

操作系统实验——OpenEuleros02
实验过程
任务一 使用kmalloc分配内存
- 先写一个脚本文件run.sh,避免重复的工作:
run.sh
pushd ../../ git pull popd make run |
修改Makefile文件如下:
ifneq ($(KERNELRELEASE),) obj-m := kmalloc.o else KERNELDIR ?= /usr/lib/modules/$(shell uname -r)/build PWD := $(shell pwd) default: $(MAKE) -C $(KERNELDIR) M=$(PWD) modules endif .PHONY:clean clean: -rm *.mod.c *.o *.order *.symvers *.ko run: @make @insmod kmalloc.ko @rmmod kmalloc.ko |
只需要在/data/workspace/myshixun/exp1/task1路径下使用./run.sh命令即可执行全部需要执行的操作。
- 编写kmalloc.c内核模块,调用kmalloc()函数分别为kmallocmem1和kmallocmem2分配1KB和8KB大小的内存空间并使用printk() 打印指针地址;
printk(KERN_ALERT "Default Max is 0x%lx", KMALLOC_MAX_SIZE); // 16进制表示最大内存空间 400000 10进制数为4194304 即2^22 printk(KERN_ALERT "Start kmalloc!\n"); kmallocmem1 = (unsigned char*)kmalloc(1 << 10, GFP_USER); if(kmallocmem1 == NULL) { printk(KERN_DEBUG "Failed to allocate kmallocmem1"); } else { printk(KERN_ALERT "kmallocmem1 addr = 0x%p\n", kmallocmem1); } kmallocmem2 = (unsigned char*)kmalloc(1 << 13, GFP_USER); if(kmallocmem2 == NULL) { printk(KERN_DEBUG "Failed to allocate kmallocmem2"); } else { printk(KERN_ALERT "kmallocmem2 addr = 0x%p\n", kmallocmem2); } kfree(kmallocmem1); kfree(kmallocmem2); |
如上述代码所示,调用kmalloc函数为kmallocmem1分配1<<10B大小的空间,1<<10B = 1024B = 1KB;
kmalloc函数原型为:void * kmalloc(size_t size, gfp_t flags);
调用kmalloc函数需要两个参数,size表示需要申请空间的大小,flags表示需要分配的内存的种类。
这里flags我选择了GFP_USER,它表示分配代表用户分配内存:

为kmallocmem2分配内存的方式和kmallocmem1一样,只不过将分配的内存大小改为了1 << 13B,即8KB。
判断是否分配成功,可以通过判断kmallocmem是否等于NULL来实现,若调用kmalloc函数分配内存后仍为NULL,则说明分配失败,就调用pirntk打印"Failed to allocate kmallocmem";若不等于NULL,则说明分配成功,调用printk打印指针的地址。
- 测试kmalloc()可分配的内存大小是否有上限,若有,则寻找kmalloc()申请内存的上限,为kmallocmem3申请最大可分配上限的内存空间,在实验报告中描述你是如何确定该上限的,并使用printk() 打印指针地址;同时为kmallocmem4申请比最大可分配上限稍大的内存空间;
先放出代码:
do { kmallocmem3 = (unsigned char*)kmalloc(kmalloc_size, GFP_USER); if(check_alloc_state(kmallocmem3, 3)) { printk(KERN_ALERT "kmalloc for 0x%x space succeed\n", kmalloc_size); } else { printk(KERN_ALERT "kmalloc for 0x%x space failed\n", kmalloc_size); break; } shift++; kmalloc_size = 1 << shift; kfree(kmallocmem3); } while(kmallocmem3 != NULL && shift < 32); kmalloc_size >>= 1; printk(KERN_ALERT "The maximum space that can be allocated is 0x%x\n", kmalloc_size); kmallocmem3 = (unsigned char*)kmalloc(kmalloc_size, GFP_USER); printk(KERN_ALERT "kmallocmem3 addr = 0x%p\n", kmallocmem3); kfree(kmallocmem3);
do { kmallocmem4 = (unsigned char*)kmalloc(kmalloc_size + extern_size, GFP_USER); if(check_alloc_state(kmallocmem4, 4)) { printk(KERN_ALERT "kmalloc for 0x%x space succeed\n", kmalloc_size + extern_size); } else { printk(KERN_ALERT "kmalloc for 0x%x space failed\n", kmalloc_size + extern_size); break; } extern_size++; kfree(kmallocmem4); } while(kmallocmem4 != NULL); printk(KERN_ALERT "Try to allocate 0x%x space for kmallocmem4...\n", kmalloc_size + extern_size); kmallocmem4 = (unsigned char*)kmalloc(kmalloc_size + extern_size, GFP_USER); if(kmallocmem4 != NULL) { printk(KERN_ALERT "kmallocmem4 addr = 0x%p\n", kmallocmem4); kfree(kmallocmem4); } else { printk(KERN_ALERT "Failed to allocate 0x%x space for kmallocmem4\n", kmalloc_size + extern_size); } |
下面对代码做出解释:
- 确定可分配的内存大小的上限:
这里我在做实验的时候出现了一个比较巧合的情况,我在程序中define了一个KMALLOC_MAX_SIZE,但是这个已经在linux内核代码中被define过了,于是编译的时候出现了warning:


所以我就先将这个KMALLOC_MAX_SIZE打印了一下,如下:
printk(KERN_ALERT "Default Max is %lx", KMALLOC_MAX_SIZE); |

从这里可以预先看到kmalloc()可以分配的内存大小是有上限的,这个上限用十六进制表示为0x400000。接下来我就编写代码验证我的猜想是否正确。
在代码中,可以看到我定义了一个int类型变量shift,表示左移的位数,其初始值为10;然后定义一个变量kmalloc_size为每次尝试用kmalloc()分配的空间大小,kmalloc_size初始值为1<<shift,即1<<10亦即1024;然后使用do_while循环,每次尝试分配kmalloc_size大小的内存,若分配成功则继续将shift加一,然后将kmalloc_size赋值为1<<shift,还要记得将分配的内存空间释放掉。循环结束的条件是kmallocmem3==NULL || shift>=32,kmallocmem3==NULL的终止条件比较好理解,因为当kmallocmem3==NULL时,即表示分配内存失败了,退出循环;那么为什么当shift>=32时也终止呢?这是因为之前查看KMALLOC_MAX_SIZE可以看到,kmalloc可以分配的最大内存大概为1<<22B,当shift>=32时,大概率是执行出错了,这时候也退出。
因为退出的时候得到的是不能被分配的最小内存,那么要得到可以被分配的最大内存,这里需要让shift减1,再重新尝试分配。分配给kmallocmem3最大可分配内存成功后,再打印kmallocmem3指针的地址,最后将分配的内存空间释放,防止内存泄露。
运行结果如下:
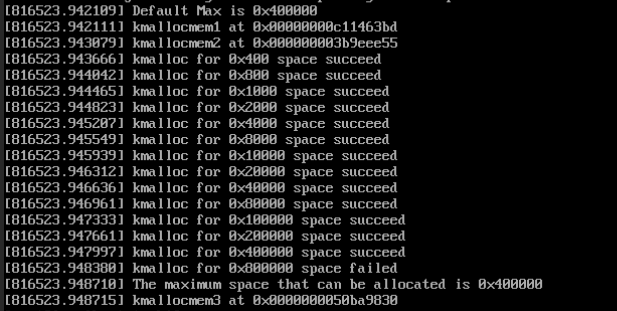
- 之后为kmallocmem4分配比能分配的最大空间再大一点的空间,这里再次使用一个do_while循环,逻辑和为kmallocmem3分配内存差不多,只不过不是将每次分配的内存大小左移一位,而是每次加1,最后得到的结果是一次循环都没有执行,只执行了一次do就退出了:
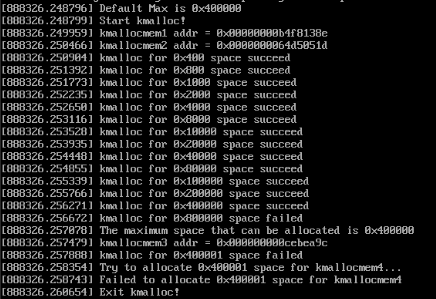
可以看到为kmallocmem4分配超过最大可分配大小的内存一点点也失败了。这也印证了一开始打印出KMALLOC_MAX_SIZE并猜测它就是能分配的最大内存大小是正确的。
- 根据机器是32位或者是64位的情况,分析分配结果是否成功以及地址落在的区域,并给出相应的解释
64位机器的最大地址为2^64-1=0xFFFFFFFFFFFFFFFF,故可以从图上看到对kmallocmem1、kmallocmem2以及kmallocmem3均分配成功,对kmallocmem4分配失败。
任务二 使用vmalloc分配内存
- 编写vmalloc.c内核模块,调用vmalloc() 函数分别为vmallocmem1、vmallocmem2、vmallocmem3分配8KB、1MB和64MB大小的内存空间并使用printk() 打印指针地址;
这个比较简单,只需要调用vmalloc就可以了,需要注意的是vmalloc和kmalloc不同,它只需要一个参数,即需要分配的内存大小:

所以在函数实现时,只需要传一个需要分配的内存大小即可,更简单了。实现的逻辑和任务一差不多,只不过分配的内存空间大小不一样而已,8KB为1<<13、1MB为1<<20、64MB为1<<26:
printk(KERN_ALERT "Start vmalloc!\n"); vmallocmem1 = (unsigned char*)vmalloc(1 << 13); // vmallocmem1 分配8KB if(vmallocmem1 == NULL) { printk(KERN_DEBUG "Failed to allocate vmallocmem1\n"); } else { printk(KERN_ALERT "vmallocmem1 addr = 0x%p\n", vmallocmem1); } vmallocmem2 = (unsigned char*)vmalloc(1 << 20); // vmallocmem2 分配1MB if(vmallocmem2 == NULL) { printk(KERN_DEBUG "Failed to allocate vmallocmem2\n"); } else { printk(KERN_ALERT "vmallocmem2 addr = 0x%p\n", vmallocmem2); } vmallocmem3 = (unsigned char*)vmalloc(1 << 26); // vmallocmem3 分配64MB if(vmallocmem3 == NULL) { printk(KERN_DEBUG "Failed to allocate vmallocmem3\n"); } else { printk(KERN_ALERT "vmallocmem3 addr = 0x%p\n", vmallocmem3); } vfree(vmallocmem1); vfree(vmallocmem2); vfree(vmallocmem3); |
- 根据在任务一中找到的kmalloc内存分配上限,为vmallocmem4分配比该上限稍大的内存;
直接定义一个变量vmalloc_size为(1<<22)+1,尝试使用vmalloc为vmallocmem4分配一个vmalloc_size大小的内存,这里vmallocmem4没有被定义,需要自己定义一下:
printk(KERN_ALERT "Try to allocate 0x%x space for vmallocmem4...\n", vmalloc_size); vmallocmem4 = (unsigned char*)vmalloc(vmalloc_size); // vmallocmem3 分配64MB if(vmallocmem4 == NULL) { printk(KERN_DEBUG "Failed to allocate vmallocmem4\n"); } else { printk(KERN_ALERT "Allocate successfully!\n"); printk(KERN_ALERT "vmallocmem4 addr = 0x%p\n", vmallocmem4); vfree(vmallocmem4); } |
最后都要记得释放已分配的内存。
运行结果如下:
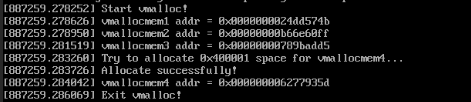
对输出结果的解释:
- 首先对vmallocmem1没有什么需要多加解释的,因为本身它要求分配的内存就只有8KB,而8KB小于1<<22,所以它能够成功地分配内存。
- 接下来对vmallocmem2分配1MB的内存。1<<22为4MB,8KB+1MB小于4MB,故它能成功分配也是毋庸置疑的。
- 最后对vmallocmem3分配64MB的内存,这个需要解释一下,为什么64MB比4MB大那么多,它还能够成功分配呢?原因在实验指导中也有提及:

kmalloc分配的是物理空间的地址,而vmalloc分配的是虚拟空间的地址,所以vmalloc可以分配的内存空间大小远远大于kmalloc能分配的内存空间大小。
应用程序通过vmalloc分配内存,分配的是虚拟内存,此时并不会分配物理内存。
当应用程序读写了这块虚拟内存,CPU 就会去访问这个虚拟内存, 这时会发现这个虚拟内存没有映射到物理内存,CPU 就会产生缺页中断,进程会从用户态切换到内核态,并将缺页中断交给内核的 Page Fault Handler (缺页中断函数)处理。
- 根据机器是32位或者是64位的情况,分析分配结果是否成功以及地址落在的区域,并给出相应的解释
32 位操作系统和 64 位操作系统的虚拟地址空间大小是不同的,在 Linux 操作系统中,虚拟地址空间的内部又被分为内核空间和用户空间两部分,如下所示:
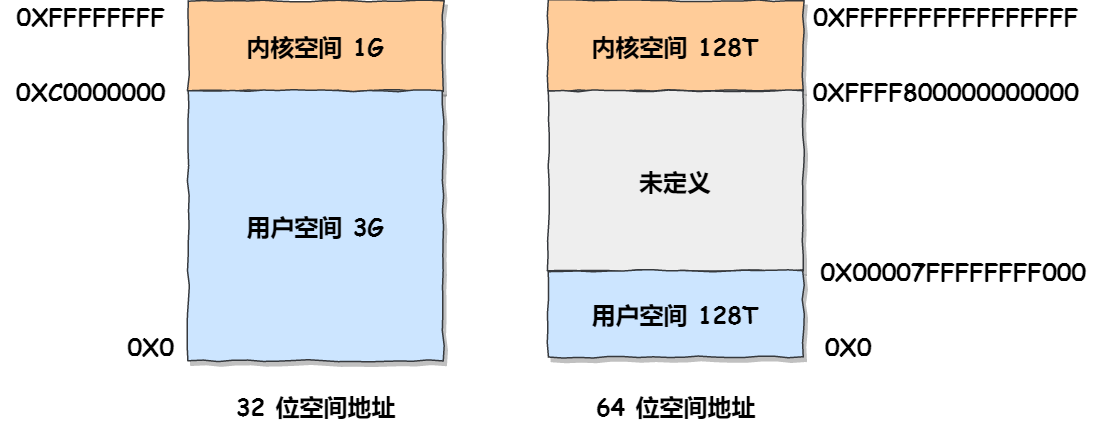
通过这里可以看出:
- 32 位系统的内核空间占用 1G,位于最高处,剩下的 3G 是用户空间;
- 64 位系统的内核空间和用户空间都是 128T,分别占据整个内存空间的最高和最低处,剩下的中间部分是未定义的。
通过在命令行中使用getconf LONG_BIT可以得到机器的位数:

可以看到该机器是64位的。64 位操作系统,进程可以使用 128 TB 大小的虚拟内存空间,所以进程申请 64MB 内存是没问题的,因为进程申请内存是申请虚拟内存,只要不读写这个虚拟内存,操作系统就不会分配物理内存。
任务三 阅读并理解首次适应算法的实现
- 链表数据结构定义
链表数据结构采用的union这种数据类型,union是一个共用体,它在同一时间只能用到一个成员变量。比如代码中的

在同一时刻只能使用meta或x中的其中一个变量。除此以外在这里使用union的作用是控制分配内存空间时字节对齐,union的大小是union中所有成员变量的大小的最大值,ff_malloc返回的类型的void*类型的指针,可以强制转换成其他类型的指针变量,我们必须确保指针对任何数据类型对齐,所以使用unoin会是一个比较好的选择。
对union中的数据类型进行分析,一个struct是指针加unsigned的结构,因为是在64位的机器上,所以一个指针占8个字节,还需要加上一个unsigned类型占2个字节;long基本类型的长度为8个字节,关于这几个长度信息,我们可以在test.c中尝试打印看一下:
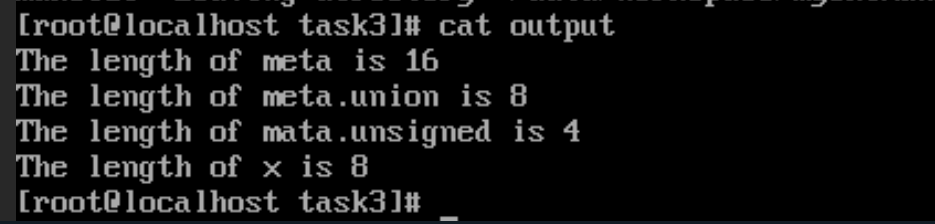
虽然在meta中,union占8个字节,unsigned占4个字节,加起来是12个字节,但是由于字节对齐,会填充4个字节,所以meta的长度是16个字节,而union所占字节是所有成员变量中最长的那个,所以它会占16个字节。那么接下来所分配的内存大小都会是16的倍数。
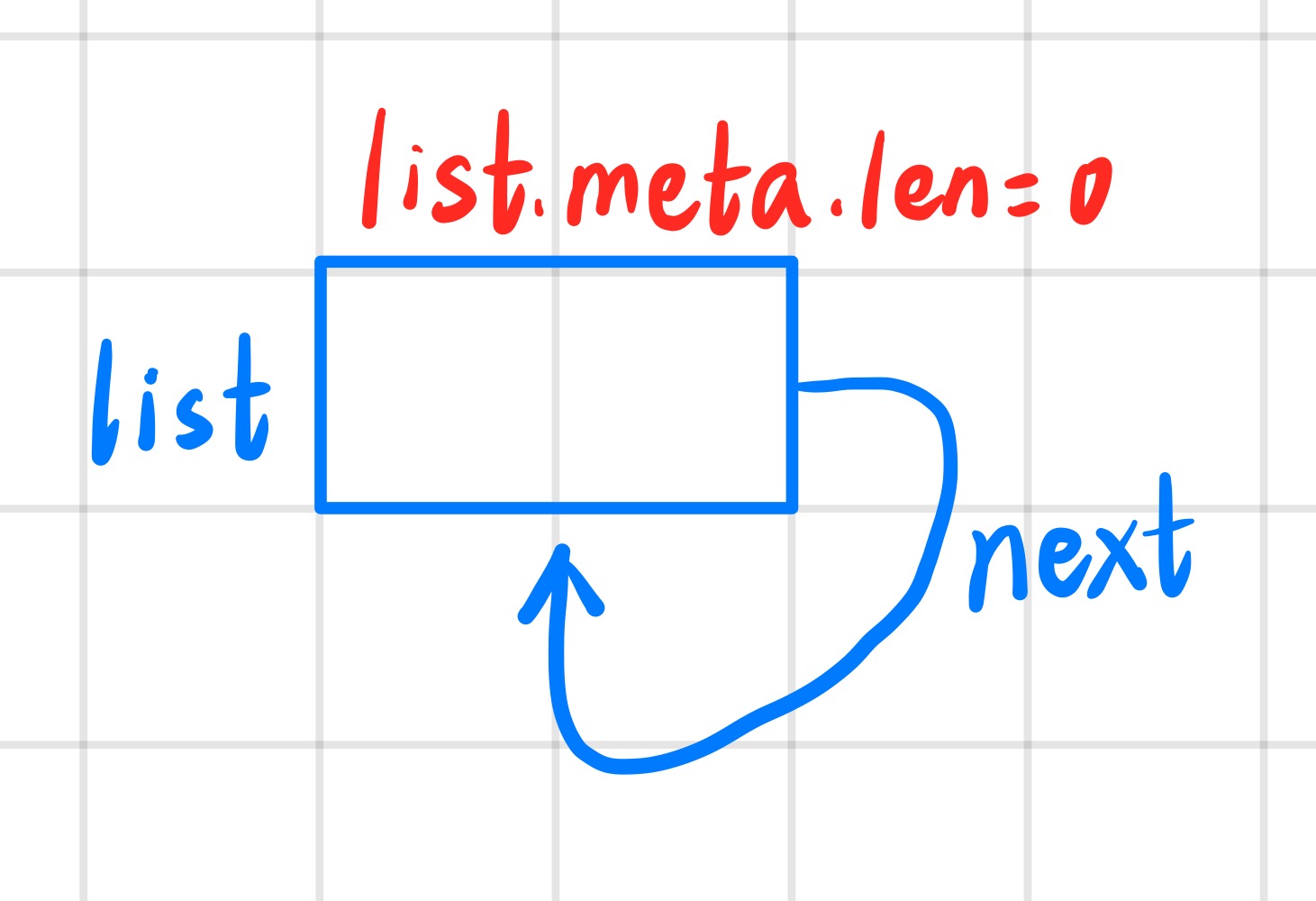
在数据含义上,next指向下一个空闲区块的header,无符号数len表示当前区块下可用的单元块的大小。
- 理解void *ff_malloc(size_t size)
该函数可以返回一个void类型的指针,该指针指向一块大小为size的地址空间。
在该函数中,首先定义了一个变量true_size,该变量为实际需要分配的内存块的大小,其值为(size + sizeof(union header) - 1) / sizeof(union header) + 1,实际上是上取整,多分配一个字节的内存。
首先如果判断first == NULL则说明链表为空,先对链表初始化:
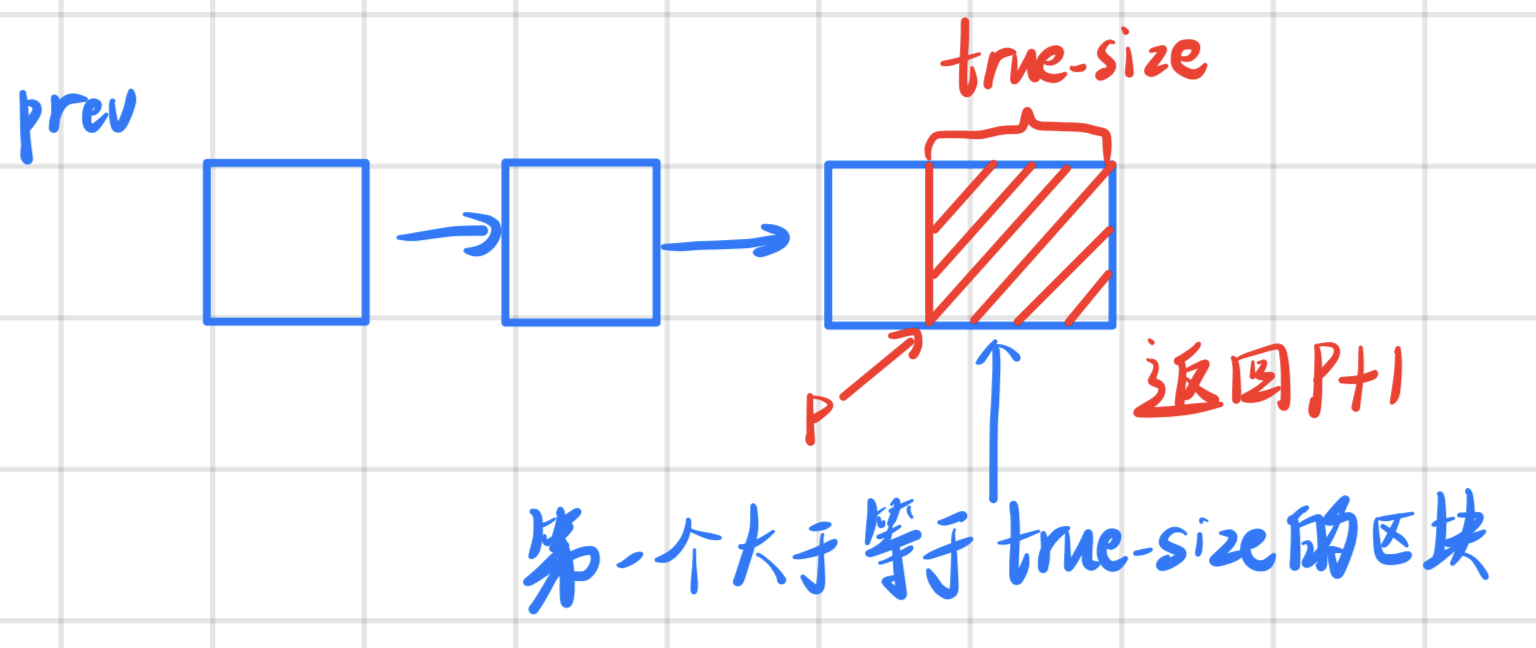
ff_malloc采用最先适应的算法,从链表的头部逐个向后遍历,找到第一个可用空间大于等于所需要的空间的区块,则直接使用该区块进行内存分配。如果找到的该空间恰好等于所需要的空间,则不需要进行分割;否则先将区块分成两块,后一块的大小恰好等于需要分配的空间大小,前一块的大小是分配后剩下的大小,可画图如下:
如果做完以上步骤,p仍然等于first,说明当前这个区块的大小小于需要分配的内存大小,就进入if(p == first)的分支,为page分配大小大于等于NALLOC的空间,NALLOC在ff_malloc.c中用#define定义:

使用下面这句为page分配alloc_size个union header大小的内存:

对于sbrk,我使用man手册查看了一下,它是一个C库函数,其原型为:void *sbrk(intptr_t increment);

描述如下:

可以看到ff_malloc()函数中就是使用这个库函数sbrk实现的。其主要的工作是实现虚拟内存到内存的映射,它从第一个没有被分配的内存空间开始分配increment个大小的内存空间,如果分配成功,则返回前一个程序中断,否则返回(void *)-1。

所以在这里,如果page == (char*)-1,则说明分配失败,设置errno = ENOMEM并返回NULL。
如果分配成功,则让block指向page且让block->meta.len = alloc_size,然后将block+1位置的内存释放,以备之后申请内存空间。在最后让prev指向当前的区块,让p指向下一个区块,从下一个区块开始找分配空间。
- 理解void free(void* ptr)
首先判断ptr是否为空,防止对空指针的处理:
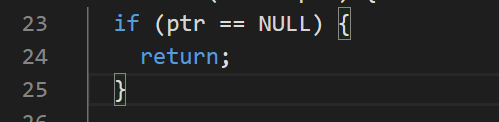
在free()函数中的最后一行是first = iter,所以只需要知道iter的指向即可:
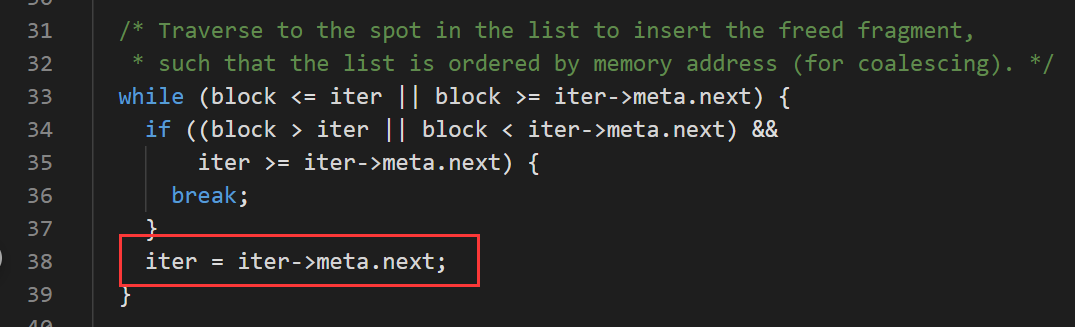
iter的指向只在上面的代码中发生了变化,每一次iter都指向释放块的前一块,方便后面的合并内存块,所以最后first一定指向释放块(合并一整块时)或者释放块的前一块。
总结:
- first的位置决定了搜索的其实位置,也是区分first fit和next fit的方法。
- 该算法中,first释放时总是指向释放块的前一块或者释放块。分配时,first总是指向分配块的前一块。
- ff_malloc.c代码中的first的指向更像next fit而不是first fit。
验证示例:
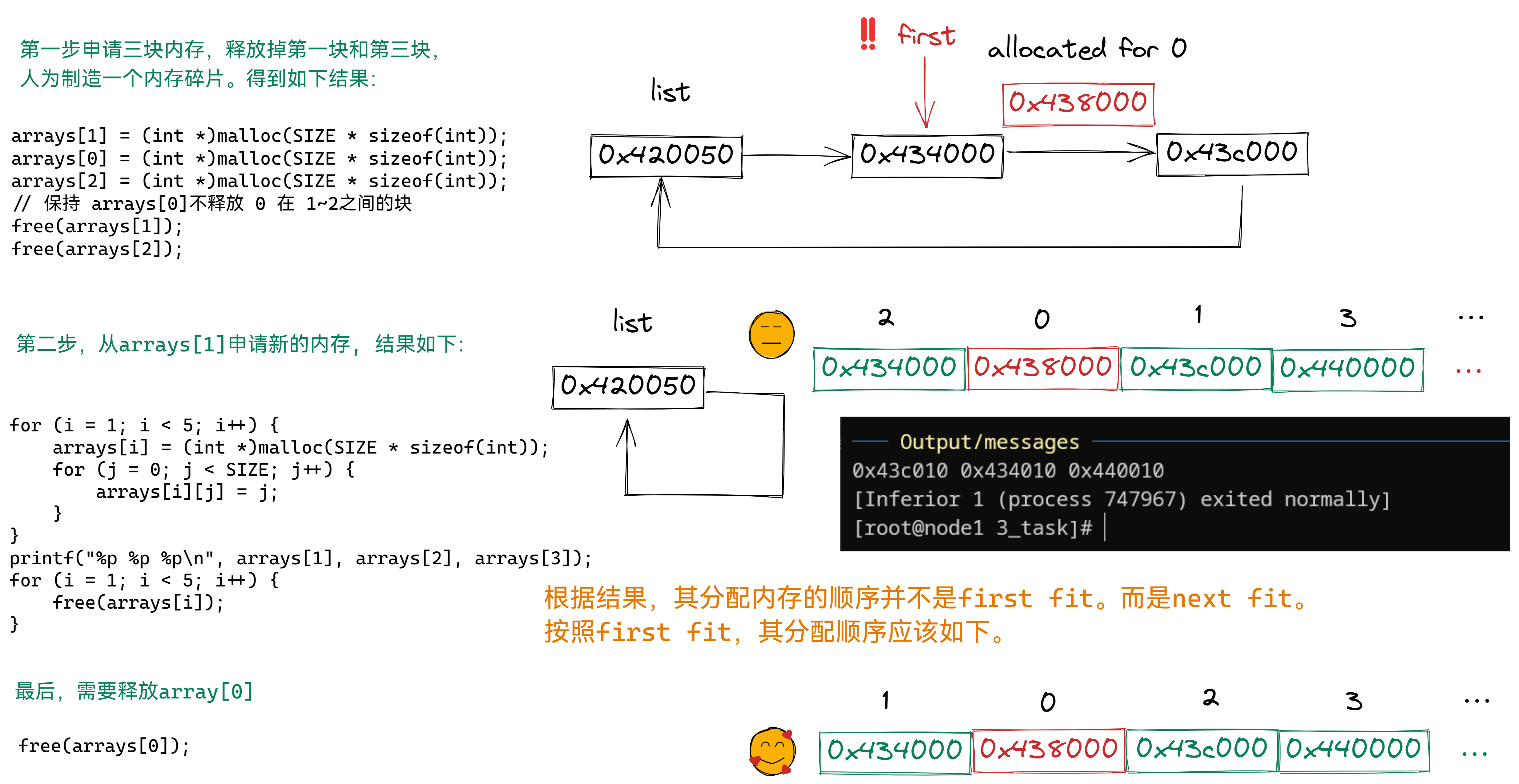
特点和问题:
- 使用sbrk分配内存的时候需要避免同时使用其他内存分配函数。不然可能导致sbrk获取的内存不连续。所以需要避免printf改变堆的问题。
- first指针总是指向prev块,所以不是传统意义上的首次适应算法。
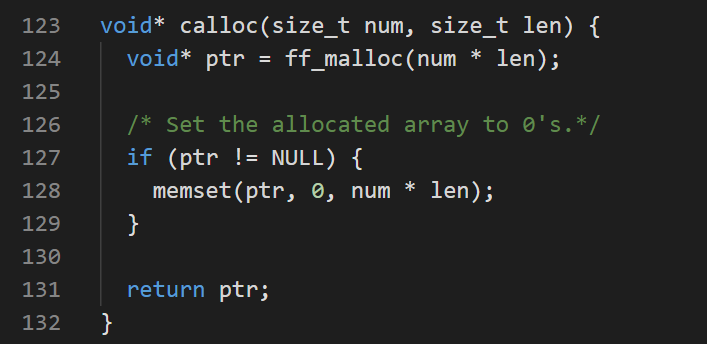
- 理解void* calloc(size_t num, size_t len);
这个函数比较简单,其作用是动态地分配 num 个长度为 size 的连续空间,并将每一个字节都初始化为 0。在这个函数中调用ff_malloc()分配num * len个大小的内存,然后使用memset()将分配的内存都初始化为0。
任务四 实现最佳适应算法
相关知识点
最佳适应(Best Fit)算法指从全部空闲区中找出能满足作业要求且大小最小的空闲分区的一种计算方法,这种方法能使碎片尽量小。
任务描述
基于最佳适应算法设计实现一个简单的内存管理程序,实现内存管理的频繁分配和回收,并通过日志打印等手段比较首次适应算法和最佳适应算法在内存分配上的区别。
- 子任务1
- bf_malloc(size_t size)
在理解任务三的代码后,对于bf_malloc()只需要在while(1)之前将p指向循环链表中的最小块即可,其他地方几乎不需要进行修改,这里的思路主要是改变了搜索的起始块:
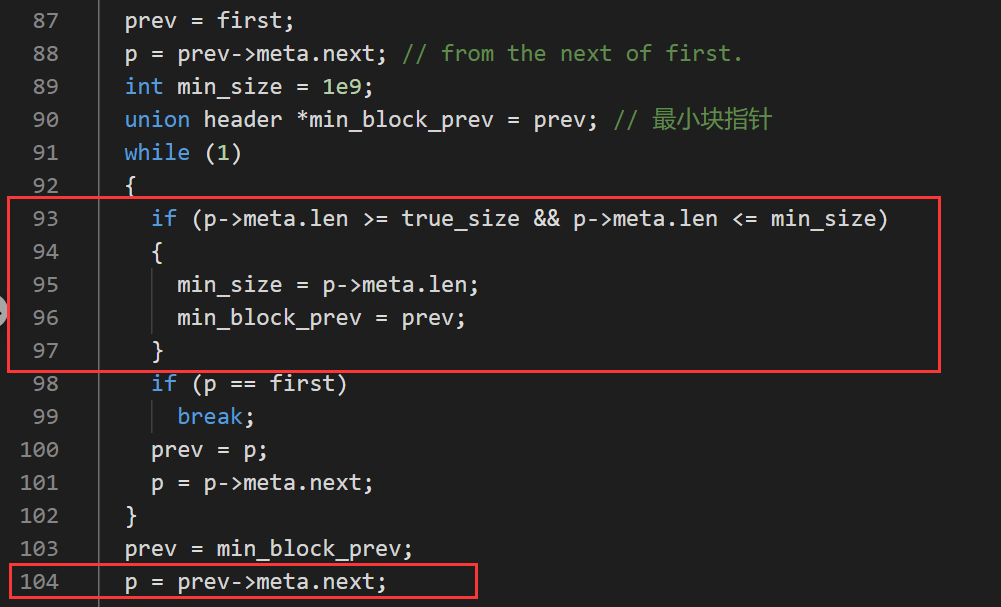
- free(void *ptr)
无需修改。
- calloc(size_t num, size_t, len)
将里面调用的malloc函数改为bf_malloc即可。
- 子任务2
测试脚本test.c如下:
#include "bf_malloc.c" // 选择malloc算法 #include <stdio.h> #define SIZE (1024 * 4 - 4) const unsigned width = 25; void *malloc(size_t size) { return bf_malloc(size); } // 选择malloc算法 int main(int argc, char *argv[]) { int *arrays[50]; int i, j, k; printf( "Start test..\n\033[1A\033[K"); // 此行不能删除,须在ff_malloc之前调用printf函数。 for (k = 0; k < 3; k++) { if (k != 0) printf("\033[10A"); printf("\033[%dC\033[42m > k = %-16d\033[0m\n", k * width, k); arrays[0] = (int *)malloc(SIZE * sizeof(int)); arrays[1] = (int *)malloc(SIZE * sizeof(int)); arrays[2] = (int *)malloc(SIZE * sizeof(int)); arrays[3] = (int *)malloc(SIZE * sizeof(int) * 2 + 16); arrays[4] = (int *)malloc(SIZE * sizeof(int)); for (i = 0; i < 5; i++) { printf("\033[%dC i = %d, addr = %p \n", k * width, i, arrays[i]); } free(arrays[1]); free(arrays[3]); printf("\033[%dC\033[41m%-23s\033[0m\n", k * width, " > free 1, 3"); // malloc new mem arrays[5] = (int *)malloc(SIZE * sizeof(int)); arrays[6] = (int *)malloc(SIZE * sizeof(int)); printf("\033[%dC i = %d, addr = %p \n", k * width, i, arrays[i]); i++; printf("\033[%dC i = %d, addr = %p \n", k * width, i, arrays[i]); free(arrays[0]); free(arrays[2]); free(arrays[4]); free(arrays[5]); free(arrays[6]); printf("\033[%dC\033[41m%-23s\033[0m\n", k * width, " > free 0, 2, 4, 5, 6"); } return 0; } |
测试思路:
- 申请几块内存,释放中间的几块代码。
- 申请新的内存,观察新分配的地址的分配顺序即可以分辨出first fit 和best fit。
- 在这里,我们让0、1、2、4分配同样大小且较小的内存,让3分配较大的内存,然后释放1和3,预期结果是对于ff_malloc:5会在3中找内存地址分配,6会在1中寻找地址分配;对于bf_malloc:5会在1中寻找内存地址分配,6会在3中寻找地址分配。
- 子任务3
测试结果:
注意:其中如果获取一次内存之后,后续内存的分配将从高地址向低地址分配(高地址优先)。
说明:根据代码,只有i=3时分配2047块,其他时候分配1023块。每次先申请内存5次,释放中间的两个部分制造碎片。图中每一行上框和下框,对应的是同一块内存。且k=1和k=2结果分配相同。
下图是ff_malloc的测试结果:
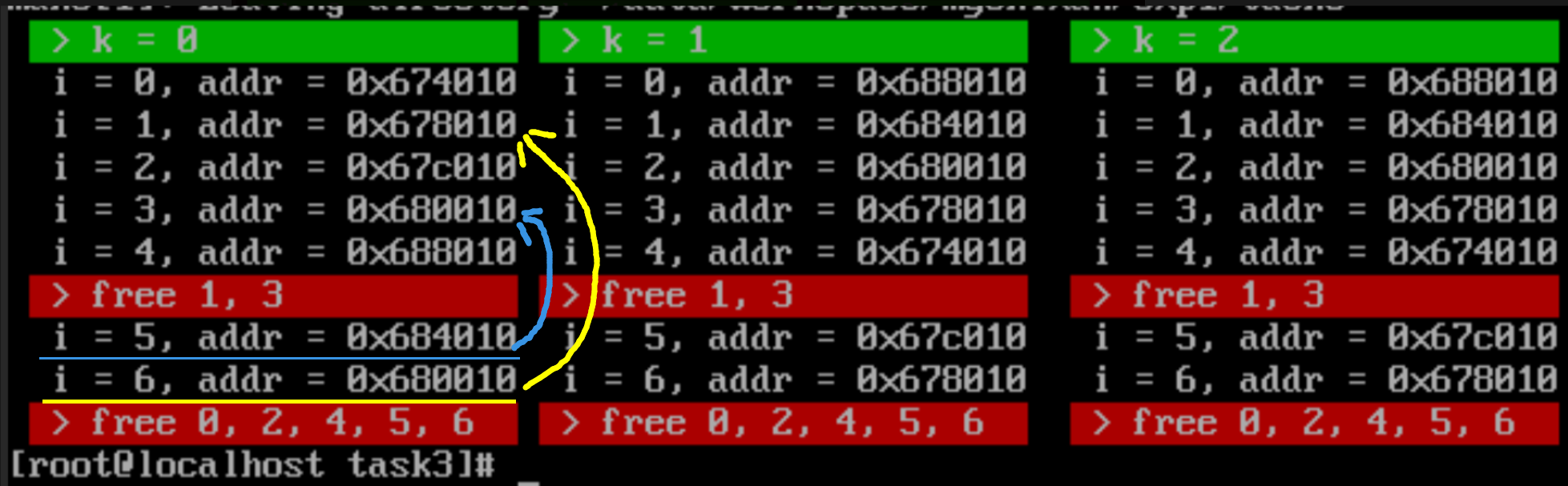
可以看到ff_malloc每次从较高的位置开始找,找到一块可用的就给它分配内存。
下图是bf_malloc的测试结果:
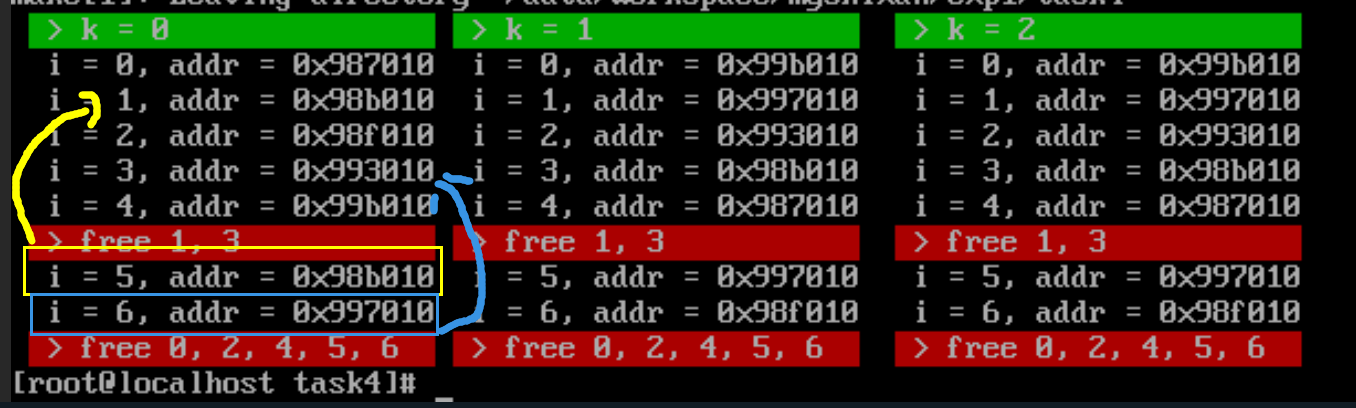
可以看到bf_malloc找到的是较小的一块地址空间去分配内存,即1中的内存。可以看到与预期结果是符合的。
画图表示如下:
ff_malloc:
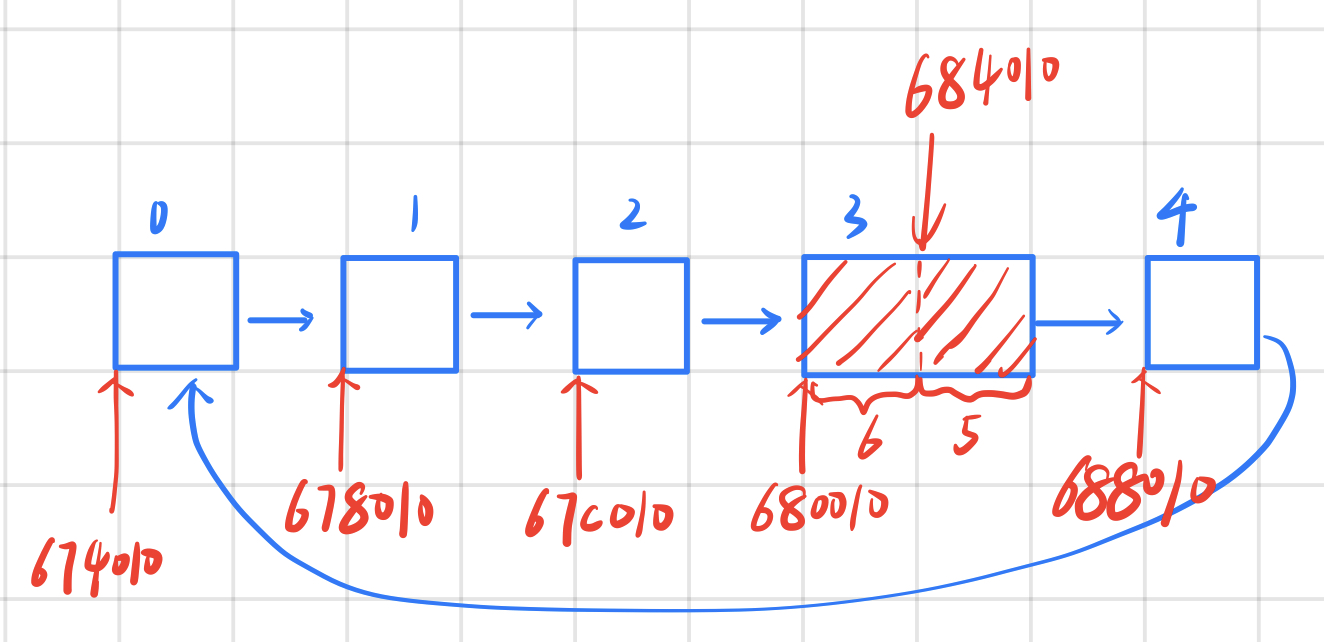
至于为什么ff_malloc会先分配同一块中的高地址,这在之前解释ff_malloc()函数的时候已经解释过了。
bf_malloc:

- 由图可以得出如下结论:
first fit:实际上是下次适应算法,从当前位置找到第一个符合条件的区块。
best fit:总是优先分配最小的满足条件的区块。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号