
Apache Solr初体验四
前几次我们讲到了solr的基本用法和配置文件,接下来就开始进入我们真正的代码之旅啦。
1)首先以一个简单的程序来开头:
public static void main(String[] args) throws SolrServerException, IOException, ParserConfigurationException, SAXException{
//设置solr.home,注意这时通过环境变量是solr.solr.home
System.setProperty("solr.solr.home","E:\\solr");
//初始化容器,让它加载solr.home的配置文件
CoreContainer.Initializer initializer = new CoreContainer.Initializer();
CoreContainer coreContainer = initializer.initialize();
EmbeddedSolrServer solrServer = new EmbeddedSolrServer(coreContainer,"");
//构造参数列表
SolrQuery solrQuery = new SolrQuery();
Map<String,String> map = new HashMap<String,String>();
map.put(FacetParams.FACET_DATE, "manufacturedate_dt");
map.put(FacetParams.FACET_DATE_START,"2004-01-01T00:00:00Z");
map.put(FacetParams.FACET_DATE_END,"2010-01-01T00:00:00Z");
map.put(FacetParams.FACET_DATE_GAP,"+1YEAR");
map.put("indent","on");
map.put("wt","xml");
map.put("hl.fl","name");
SolrParams params = new MapSolrParams(map);
solrQuery.add(params);
solrQuery.setFacet(true);
solrQuery.setFields("name,price,score");
solrQuery.setQuery("solr");
solrQuery.setSortField("price",SolrQuery.ORDER.asc);
solrQuery.setHighlight(true);
System.out.println(solrQuery.toString());
QueryResponse queryResponse = solrServer.query(solrQuery);
System.out.println(queryResponse.toString());
System.out.println("共找到:"+queryResponse.getResults().getNumFound()+"个结果");
//解析返回的参数
SolrDocumentList sdl = (SolrDocumentList)queryResponse.getResponse().get("response");
for (int i = 0; i< sdl.size(); i++){
Object obj = sdl.get(i).get("manufacturedate_dt");
String date = "";
if (obj!= null){
date = new SimpleDateFormat("yyyy-MM-dd").format((Date)obj);
}
System.out.println(((SolrDocument)sdl.get(i)).get("name")+":"+date+":"+(sdl.get(i).get("price")));
}
}
这时我们所用到的是EmbeddedSolrServer,它是用于嵌入式地solr服务,这里我们不需要向外提供服务,所以我们就用到这个。另外有一个
CommonsHttpSolrServer这个类是用于发送指令的服务,例如我们需要发送HTTP命令来查询,就可以用这个。
下面我们分析一下代码,首先,我们设置了一个环境变量的名称为solr.solr.home,是这个,你没看错,确实是要这样。接下来我们初始化容器,让它加载solr.home的配置文件等。接下来的一系统代码就是构造参数列表。
我们构造完成后的参数列表是这样的:facet.date.start=2004-01-01T00%3A00%3A00Z&indent=on&facet.date=manufacturedate_dt&hl.fl=name&facet.date.gap=%2B1YEAR&wt=xml&facet.date.end=2010-01-01T00%3A00%3A00Z&facet=true&fl=name%2Cprice%2Cscore&q=solr&sort=price+asc&hl=true
跟我们直接在浏览器输入的不太一样,因为它是进行过编码的。构造完成后我们就可以用solrServer进行查询了。
查询得到的结果是JSON格式的,注意,通过程序来查询得到的都是JSON格式,而不是XML格式,不过这样更好,方便我们进行接下来的解析。
接下来的代码就是解析内容啦,应该很容易看懂的。
2)接下来的我们就尝试自己写一个程序来进行索引,而不用post.jar。
程序代码如下:
public static void main(String[] args) throws IOException, ParserConfigurationException, SAXException{
System.setProperty("solr.solr.home","e:\\solrIndex");
//这下面三行代码主要是用于加载配置文件
SolrConfig solrConfig = new SolrConfig("E:\\solrIndex\\conf\\solrconfig.xml");
FileInputStream fis = new FileInputStream("E:\\solrIndex\\conf\\schema.xml");
IndexSchema indexSchema = new IndexSchema(solrConfig,"solrconfig",fis);
SolrIndexWriter siw = new SolrIndexWriter("solrIndex","E:\\solrIndex",new StandardDirectoryFactory()
,true,indexSchema);
Document document = new Document();
document.add(new Field("text","测试一下而已",Field.Store.YES,Field.Index.ANALYZED,Field.TermVector.WITH_POSITIONS_OFFSETS));
document.add(new Field("test_t","再测试一下而已",Field.Store.YES,Field.Index.ANALYZED,Field.TermVector.WITH_POSITIONS_OFFSETS));
siw.addDocument(document);
siw.commit();
siw.close();
SolrCore solrCore = new SolrCore("E:\\solrIndex",indexSchema);
SolrIndexSearcher sis = new SolrIndexSearcher(solrCore,indexSchema,"solrIndex",
new StandardDirectoryFactory().open("E:\\solrIndex"),true);
TopDocs docs = sis.search(new TermQuery(new Term("test_t","再")),1);
System.out.println("找到"+docs.totalHits+"个结果 ");
for (int i = 0; i < docs.scoreDocs.length; i++) {
System.out.println(sis.doc(docs.scoreDocs[i].doc).get("test_t"));
}
}
代码不难理解,所以就没写注释了。主要是那段加载配置文件的代码。接下来是添加索引,然后是查询索引,删除的比较简单,直接一句代码
solrServer.solrServer.deleteById("SOLR1000");
或者
solrServer.deleteByQuery()
都比较简单。
3)接下来我们讲一下,很可能会在项目中用到的,就是中文分词,中文分词有蛮多的,有IK,Paoding,mmseg4j,还有另外一些中科院什么地方的。但个人建议用IK或者mmseg4j,这两个有solr都有比较直接的支持,paoding也可以,但可能需要自己写类继承BaseTokenizerFactory然后再进行配置,不难。
上面的例子就是用到中文分词了,如果你发现找不到结果,那很正常,因为还没添加中文分词,你可以把中文改成英文,再查一下,就可以查出来了。
需要添加中文分词,我们要在schema.xml中做文章。找到types标签,在里面找到你想要进行中文分词的类型,比如text类型,我们想要让它的内容用中文分词来进行分析,可以进行配置:
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.solr.IKTokenizerFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="stopwords.txt"
enablePositionIncrements="true"
/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="1" catenateNumbers="1" catenateAll="0" splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.SnowballPorterFilterFactory" language="English" protected="protwords.txt"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.solr.IKTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="stopwords.txt"
enablePositionIncrements="true"
/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="0" catenateNumbers="0" catenateAll="0" splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.SnowballPorterFilterFactory" language="English" protected="protwords.txt"/>
</analyzer>
你可以先不理解filter的那些东西,但你一定要理解tokenizer这些地方的配置,它配置了你想要应用的分词器,它必须继承于BaseTokenizerFactory。我们看到analyzer有一个type属性,它表示你要在哪个阶段运用此分词器,如果索引和查询都要用,我们可以不写type,这样solr就会在索引和查询时都使用此分词器,这样配置完成后就可以进行中文分词的测试啦。我们重新把上面的例子添加中文进行索引,然后查询出来,看有没有问题。我的运行结果如下:
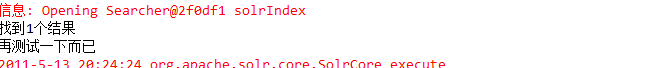
我们找到了结果,证明我们的中文分词已经没问题了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号