
【以及迁移到GIT不再维护】【设计篇】领域驱动设计(DDD)笔记
前言:
本文整理学习DDD的核心知识点,DDD其实更多事一种最佳实践,只是提出了设计其中的侧重点,DDD难的是坚持做下去;领域驱动设计只有应用在大型项目上才能产生最大的收益,而这也确实需要高超的技巧;而简单的项目,用smart ui就搞定了。
第一章:运用领域模型
1.1 知识是核心:
DDD的整个过程就是通过消化知识(领域知识)和持续学习,把模型作为唯一表达的工具,力求模型的设计和演进是冲着知识丰富的方向发展的。但这种知识丰富又必须是要和问题域相使用的,不易太多,也不易太少;
1.2 统一建模语言:
领域专家的语言和技术的语言是难以沟通的,为了让模型的设计和真实问题域(领域)保证一致,我们必须需要创造一种新的语言出现,该语言目的是为了统一领域专家和技术人员的沟通,所以叫统一建模语言;
- 统一建模语言以模型为支柱,文档和图都只是辅助手段;
- 统一建模语言刚开始都是比较简单的,不清晰的,需要团队努力去把它丰富起来,并且形成共识;
- 统一建模语言是创建语言的过程,其结果必须要用代码模型来反映,统一语言的更改就是对模型的更改;
- 必要的时候,可以引入解析性模型来表达一下统一建模的结果,这种解析性模型和统一建模不是一回事;
通用语言指导程序设计:有时候你会纠结一个逻辑是放到实体中,还是放到领域服务中,通用语言可以指导你,如果是步骤则放到领域服务中。
- 通用语言可以指导领域服务、实体、值对象、事件等的建模
1.3 绑定模型和实现:
如果程序设计的核心和领域模型式分离的,那么这个模型就是没有用的;如果模型和实现不一致,而是靠一堆映射关系维护的,特别复杂的时候,这种关系也会出事
- 某种情况下我们确实用到了模型去讨论问题,但却没有做到模型和实现的一致性
- 很多时候我们做的事分析模型,分析模式事帮助理解的,这个和程序设计也无法仅仅绑定
- 很多人犯的病就是,写代码的时候,就往往把模型放在一边,但有能力的人能分辨不好模型,在自己思考下写出正确的模型,这倒是可以的
1.4 建模范式和实现:
不是所有语言都支持领域建模,函数式编程和面向对象编程,我们会选用后者的范式的语言;
1.5 纯粹的OOD:
DDD和OOD是有关系的,其实DDD就是很纯粹的OOD,属于其子集,到底多纯粹呢,就是完全按照领域知识去设计一个面向对象的系统,其中最重要的是:知识,为了达到这种纯粹,就必须要排除杂质,分别有一下几种:
- 排除计算机的知识,所以有了基础设施层;
- 排除其他领域的知识,于是有了反腐层;
- 细化一点,排除了数据库知识,于是有了仓储层、工厂;
- 有一套DDD框架,如聚合根,实体,值对象,以此对领域进行OOD分析;
第二章:驱动设计的构造块
2.1 分层架构:
分层架构的本质,是在写一段逻辑的时候,你应该思考这段逻辑是什么,应该写在哪里:例子:发邮件,基础设施层用service提供发邮件功能,但触发发邮件可能是应用层,也可能是领域层
- 分层是为了做到关注点分离的,所以不要让领域逻辑和领域知识在其他地方(用户界面、数据库脚本)等得到表达;
- 大多数成功的架构都是以下的变体:
- 用户界面层
- 应用层
- 领域层
- 基础设施层
- 把领域层分离出来才是关键,其中什么六边形都是变体;
- 各层之间应该是松散的,上层可以依赖下层接口,不能反过来;
2.2 基本建模元素:
关联、实体(Entity)、值对象(Value Object)、服务(Service)、模块(Package)、对象范式;概念都很简单,主要提一下比较有意思的:
服务(Service):
- (服务)我们的建模范式是对象,但不是所有逻辑都要放在实体中,因为有时候对象,并不是一个事物,不如把他们放在服务中;
- (服务)所以有些领域概念和逻辑,或许不适合放在某个Entity中,这个时候不要扭曲,放在Service中吧;
- (服务)Service往往以一个活动来命名;参数和结果,应该是领域对象;也就是这个接口往往是由其他领域元素组合而成的,例如接口名称应该使用模型语言
- (服务)操作应该是无状态的;
- (服务)不同的层有不同的服务,应用层的service、领域层的service、基础设施层的service;要注意区分
2.3 领域对象生命周期:
聚合:
DDD最重要的概念,首先是聚合、还有聚合根
聚合,可以理解为多个对象的集合,数据事务修改的基本单元;
它通过定义对象之间清晰的所属关系和边界来实现领域模型的内聚,并避免了错综复杂的难以维护的对象关系网的形成。聚合定义了一组具有内聚关系的相关对象的集合,我们把聚合看作是一个修改数据的最小原子单元。
- 聚合最大的作用是维护聚合内规则的一致性;
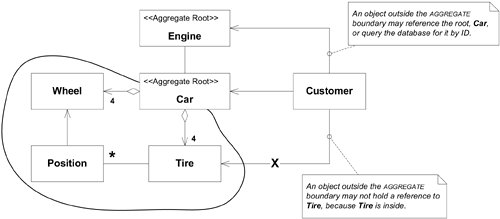
聚合根:
聚合根,每个聚合都有一个根对象,根对象管理聚合内的其他子对象(实体、值对象);聚合之间的交互都是通过聚合根来交互,不能绕过聚合根去直接和聚合下的子实体进行交互。
上面的例子中,Car、Wheel、Position、Tire四个对象构成一个聚合,其中Car是聚合根;Customer也是聚合根,Customer不能直接访问Car下的Tire(子实体),而是只能通过聚合根Car来访问。
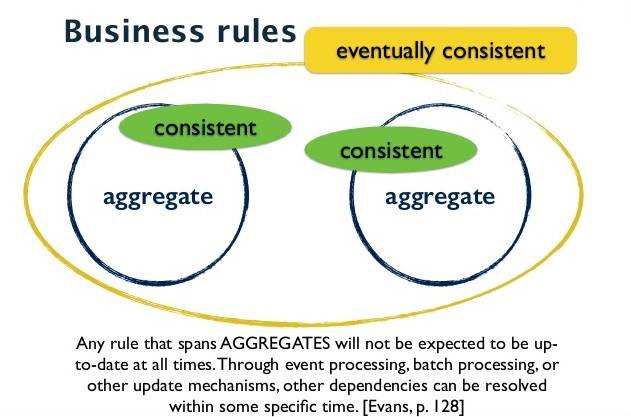
聚合的一致性:Eventual Consistency
上面表达了一个关于聚合的一致性设计原则:聚合内的数据修改,是ACID强一致性的;跨聚合的数据修改,是最终一致性的。遵守这个原则,可以让我们最大化的降低并发冲突,从而最大化的提高整个系统的吞吐。
模式:工厂(Facttory):
因为聚合的规则,可能会使得聚合的创造十分复杂,创建过程不能暴露出去,所以最好是使用工厂封装它;
- 工作封装了创建复杂对象或者聚合所需的知识、维护复杂的创建和组合规则;
- 分离创建过程和运行过程(这个我在多篇文章中有提及);
- 工厂本身可能不承担领域模型的职责;
- 工厂方法通常是产生那些多态的对象,这点要注意;
工厂还是工厂方法?
- 当有些细节需要隐藏又找不到位置时,单独创建一个工厂对象,通常聚合根都需要一个单独的工厂;
- 有时候可能一个对象的创建和另一个对象(通常是聚合内的聚合根)的数据密切关联,那么可以在另一个对象上面加工厂方法;
不需要工厂?
确实,有时候你不需要工厂,或者直接用构造器等方式:
- 类是一种类型,没有通过接口实现多态性;
- 客户关心的是实现,客户可以访问对象的所有属性;
- 构造并不复杂;
模式:重建(rebuild)的工厂
有一些工厂他们不是创建对象,而是重建储存的对象,这类工厂称之为重建工厂,他们的参数必须要有Entity的标识作为参数;
模式:仓储
仓储是隔离数据库的一种概念层
- 仓储对象是某种类型的所有对象在内存中的替身
- 只为那些确实需要直接访问的聚合根提供仓储,让客户聚焦于模型
- 将事物的控制权留给客户
- 可以和Factory合作使用,重建对象
第三章:通过重构来加深理解
3.1 深层模型
消化知识,然后通过重构来挖掘深层模型,加深理解,进行一次次的突破的过程;
- 因为需要重构,两顶帽子必然要常用,所以我们需要柔性设计,保证软件在不过度设计下健康演进;
- 通常深层次的模式不是慢慢得到的,而是多次重构后突破的;
3.2 概念挖掘
传统的概念挖掘是,寻找文档中的名词和动词,转换为领域对象,这种事最简单的用法,初级的用法;
隐含概念显式化:约束
领域概念都很重要,消化知识,寻找深层模型,很多时候是通过识别出某个隐含概念达成的。隐含概念:例如一些约束(通常是一小段代码);把这种隐含概念显式的表达出来,可能就是一次突破;显式表达就是提出方法、提取类,而提取类一半就是这个约束的数据已经和宿主类无关了;
思考矛盾之处
不同的领域专家都会有不同的表达,有时候我们会发现领域中的矛盾,而解决这些矛盾,会为找到深层模型提供重要的线索;
把过程建模为对象:Service
过程很认为是实体对象要封装的,但其实不一定,领域过程很多是可以单独封装为Service对象的;而且当过程可以视为算法的时候,更有趣;
3.3 规格:Specification
业务规则,很多时候是不适用于放在实体对象中的,而且规则的变化通常要求组合和变换;
我这里特别的把规格提出来,规格模式是非常有用的:
- 验证对象,检查它是否满足某个需求或者为了满足某个目标做好了准备;
- 从集合中选一个对象;
- 指定在创建新需求的时候必须满足某种需求;
规格与选择
可以通过规格过滤集合,验证对象
规格与仓储
规格与仓储的组合是非常搭配的,查找什么样的对象,把对象的规格传入即可;另外SQL的查询和规格也是天然匹配,如果可以通过关系映射的params来操纵sql,达到把规格代码放在基础设施层,是比较好的实践;
规格与工厂
这个是规格的第三种用法,传入规格给工厂,工厂产生对应规格的产品,是一种即可完美的领域解析。
3.4 柔性设计
设计不仅是为使用软件的客户服务,也为维护软件修改代码的人服务,柔性设计主要通过减少依赖性和副作用来减轻人们的思考负担,柔性设计是对深层模型的补充,一旦我们挖掘出隐含概念,并把他们显式地表达出来后,我们便有了原料,柔性设计的理论很多,作者精选了一些模式出来;
释意命名选择器(Intention-revealing selection)
在命名类和操作的时候要描述他们的效果和目的,而不要表露他们是通过何种方式达到目的的,名称最好统一建模语言保持一致
无副作用函数
操作可以分为两类,查询和命令;命令通常是有副作用的,当系统复杂的时候,其各种命令规则的组合是很难预测的,同时人要关心的也很多,怎么解决这个问题呢?
返回结果而不产生副作用的称之为函数;函数可以很方便的互相嵌套而不担心副作用,因为状态总是在入参和出参中定义;
如果选用函数、命令、查询呢?
- 如果一个操作把逻辑或者计算和状态变更混合在一起,那么我们应该把这个操作重构为两个操作,一个做计算、另一个做简单的状态变更;
- 如果分离出来的逻辑或者计算非常复杂,那么把这段分离出来的代码再派生一个value object,把该逻辑封装进去;
断言
虽然函数能帮忙解决一部分问题,但还是不能避免会有副作用的命令存在的;那怎么办呢?把副作用断言是一种提示给使用者一个操作有啥副作用的一种很好的实践;
概念轮廓(conceptual overload)
通过重构获得一组稳定的概念(类、方法、模块)并沉淀为概念集合,该集合使得领域应对需求更稳定,更柔性;这些集合描述了这个领域的图像(轮廓),其中反复的重构和推磨,高内聚低耦合起了很关键的作用;
———***———
Intention-revealing selection使得客户能够把对象表示为有意义的单元,而不仅仅是一些机制,函数和断言可以让我们安全的使用这些单元,并对他们进行复杂的组合,概念轮廓的出现可以模型各个部分变得更稳定,也是的这些单元更直观更易于使用和组合。
声明式设计
声明式设计和规格可以比较好的吻合,多个规格可以组合,其实就比较像过滤器(Criteria)模式,但规格会更具有领域含义,属于领域模式
应用设计模式
- 设计模式更多是场景合适才好用,在应用在领域模式的时候,其侧重点则是表示概念的能力
- 在领域中应用任何一种设计模式的时候,首先关注的问题应该是模式的意图是否确实适合领域概念
重构来加深理解
与传统重构不同的是,即使在代码看起来很整洁的时候,也可能需要重构,原因是模型的语言没有与领域专家保持一致;或者新需要不能自然地加到模型中。
第四章:战略设计
4.1 保持模型的完整性
界限上下文 待续~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号