4.StringAPI
本章目标
- String类
- 具体方法讲解
本章内容
String str=“张三,李四,王二麻子,刘瘸子”;
一共有多少人?
第三个人是谁?
姓王的人有哪些?
姓王的人有几个?
一、String类
String类不属性基本数据类型,它是引用类型
1、简介
String类(字符串类)的对象是一经创建便不能变动内容的字符串常量,字符串常量通常是作为String类的对象而存在的,有专门的数据成员来表明它的长度。
- 在
Java.lang包中字符常量是用单引号括起的单个字符,例如,‘A’,‘’ - 字符串常量是用
双引号括起的字符序列,例如,“A”,“”,“Java Now”等
2、创建String对象
Java语言规定字符串常量必须用双引号括起,一个串可以包含字母、数字和各种特殊字符,如+、-、*、/、$等。例如下面的语句:
System.out.println("OK!"); //其中的"OK!"就是字符串常量。
创建String类的对象
String str = "this is a string";
或
String str1 = new String("hello");
3、构造方法
| 构造方法 | 描述 |
|---|---|
String() |
初始化新创建的 String对象,使其表示空字符序列。 |
String(byte[] bytes) |
通过使用平台的默认字符集解码指定的字节数组来构造新的 String 。 |
String(byte[] bytes, Charset charset) |
构造一个新的String由指定用指定的字节的数组解码charset 。 |
String(byte[] bytes, String charsetName) |
构造一个新的String由指定用指定的字节的数组解码charset 。 |
String(char[] value) |
分配一个新的 String ,以便它表示当前包含在字符数组参数中的字符序列。 |
4、常用方法
| 方法 | 描述 |
|---|---|
charAt(int index) |
返回 char指定索引处的值。 |
compareTo(String anotherString) |
按字典顺序比较两个字符串。 |
compareToIgnoreCase(String str) |
按字典顺序比较两个字符串,忽略病例差异。 |
concat(String str) |
将指定的字符串连接到该字符串的末尾。 |
endsWith(String suffix) |
测试此字符串是否以指定的后缀结尾。 |
equals(Object anObject) |
将此字符串与指定对象进行比较。 |
equalsIgnoreCase(String anotherString) |
将此 String与其他 String比较,忽略案例注意事项。 |
getBytes() |
使用平台的默认字符集将此 String编码为字节序列,将结果存储到新的字节数组中。 |
getBytes(String charsetName) |
使用命名的字符集将此 String编码为字节序列,将结果存储到新的字节数组中。 |
indexOf(int ch) |
返回指定字符第一次出现的字符串内的索引。 |
indexOf(int ch, int fromIndex) |
返回指定字符第一次出现的字符串内的索引,以指定的索引开始搜索。 |
indexOf(String str) |
返回指定子字符串第一次出现的字符串内的索引。 |
indexOf(String str, int fromIndex) |
返回指定子串的第一次出现的字符串中的索引,从指定的索引开始。 |
lastIndexOf(String str) |
返回指定子字符串最后一次出现的字符串中的索引。 |
lastIndexOf(String str, int fromIndex) |
返回指定子字符串的最后一次出现的字符串中的索引,从指定索引开始向后搜索。 |
length() |
返回此字符串的长度。 |
matches(String regex) |
告诉这个字符串是否匹配给定的 regular expression 。 |
replace(char oldChar, char newChar) |
返回从替换所有出现的导致一个字符串 oldChar在此字符串 newChar 。 |
split(String regex) |
将此字符串分割为给定的 regular expression的匹配。 |
startsWith(String prefix) |
测试此字符串是否以指定的前缀开头。 |
substring(int beginIndex) |
返回一个字符串,该字符串是此字符串的子字符串。 |
substring(int beginIndex, int endIndex) |
返回一个字符串,该字符串是此字符串的子字符串。 |
toCharArray() |
将此字符串转换为新的字符数组。 |
toLowerCase() |
将所有在此字符 String使用默认语言环境的规则,以小写。 |
toUpperCase() |
将所有在此字符 String使用默认语言环境的规则大写。 |
valueOf(int i) |
返回 int参数的字符串 int形式。 |
valueOf(long l) |
返回 long参数的字符串 long形式。 |
二、具体方法讲解
本案例大部分基于String str="王婧,苏小雨,唐纯莉,王璐苑,姜藤椒";展开
1、一共有多少人? (贯穿项目相关)
split(String regex) 将此字符串分割为给定的正则表达式匹配。
public class Main {
public static void main(String[] args) {
String str="王婧,苏小雨,唐纯莉,王璐苑,姜藤椒";
String[] names = str.split(",");
System.out.println(names.length);
}
}
2、第三个人是谁? (贯穿项目相关)
split(String regex) 将此字符串分割为给定的正则表达式匹配。
System.out.println(names[2]);
3、姓王的人有哪些? (贯穿项目相关)
startsWith(String prefix) 测试此字符串是否以指定的前缀开头。
public class Main {
public static void main(String[] args) {
String str="王婧,苏小雨,唐纯莉,王璐苑,姜藤椒";
String[] names = str.split(",");
for (int i = 0; i < names.length; i++) {
if(names[i].startsWith("王")) {
System.out.println(names[i]);
}
}
}
}
4、查询第二个字为小的? (贯穿项目相关)
substring(int beginIndex, int endIndex) 返回一个字符串,该字符串是此字符串的子字符串
public class Main {
public static void main(String[] args) {
String str="王婧,苏小雨,唐纯莉,王璐苑,姜藤椒";
String[] names = str.split(",");
for (int i = 0; i < names.length; i++) {
System.out.println(names[i].substring(1, 2));
if(names[i].substring(1, 2).equals("小")) {
System.out.println(names[i]);
}
}
}
}
5、查询名字中包含小的? (贯穿项目相关)
contains(String str) 当且仅当此字符串包含指定的char值序列时才返回true。
public class Main {
public static void main(String[] args) {
String str="王婧,苏小雨,唐纯莉,王璐苑,姜藤椒";
String[] names = str.split(",");
for (int i = 0; i < names.length; i++) {
if(names[i].contains("小")) {
System.out.println(names[i]);
}
}
}
}
6、字符操作
String str=“at7cH63OPbQ81”;
一共由多少字符组成?
其中数字有几个?大写字母有几个?小写字母有几个?
6.1、ASCII码
(American Standard Code for Information Interchange)是一种用于计算机与其他设备之间进行数据交换的标准编码系统,使用7个二进制位来表示128个字符,包括数字、字母和常见的符号
ASCII是7位编码表,每个字符以二进制数b7b6b5b4b3b2b1表示,编码从0000000到1111111共128种,其中95个是可以打印或显示的图形符号,包括0~9十个数字、26个英文字母(大、小写)以及33个标点符号、运算符号和特殊字符
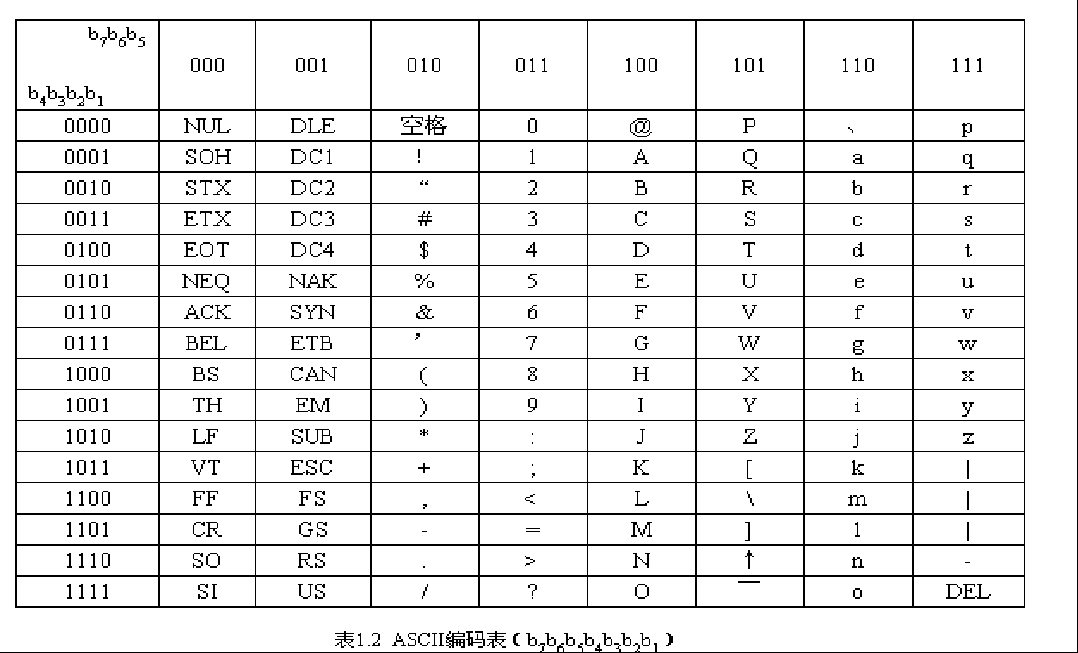
常用对照表
| ASCII值 | 控制字符 | ASCII值 | 控制字符 | ASCII值 | 控制字符 | ASCII值 | 控制字符 |
|---|---|---|---|---|---|---|---|
| 0 | NUT | 32 | (space) | 64 | @ | 96 | 、 |
| 1 | SOH | 33 | ! | 65 | A | 97 | a |
| 2 | STX | 34 | ” | 66 | B | 98 | b |
| 3 | ETX | 35 | # | 67 | C | 99 | c |
| 4 | EOT | 36 | $ | 68 | D | 100 | d |
| 5 | ENQ | 37 | % | 69 | E | 101 | e |
| 6 | ACK | 38 | & | 70 | F | 102 | f |
| 7 | BEL | 39 | , | 71 | G | 103 | g |
| 8 | BS | 40 | ( | 72 | H | 104 | h |
| 9 | HT | 41 | ) | 73 | I | 105 | i |
| 10 | LF | 42 | * | 74 | J | 106 | j |
| 11 | VT | 43 | + | 75 | K | 107 | k |
| 12 | FF | 44 | , | 76 | L | 108 | l |
| 13 | CR | 45 | - | 77 | M | 109 | m |
| 14 | SO | 46 | . | 78 | N | 110 | n |
| 15 | SI | 47 | / | 79 | O | 111 | o |
| 16 | DLE | 48 | 0 | 80 | P | 112 | p |
| 17 | DCI | 49 | 1 | 81 | Q | 113 | q |
| 18 | DC2 | 50 | 2 | 82 | R | 114 | r |
| 19 | DC3 | 51 | 3 | 83 | S | 115 | s |
| 20 | DC4 | 52 | 4 | 84 | T | 116 | t |
| 21 | NAK | 53 | 5 | 85 | U | 117 | u |
| 22 | SYN | 54 | 6 | 86 | V | 118 | v |
| 23 | TB | 55 | 7 | 87 | W | 119 | w |
| 24 | CAN | 56 | 8 | 88 | X | 120 | x |
| 25 | EM | 57 | 9 | 89 | Y | 121 | y |
| 26 | SUB | 58 | : | 90 | Z | 122 | z |
| 27 | ESC | 59 | ; | 91 | [ | 123 | { |
| 28 | FS | 60 | < | 92 | \ | 124 | |
| 29 | GS | 61 | = | 93 | ] | 125 | } |
| 30 | RS | 62 | > | 94 | ^ | 126 | ` |
| 31 | US | 63 | ? | 95 | _ | 127 | DEL |
扩展内容:
字符’1’和整数1的区别:
字符’1’是一个符号,在内存中以ASCII码对应的二进制 00110001 存放;
整数1是一个数字,在内存中以数字1的二进制的补码 00000001 存放。
6.2、基于ASCII码方式实现
Java中可通过将字符类型数据强制转换为int类型来获取对应字符的ASCII码
public class Main {
public static void main(String[] args) {
String str = "at7cH63OPbQ81";
int lowerCount = 0;
int upperCount = 0;
int numberCount = 0;
char[] charArray = str.toCharArray();
for (int i = 0; i < charArray.length; i++) {
System.out.println((int) charArray[i]);
if (charArray[i] >= 65 && charArray[i] <= 90) {
upperCount++;
}else if ( charArray[i] >= 97 && charArray[i] <= 122) {
lowerCount++;
}else if (charArray[i] >= 48 && charArray[i] <= 57) {
numberCount++;
}
}
System.out.println("小写字母有"+lowerCount);
System.out.println("大写字母有"+upperCount);
System.out.println("数字有"+numberCount);
}
}
6.3、直接比较字符
public class Main {
public static void main(String[] args) {
String str = "at7cH63OPbQ81";
int lowerCount = 0;
int upperCount = 0;
int numberCount = 0;
char[] charArray = str.toCharArray();
for (int i = 0; i < charArray.length; i++) {
if (charArray[i] >= 'A' && charArray[i] <= 'Z') {
upperCount++;
}else if (charArray[i] >= 'a' && charArray[i] <= 'z') {
lowerCount++;
}else if (charArray[i] >= '0' && charArray[i] <= '9') {
numberCount++;
}
}
System.out.println("小写字母有" + lowerCount);
System.out.println("大写字母有" + upperCount);
System.out.println("数字有" + numberCount);
}
}
7、一个字符串有多少个汉字
getBytes(String charsetName) 使用命名的字符集将此 String编码为字节序列,将结果存储到新的字节数组中
public class Main {
public static void main(String[] args) {
String str = "at7cH63OPbQ81中国";
int zhongCount = 0;
char[] charArray = str.toCharArray();
int length = str.length();
byte[] bytes = str.getBytes();
int bytesCount = bytes.length;
zhongCount = bytesCount-length;
System.out.println("中文有:"+zhongCount);
}
扩展内容:
1、常用编码
计算机中储存的信息都是用二进制数表示的;而我们在屏幕上看到的英文、汉字等字符是二进制数转换之后的结果。
- *字符(Character) :**是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。
- 字符集(Character Set/Charset):是一个系统支持的所有抽象字符的集合。由多个字符的集合,字符集种类较多,每个字符集包含的字符个数不同,字符和二进制数字的对应规则不同。常见字符集名称:ASCII字符集、GB2312字符集、BIG5字符集、GBK字符集、Unicode字符集等。
- 字符编码(Character Encoding):是一套法则,把字符集中的字符编码为特定的二进制数,以便在计算机中存储。每个字符集中的字符都对应一个唯一的二进制编码。
字符集和字符编码一般都是成对出现的,如ASCII、IOS-8859-1、GB2312、GBK,都是即表示了字符集又表示了对应的字符编码。Unicode比较特殊,有多种字符编码(UTF-8,UTF-16等)Java语言使用的字符编码有以下几种:
- ASCII编码:ASCII是一种使用7位字节来表示字符的编码方式,它包括了美国英语字母、数字和常用符号。
- ISO-8859-1编码(Latin1):ISO-8859-1是一种单字节编码,它包括了拉丁字母、希腊字母、符号和数字等,常用于西欧国家
- GB2312:是中华人民共和国国家标准简体中文字符集,共收录6763个汉字
- GBK编码:汉字内码扩展规范,全名为《汉字内码扩展规范(GBK)》1.0版,共收入21886个汉字和图形符号,其中汉字(包括部首和构件)21003个,图形符号883个
- UTF-8编码:UTF-8是Unicode的一种实现方式,它使用可变长度的字节来表示字符,能够有效地节省存储空间。UTF-8能够表示Unicode的所有字符。
- UTF-16编码:UTF-16也是Unicode的一种实现方式,它使用16位的字节来表示字符。如果字符的编码超过16位,则需要使用2个16位字节来表示。
- UTF-32编码:UTF-32编码 采用定长字节编码,对每个字符统一都使用4个字节表示。就空间而言,是非常没有效率的。
2、外码与内码
在Java中,默认的字符集是Unicode,字符的内码要用UTF-16编码,一个字符是2个字节。
内码 :Java程序在JVM中运行时,字符(char、String)在内存中的编码方式,编码方式为UTF-16BE。
也就是说,从外界进入Java世界的字符、字符串数据,无论原本的编码是什么,都会根据原本的编码和 Unicode字符集 之间的映射表,找到原本的编码对应的 Unicode代码点,然后使用 UTF-16 的编码方式存储到内存中,最后输出到外界时,根据外界指定的编码方式和 Unicode字符集之间的映射表,找到Unicode代码点映射的外界的编码输出。
外码 :除了内码,皆是外码。注意源代码编译产⽣的目标代码文件(可执行文件或class文件)的编码方式也属于外码。
Javac在编译的时候,会解析Java的源文件从而形成语法树,这个解析的过程是解析Java源文件中的一个个字面的字符(import、public、private、int等)。Java的源文件可以是任意的编码方式,就像普通的文本文件一样,而在经过编译时,先根据源文件的编码方式得到编码,然后根据编码去映射表找到所有字符的 Unicode代码点,最后根据 Unicode代码点 生成编码格式为UTF-8 (一种modified UTF-8)的class文件。
外码字符所占字节取决于具体编码。外码编码不同,字符和字节的换算不同,几种常见的编码换算如下:
ASCII编码是单字节编码,只有英文字符,不能编码汉字。
GBK编码1个英文字符是1个字节,一个汉字是是2个字节。
UTF-8编码1个英文字符是1个字节,一个汉字是3个字节。
8、贯穿案例
1、完善HRMS系统 ,添加如下功能:按关键字模糊查询人员、按下标删除人员
package com.woniuxy;
import java.util.Scanner;
public class HRMS {
public static void main(String[] args) {
//完善HRMS系统 ,添加如下功能:按关键字模糊查询人员、按下标删除人员
//用自定义函数封装内循环功能.
String[] employees = new String[5];//构造一个初始容量为5的数组
Scanner scanner = new Scanner(System.in);//构造一个接收键盘输入的对象
int index = 0;//代表当前数组的下标所在位置
System.out.println("欢迎进入人事管理系统!!!");
while(true) {
System.out.println("请选择操作:1、显示所有员工 2、添加员工 3、根据关键字模糊查询 4、根据索引下标删除 9、退出");
int operator = scanner.nextInt();
if(operator == 9) {
break;
}else if(operator == 1) {//显示所有员工的
for (int i = 0; i < arr.length; i++) {
if(arr[i]!=null) {
System.out.println("当前员工:"+arr[i]);
}
}
}else if(operator==2) {
System.out.println("请输入员工姓名");
String empName = scanner.next();
employees[index] = empName;//得到员工姓名,并添加到数组中
index++;//指向到数组的下一个坐标
}else if(operator == 3) {
System.out.println("请输入查询关键字");
String name = scanner.next();
for (int i = 0; i < employees.length; i++) {
//if条件在逻辑于的情况下,如果前面条件不成立,则不再执行后面的逻辑判断
if(employees[i]!=null&&employees[i].contains(name)) {
System.out.println(employees[i]);
}
}
}else if(operator ==4) {
System.out.println("请选择要删除的员工,选择数字");
// 调用方法
for (int i = 0; i < arr.length; i++) {
if(arr[i]!=null) {
System.out.println("当前员工:"+arr[i]);
}
}
int index2 = scanner.nextInt();
if(index2>=0&&index2<employees.length) {
employees[index2] = null;
}
}
}
System.out.println("再见!!");
scanner.close();
}
}
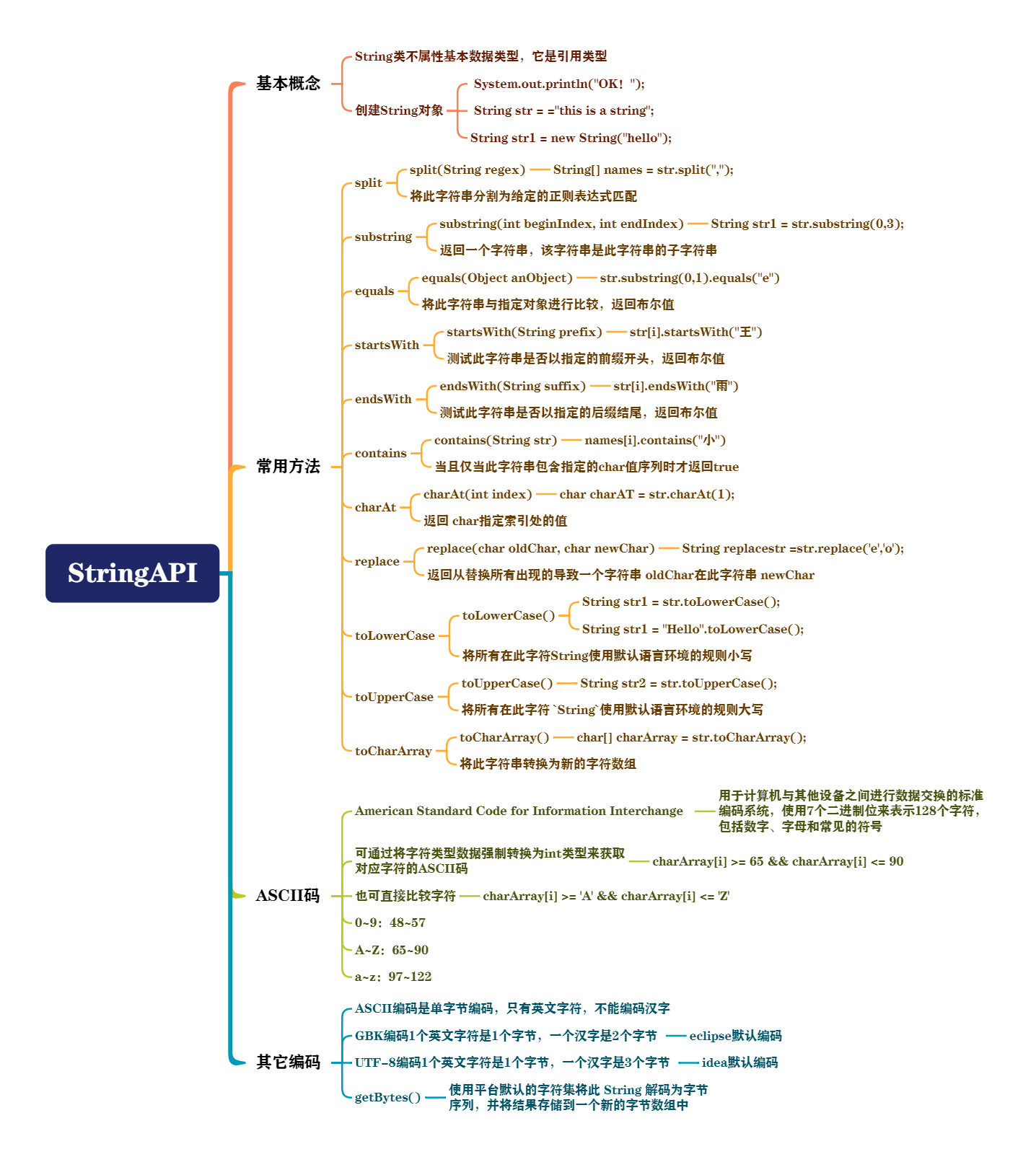
思维导图
本文来自博客园,作者:icui4cu,转载请注明原文链接:https://www.cnblogs.com/icui4cu/p/18732514

 浙公网安备 33010602011771号
浙公网安备 33010602011771号