

PySide2,爬虫,笔趣阁小说下载神器,python
基于PySide2和requests库,自行编写了一个下载笔趣阁小说的小软件,主要是练习写程序用。这个小程序里用到的基本知识点很多
包括PySide2,爬虫,多线程等,这个小程输入小说网址和小说名后会自动下载全本小说,保存在目录中。程序的界面用Qtdesigner生成,程序运行效果如下 :
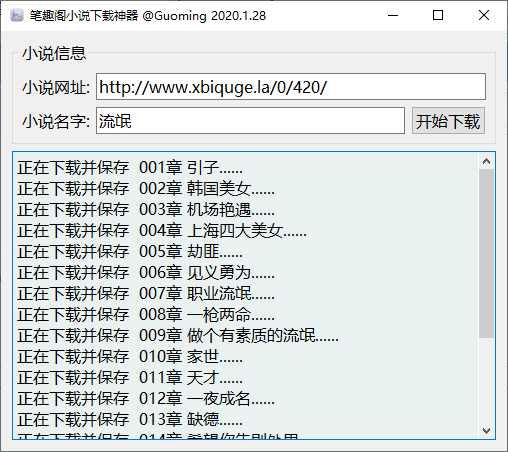
界面中各控件的变量名分别 是:小说网址--novelAddr; 小说名字---novelName; 开始下载按钮:start_Button;显示信息控件out_info
下面附上全部代码:
import requests
from lxml import etree
import os
from PySide2.QtUiTools import QUiLoader
from PySide2.QtCore import *
from PySide2.QtWidgets import *
from PySide2.QtGui import QIcon
from threading import Thread
class Novel():
def __init__(self):
qfile_stats = QFile('novel.ui')
qfile_stats.open(QFile.ReadOnly)
qfile_stats.close()
self.ui = QUiLoader().load(qfile_stats)
self.ui.start_Button.clicked.connect(self.get_info)
def get_info(self):
self.addr_head = 'http://www.xbiquge.la'
self.novel_name = self.ui.novelName.text()
self.novel_addr = self.ui.novelAddr.text()
# 自动创建小说文件夹并进入文件夹
if not os.path.exists(self.novel_name):
os.makedirs(self.novel_name)
os.chdir(os.getcwd() + '/' + self.novel_name)
else:
os.chdir(os.getcwd() + '/' + self.novel_name)
self.start()
def start(self):
th = Thread(target=self.get_text)
th.start()
# 设置要攫取小说的函数功能
def get_text(self):
# 设置请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36 Edg/88.0.705.53'}
response = requests.get(self.novel_addr, headers=headers)
response.encoding = 'utf-8'
# response.encoding = 'gbk' # 有的网站要求使用gbk编码
selector = etree.HTML(response.text)
# 获取章节标题
title = selector.xpath('//*[@id="list"]/dl/dd/a/text()')
# dd[0]是第1章....dd则是整个列表
# ('//*[@id="list"]/dl/dd[23]/a/text()') /text之前的内容是在网站上复制XPath得来的,加上/text()方法是获得此链接标题
# 获取各章具体链接
hrefs = selector.xpath('//*[@id="list"]/dl/dd/a/@href') # 获得href属性值的列表
web_list = [self.addr_head + i for i in hrefs]
for i in range(len(web_list)):
response = requests.get(web_list[i], headers=headers)
response.encoding = 'utf-8'
selector = etree.HTML(response.text)
# 获取各章具体内容
contents = selector.xpath('//*[@id="content"]/text()')
# 保存章节名称及内容
with open(self.novel_name + '.txt', 'a', encoding='utf-8') as f:
self.ui.out_info.append(f'正在下载并保存 {title[i]}......')
print(f'正在下载并保存 {title[i]}......')
f.write('\n' + title[i] + '\n')
for content in contents:
content = content.replace("\r', '\r'", '')
f.write(content)
print('完成副本小说下载!!!')
app = QApplication([])
app.setWindowIcon(QIcon('./E1.png'))
first = Novel()
first.ui.show()
app.exec_()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号