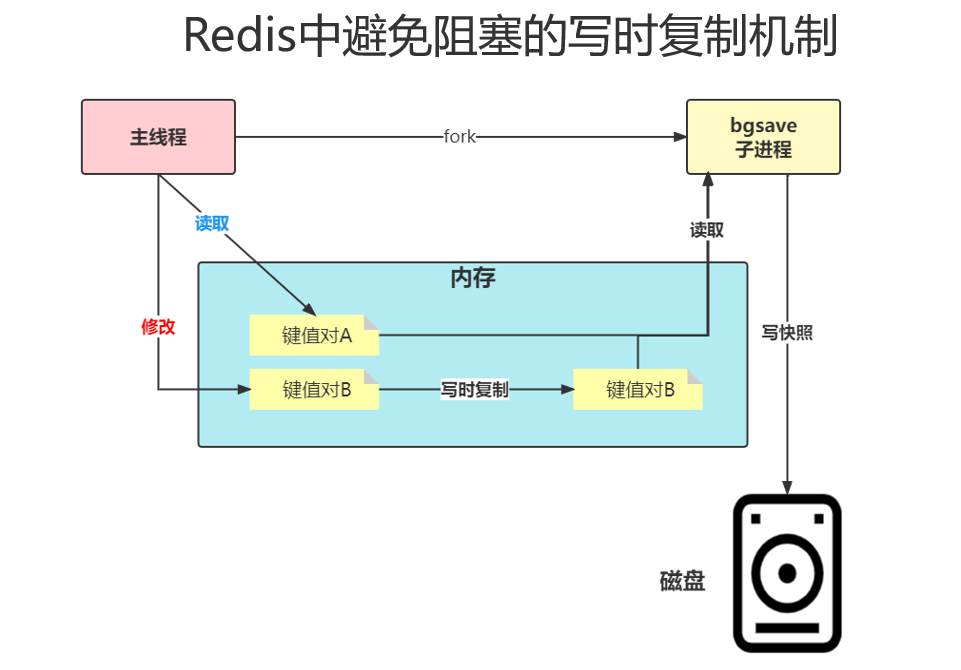
手动命令:save命令,阻塞主线程,bgsave命令,创建子进程,专门写入RDB文件,避免了主线程的阻塞
-
配置文件:满足save配置 触发bgsave
-
自动机制:关闭程序时会自动保存
-
配置文件中配置 save "" 可关闭RDB持久化
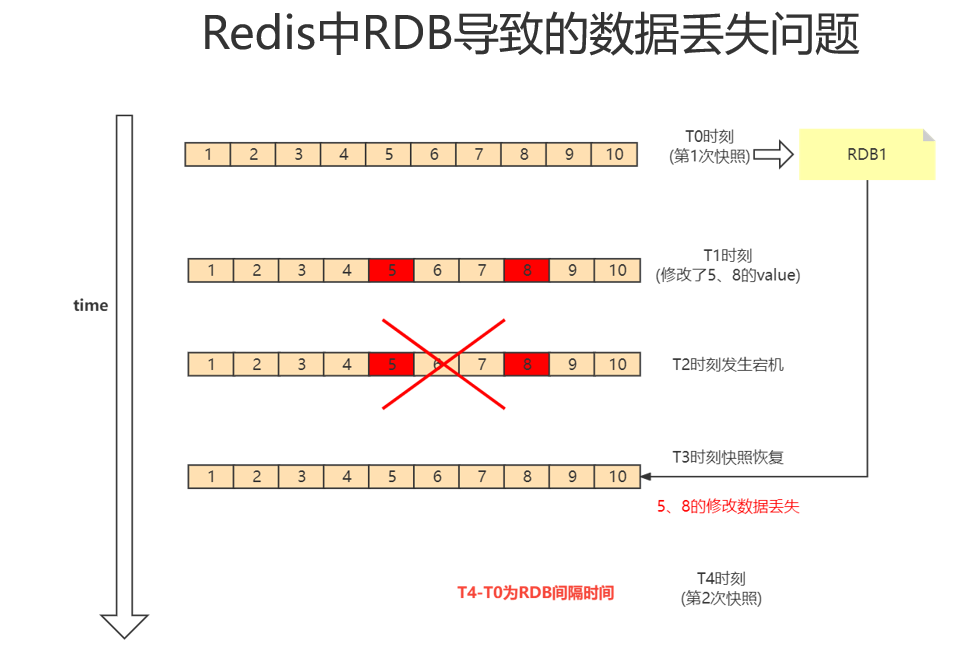
弊端:如果在两次快照的时间片期间数据修改了,并且服务宕机,可能会导致新的数据没有持久化到RDB文件
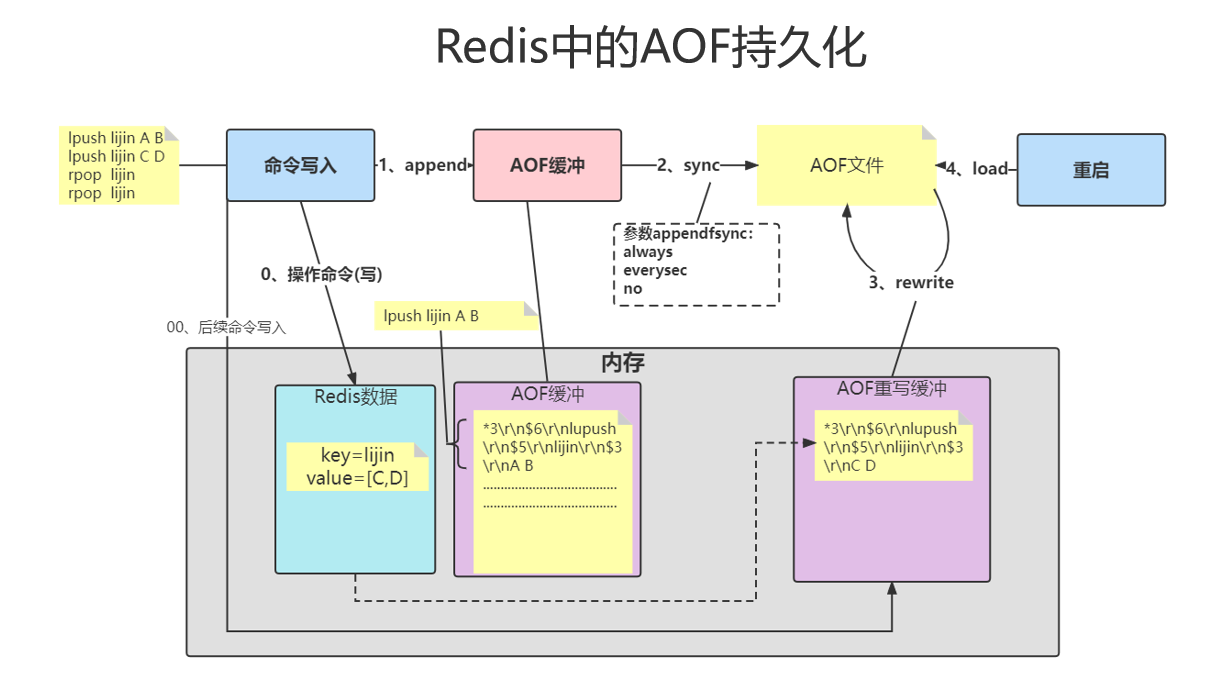
AOF
Append only File 记录每一次写操作
缓冲重写手动命令:bgrewraiteaof
缓冲重写配置文件:auto-aof-rewrite-percentage 100(上一次重写的比例) auto-aof-rewrite-min-size 64mb(触发重写的最小体积)
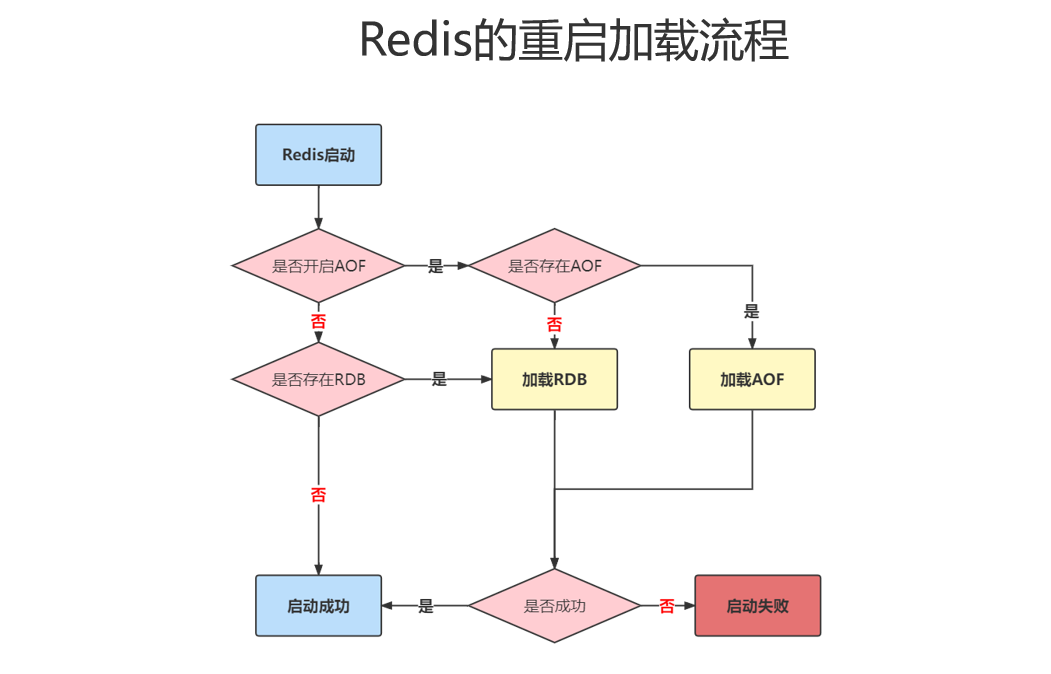
重启加载流程
锁相关
为什么需要加锁
- 对共享数据进行一个非原子性操作的时候,由于多线程竞争导致的数据不一致(线程不安全问题),使用同步解决线程的安全性问题
- 某一块代码同一时刻只想让一个线程进入
锁的分类
悲观锁
- jdk锁
- synchronized
- 作用:让方法、代码块变成同步,同一时刻只有一个线程进入
- 特点:自动获取、自动释放、适合简单的同步需求,代码简洁且不易出错。
- 原理:当线程进入同步代码时,必须先获取共享对象的监视器锁(互斥锁),如果一个线程已经获得监视器锁,其他线程必须等待,直到锁被释放,线程执行完成会释放锁,让其他资源尝试获取
- Lock:java锁的接口,常用实现类如:ReentrantLock(可重入锁)、ReadWriteLock(读写锁,通过I/O写入时需要加锁)
- 使用:
- 声明锁对象
- 加锁
- lock()方法 加锁,其他线程加不了锁就等待,
- trylock(指定时间,单位) 线程尝试获取锁,能获取到返回true 获取不到返回false不等待
- 释放锁
- 使用:
- synchronized
- 分布式锁
- redis实现分布式锁
乐观锁
-
版本号机制
给数据加一个版本号,修改的时候 where id = #{id} and version = #{version},携带修改之前查询到的版本号,并且每一次修改该数据,再版本号上加1,如果之前没有人修改过数据,版本号没有变化,可以修改成功,如果这条数据已经被人修改过,那么版本号不匹配修改会失败,可以进行重试。mybatis-plus自带乐观锁机制
-
CAS操作
CAS 是乐观锁的一种常见实现,它是通过原子操作来保证数据的一致性。CAS 操作包含三个参数:
预期值(expected value):当前变量的值。
新值(new value):想要更新的值。
目标变量(target variable):目标值,也就是需要更新的变量。CAS 会首先比较当前变量的值是否等于预期值,如果相等,则将目标变量更新为新值;如果不相等,则说明数据已经被修改,CAS 操作失败,通常会重试。
CAS 是一个原子操作,不会被中断,因此可以避免多线程访问共享资源时带来的数据不一致问题。
思维导图

本文来自博客园,作者:icui4cu,转载请注明原文链接:https://www.cnblogs.com/icui4cu/p/18892438

 浙公网安备 33010602011771号
浙公网安备 33010602011771号