
性能测试十:性能分析与调优(性能分析方法、CPU、MEM)
一、性能分析
1.1 性能分析的任务
不是寻找问题,而是辨别问题,或者说是辨别哪些问题是重要的。
1.2 性能分析的挑战
从什么地方开始分析?收集哪些数据?如何分析数据?
1.3 异常现象分类
异常一:TPS波动
波动现象1:TPS有明显的大幅波动,不稳定。例如TPS轨迹缓慢下降,缓慢上升后骤降,呈瀑布型,呈矩形,分时间段有规律的波动,无规律的波动等。这些TPS的波动轨迹反映出被测试的性能点存在性能瓶颈,需要性能测试工程师与开发工程师查找性能瓶颈的原因。
波动现象2:TPS轨迹比较平稳,但是也存在波动现象。该类波动不明显,很难直接确定是否存在性能瓶颈。
TPS波动科学分析:

可接受波动范围:
接口: 5%+/-3%
Web: 4%+/-2%
1.4 性能分析方法
1.4.1 性能分析准则
从上至下
1. 发现的80%系统的性能瓶颈都由吞吐量制约; 2. 并发用户数和吞吐量瓶颈之间存在一定的关联; 3. 采用吞吐量测试可以更快速定位问题。
分析系统的瓶颈点遵循的规则如下: - 操作系统资源消耗: CPU、Memory、Disk I/O、Network I/O。 - 中间件指标: 线程池(Thread Pool)、数据库连接池(JDBC)、JVM(GC/FULL GC/堆大小)。 - 数据库指标: 效率低下SQL、锁等待/死锁、缓存命中率、会话、进程等。 - 应用: 方法耗时、算法、同步和异步、缓存、缓冲。 - 压力机: 压力机资源消耗,一般情况下,压力机成为瓶颈的可能性非常低。PTS压力机有保护和调度机制不用单独关注。
从局部到整体
1.4.2 分层分析
分层分析一般需要对系统的应用架构以及部署架构的层次非常熟悉,需要熟知请求的处理链过程。
- 分层分析一般需要对每一层建立checklist(检查清单),然后按照每一层的checklist逐一进行分析。
- 通过分层分析来排查问题的效率虽然较低,但是往往能发现更多的性能问题。
- 分层分析可以自上而下,也可以自下而上。
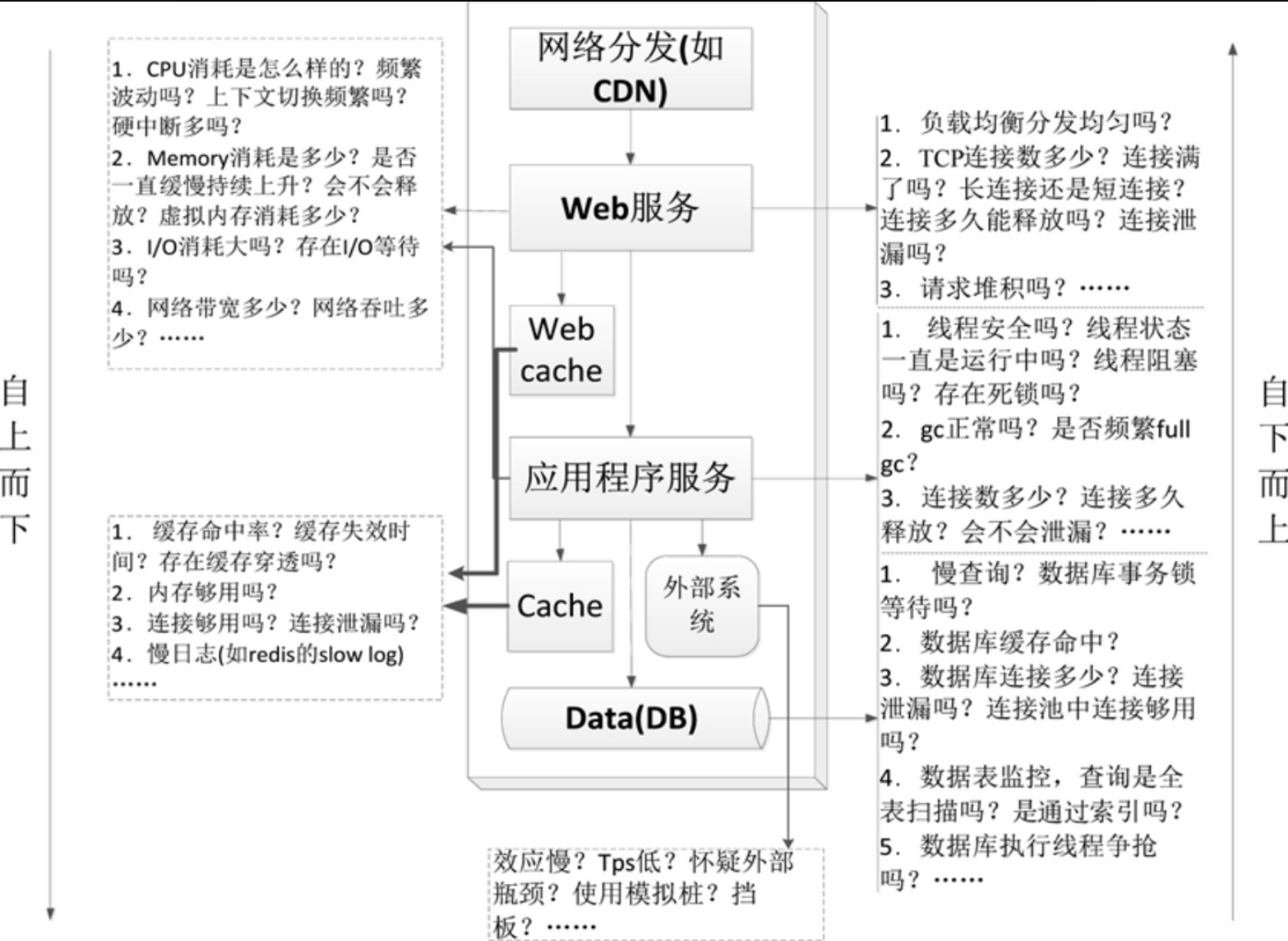
- 首先排除压力机性能情况,包括CPU、内存
- 网络分发。如CDN,可以降低网络拥塞。
- Web服务。除了其自身外,也包括Web Cache。
- 应用程序服务。除了其自身外,也包括应用层Cache和同外部系统的交互。
- Data(DB)。即数据或数据库。
1.4.3 科学论证
科学论证是指通过一定的假设和逻辑思维推理来分析性能问题,一般包括发现问题、问题假设、预测、试验论证、分析这5个步骤,如图
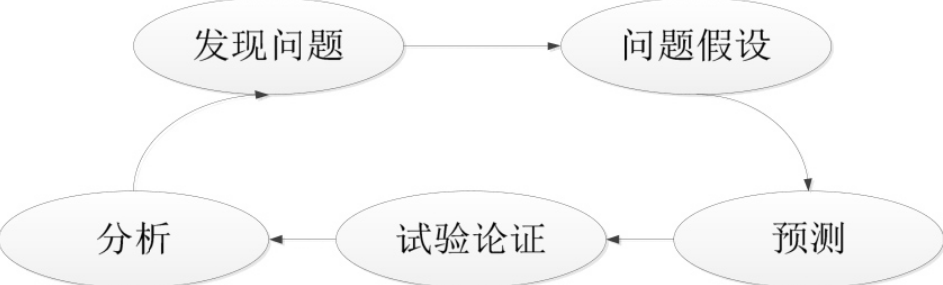
1.发现问题: 指通过性能采集和监控,发现性能瓶颈或者性能问题,比如并发用户数增大后TPS并不增加、每台应用服务器的CPU消耗相差特别大等。
2.问题假设: 指根据自己的经验判断,假设是某个因素导致出现了瓶颈和问题。
3.预测: 指根据问题假设,预测可能出现的一些现象或者特征。
4.试验论证: 根据预测,通过试验去检查预期可能出现的现象或者特征。
5.分析: 根据获取到的实际现象或者特征进行分析,判断假设是否正确,如果不正确,就重新按照这个流程进行分析论证。
示例:

1.4.4 问题追溯与归纳总结
问题追溯指的是根据问题去追溯最近系统或者环境发生的变化,一般适用于已上线生产系统的版本发布或者环境变动导致的性能问题。
二、性能调优
2.1 稳定性与性能的选择
衡量代码质量的标准是可读性、可维护性、可扩展性,但性能优化有可能会违背这些特性,比如为了屏蔽实现细节与使用方式,我们会可能会加入接口层(虚拟层),这样可读性、可维护性、可扩展性会好很多,但是额外增加了一层函数调用,如果这个地方调用频繁,那么也是一笔开销。
2.2 获取单进程系统瓶颈
搭建Mock程序,获取单台压力机线程数、系统资源、性能最大值。用于排除压力机、网络等因素影响。
注意:
2.3 CPU对性能影响
2.3.1 CPU负载
# top load average: 29.17, 29.24, 29.55
第一个值:1分钟CPU负载 表示最近的暂时现象
第二个值:5分钟CPU负载
第三个值:15分钟CPU负载 表示是持续现象,并非暂时问题
2.3.2. CPU使用率来源
来源:Linux 通过 /proc 虚拟文件系统,向用户空间提供了系统内部状态的信息,而 /proc/stat 提供的就是系统的CPU和任务统计信息
# cat /proc/stat | grep ^cpu
//结果分析:从左往右一共 11 列 CPU 编号: 第一行是 CPU 的累加 user(us): 用户态 CPU 的时间,不包括下面的 nice 时间,但包括了 guest 时间 nice(ni): 低优先级用户态 CPU 的时间,就是进程的 nice 值被调整为 1-19 之间时的 CPU 时间;注意 nice 可取值范围是 -20 到 19,数值越大,优先级反而越低 system(sys): 内核态 CPU 的时间 idle(id): 空闲时间,它不包括等待 I/O 的时间(iowait) iowait(wa): 等待 I/O 的 CPU 时间 irq(hi): 处理硬中断的 CPU 时间 softirq(si): 处理软中断的 CPU 时间 steal(st): 当系统运行在虚拟机中的时间,被其他虚拟机占用的 CPU 时间 guest: 通过虚拟化运行其他操作系统的时间,就是运行虚拟机的 CPU 时间 guest_nice(gnice): 以低优先级运行虚拟机的时间
2.3.3 CPU使用率
节拍率:
- 为了维护 CPU 时间,Linux 通过事先定义的节拍率(内核中表示为 HZ),触发时间中断,并使用全局变量 Jiffies 记录了开机以来的节拍数
- 每发生一次时间中断,Jiffies 的值 就加 1。
- 节拍率 HZ 是内核的可配选项,可以设置为 100、250、1000 等
- 不同的系统可能设置不同数值,你可以通过查询 /boot/config 内核选项来查看它的配置值
- 比如在我的系统中, 节拍率设置成了 1000,也就是每秒钟触发 1000 次时间中断。
# grep 'CONFIG_HZ=' /boot/config-$(uname -r)
用户空间节拍率:
- 因为节拍率 HZ 是内核选项,所以用户空间程序并不能直接访问
- 为了方便用户空间程序,内核还提供了一个用户空间节拍率 USER_HZ
- 它总是固定为 100,也就是 1/100 秒
- 这样,用户空间程序并不需要关心内核中 HZ 被设置成了多少,因为它看到的总是固定值 USER_HZ
CPU使用率计算公式:
CPU使用率通常指处理器在特定时间内执行非空闲任务的时间占比,反映其忙碌程度。计算方式如下:
1.基础公式:

2.实际监控中的采样方法:

3.多核CPU注意事项:
- 若系统有N个逻辑核心,理论上最大使用率为 N×100%N×100%(如4核可达400%)。监控工具可能显示为总使用率或平均每核使用率。
- 性能分析工具给出的都是间隔一段时间的平均 CPU 使用率,所以要注意间隔时间的设置
2.3.4 CPU使用率对性能影响
CPU>70%使用率对性能影响:
-
任务排队延迟增加,响应变慢。
-
系统可能频繁上下文切换,导致额外开销。
-
若持续接近100%,可能触发降频或过热保护(硬件层面)
2.3.5 CPU上下文切换
什么是CPU上下文切换
上下文切换(Context Switching) 是CPU从执行一个进程/线程切换到另一个进程/线程时,必须保存当前任务状态(如寄存器、程序计数器、内存页表等),并加载新任务状态的过程。主要分为三类:
-
进程上下文切换:不同进程间的切换,需切换虚拟内存、栈等资源,开销最大。
-
线程上下文切换:同一进程内的线程切换,共享内存空间,仅需切换私有数据(如寄存器),开销较小。
-
中断上下文切换:硬件中断(如网卡数据到达)触发,需暂停当前任务处理中断,要求快速完成。
#vmstat 5 5 //5s采样 每隔 5s 输出一次结果 procs -------memory------- --swap-- --io--- --system-- ----cpu---- r b swpd free buff cache si so bi bo in cs us sy id wa 1 0 62792 3460 9116 88092 6 30 189 89 1061 569 17 28 54 2 0 0 62792 3400 9124 88092 0 0 0 14 884 434 4 14 81 0 0 0 62792 3400 9132 88092 0 0 0 14 877 424 4 15 81 0 1 0 62792 3400 9140 88092 0 0 0 14 868 418 6 20 74 0 1 0 62792 3400 9148 88092 0 0 0 15 847 400 9 25 67 0 //procs: r: 在运行队列中等待的进程数 running or Runnable,如CPU为4C,r为8,就存在CPU竞争 b: 在等待io的进程数 locked
//内存memoy: swpd:现时可用的交换内存(单位KB) free:空闲的内存(单位KB) buff: 缓冲器中的内存数(单位:KB) cache:被用来做为高速缓存的内存数(单位:KB)
//swap交换页面 si: 从磁盘交换到内存的交换页数量,单位:KB/秒 swap-input so: 从内存交换到磁盘的交换页数量,单位:KB/秒 swap-output
//io块设备: bi: 发送到块设备的块数,单位:块/秒 block-input bo: 从块设备接收到的块数,单位:块/秒 block-output
//system系统 in: 每秒的中断数,包括时钟中断 interrupt cs: 每秒的环境(上下文)转换次数 context switch
//cpu中央处理器 us:用户进程使用的时间 以百分比表示 sy:系统进程使用的时间 以百分比表示 id:中央处理器的空闲时间 以百分比表示
进程/线程上下文统计
# pidstat -wt -u 3 3 //每3s输出一次结果,共输出3次
结果分析 - cswch: //每秒自愿上下文切换 - nvcswch: //每秒非自愿上下文切换的次数
自愿上下文切换 - 进程无法获取所需自愿,导致的上下文切换 - 栗子:I/O、内存等系统资源不足时,就会发生
非自愿上下文切换 - 非自愿上下文切换,则是指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换 - 栗子:大量进程都在争抢CPU时,就容易发生非自愿上下文切换,CPU成为瓶颈
pidstat默认显示进程级别的指标数据 -t 参数它可以显示与选定任务关联的线程的统计信息 -w 选项,每3s输出一次结果,共输出3次 -u 输出 CPU 使用情况
中断相关统计
# cat /proc/interrupts //显示每个CPU核心的中断次数 - 高频中断可能间接导致上下文切换增多(如网络包处理)。
- 栗子:中断升高是多任务调度问题,说明CPU被中断处理程序占用,需通过/pro/interrupts文件来分析中断类型
备注:/proc/interrupts 是只读文件,/proc实际上是 Linux 的一个虚拟文件系统,用于内核空间与用户空间之间的通信
2.3.6 上下文切换对性能影响
-
CPU时间浪费:保存和恢复寄存器、内存页表等操作消耗CPU周期。
-
缓存失效:切换后CPU缓存(L1/L2/L3)可能失效,降低后续指令执行效率。
2. 间接性能问题
-
高并发场景:线程/进程过多时,频繁切换导致吞吐量下降。示例:1万个线程竞争CPU,实际执行时间可能被大量切换开销淹没。
-
锁竞争:线程因锁阻塞会触发自愿切换,加剧延迟。
-
实时性下降:高频切换可能破坏低延迟任务的响应时间。
3. 性能问题诊断
-
症状:
-
CPU使用率高但系统吞吐量低。
-
vmstat中r列(就绪队列)持续大于CPU核心数。 -
pidstat显示某些进程的cswch/s或nvcswch/s异常高。 -
阈值参考:
-
单核CPU:若上下文切换 > 1万次/秒,可能存在性能问题。
- 多核系统:需结合核心数评估(如8核系统,总切换量可能达数万次/秒)。
4.分析步骤
- 通过 vmstat 确认系统的当前的上下文切换(cs)、中断次数(in)、就绪队列(r)、CPU 使用率(us、sy)
- 若上下文切换次数和 CPU 使用率过高,通过 pidstat 查看是哪个进程或线程的切换次数过高,CPU 使用率过高
- 然后确认是自愿上下文切换还是非自愿上下文切换,从而深入分析是否存在其他系统瓶颈问题
- 若中断次数过高,通过 /proc/interrupts 分析是哪种中断类型
2.4 内存对性能影响
2.4.1 物理内存(Physical Memory)
# free -h total used free shared buff/cache available Mem: 62G 15G 3.2G 1.5G 43G 45G Swap: 8G 0B 8G
- 实际硬件RAM,供进程和内核直接使用。
-
buff/cache:内核缓冲区(Buffer)和页缓存(Page Cache),用于加速磁盘I/O。
-
available:系统当前可分配给进程的内存(包含缓存可回收部分)。
2.4.2 物理内存对性能影响
内存充足时(Available > 20%)
- 系统运行流畅,缓存机制提升I/O性能(如频繁读取的文件缓存到内存)
- 进程可快速分配内存,响应时间短
内存不足时(Available < 10%)
- OOM Killer触发:内核强制终止占用内存最多的进程(日志见/var/log/messages)
- Swap频繁使用:磁盘I/O增加,系统响应延迟明详增加(可通过vmstat 1 观察 si / so列)
- 进程卡顿:内存分配失败导致进程挂起或崩溃(如Java应用的OutOfMemoryError)
极端场景
- 内存泄漏:进程持续申请内存但不释放,最终耗尽系统资源。即进程的RES(常驻内存)持续增长,重启后恢复。
- 内存碎片化:物理内存被分割成小块,无法满足大内存分配需求(常见于长期运行的服务)
- 缓存占用过高:buff/cache占用大量内存,但Available仍充足;可能挤占应用内存,但可通过内核自动回收缓解。
- 大页内存配置不当:应用(如数据库)因未配置HugePages导致内存管理开销大; TLB(Translation lookaside Buffer)未命中率升高性能下降。
备注:
CPU每次访问虚拟内存,虚拟地址都必须转换为对应的物理地址。从概念上说,这个转换需要遍历页表,页表是三级页表,就需要3次内存访问。就是说,每次虚拟内存访问都会导致4次物理内存访问。
简单点说,如果一次虚拟内存访问对应了4次物理内存访问,肯定比1次物理访问慢,这样虚拟内存肯定不会发展起来。
幸运的是,有一个聪明的做法解决了大部分问题:现代CPU使用一小块关联内存,用来缓存最近访问的虚拟页的PTE。这块内存称为translation lookaside buffer(TLB)。
2.4.3 虚拟内存(Virtual Memory)
什么是虚拟内存:
内存管理系统是操作系统中最为重要的部分,因为系统的物理内存总是少于系统所需要的内存数量。
虚拟内存就是为了克服这个矛盾而采用的策略,使用磁盘作为RAM的扩展,通过在各个进程之间共享内存而使系统看起来有多于实际内存的内存容量。
- 操作系统抽象出的逻辑内存模型,每个进程拥有独立的虚拟地址空间,可超出物理内存容量。
- 每个进程通过虚拟地址空间独立访问内存,避免直接操作物理内存,确保隔离性和安全性。
- 物理内存仅分配进程实际使用的部分,虚拟内存通过分页机制(Paging)动态管理映射。
- 当物理内存不足时,不活跃的内存页被换出到磁盘交换空间(Swap Space),腾出物理内存供急需的进程使用。
- 每个进程的虚拟内存布局可通过 pmap 或 /proc/<PID>/maps查看。
虚拟内存的优势:
- 进程隔离:防止进程间非法内存访问。
- 大地址空间:进程可操作超出物理内存容量的虚拟地址(如64位系统支持巨大地址空间)
- 高效利用内存:通过共享库(如glibc)和写时复制(Copy-on-Write)减少冗余占用。
- 延迟分配:物理内存仅在进程实际写入时分配(如malloc() 分配虚拟地址,首次访问时触发缺页分配物理页)
2.4.4 Swap空间
- 磁盘上的虚拟内存扩展,当物理内存不足时,将不活跃的页换出到Swap
- 使用 swapon -s 查看当前 Swap设备
- 使用 vmstat 1 3 查看 Swap使用情况si /so
2.4.5 内核内存
- 用于内核数据结构(如进程描述符、网络栈、Slab分配器等)
- 地址转换(MMU与页表):内存管理单元(MMU)- 硬件组件,将进程的虚拟地址转换为物理地址; 页表(Page Table)- 内核维护的数据结构,记录虚拟页到物理页帧的对应关系。若目标页不存在物理内存(触发缺页中断),内核从磁盘加载数据。
- 分页与交换:分页 - 物理内存与虚拟内存被均分为固定大小的页(通常4KB); 页面置换 - 当物理内存不足时,页面置换算法(如LRU)选择不活跃的页换出到交换区,后续访问再换入(Page In/Out)
- 内存保护:权限控制 - 页表条目包含读写执行权限,防止进程越界访问 ;内核/用户空间隔离 - 用户进程无法直接访问内核空间虚拟地址,需通过系统调用。
- 通过slabtop 或 /proc/meminfo 中的Slab字段监控
2.4.6 MEM使用率
1 [root@localhost ~]# cat /proc/meminfo 所有命令最终都是通过该文件获取系统内存使用情况的 2 MemTotal: 3714660 kB 3 MemFree: 3177016 kB 4 MemAvailable: 3242452 kB 5 Buffers: 2708 kB 6 Cached: 255136 kB 7 SwapCached: 0 kB 8 Active: 141640 kB 9 Inactive: 178340 kB 10 Active(anon): 51844 kB 11 Inactive(anon): 19408 kB 12 Active(file): 89796 kB 13 Inactive(file): 158932 kB 14 Unevictable: 0 kB 15 Mlocked: 0 kB 16 SwapTotal: 2097148 kB 17 SwapFree: 2097148 kB 18 Zswap: 0 kB 19 Zswapped: 0 kB 20 Dirty: 0 kB 21 Writeback: 0 kB 22 AnonPages: 62136 kB 23 Mapped: 40020 kB 24 Shmem: 9116 kB 25 KReclaimable: 40960 kB 26 Slab: 95164 kB 27 SReclaimable: 40960 kB 28 SUnreclaim: 54204 kB 29 KernelStack: 4752 kB 30 PageTables: 1444 kB 31 SecPageTables: 0 kB 32 NFS_Unstable: 0 kB 33 Bounce: 0 kB 34 WritebackTmp: 0 kB 35 CommitLimit: 3954476 kB 36 Committed_AS: 185864 kB 37 VmallocTotal: 34359738367 kB 38 VmallocUsed: 54176 kB 39 VmallocChunk: 0 kB 40 Percpu: 48128 kB 41 HardwareCorrupted: 0 kB 42 AnonHugePages: 14336 kB 43 ShmemHugePages: 0 kB 44 ShmemPmdMapped: 0 kB 45 FileHugePages: 0 kB 46 FilePmdMapped: 0 kB 47 CmaTotal: 0 kB 48 CmaFree: 0 kB 49 Unaccepted: 0 kB 50 HugePages_Total: 0 51 HugePages_Free: 0 52 HugePages_Rsvd: 0 53 HugePages_Surp: 0 54 Hugepagesize: 2048 kB 55 Hugetlb: 0 kB 56 DirectMap4k: 139072 kB 57 DirectMap2M: 3006464 kB 58 DirectMap1G: 3145728 kB
2.4.7 MEM问题排查方法
全局内存状态分析:
实时查看数据:
free -h # 查看总体内存使用 top # 实时监控进程内存(按`M`按内存排序)
vmstat 1 5 # 每秒输出一次,共5次 关注swpd(已用Swap)、si(Swap In)、so(Swap Out)、free(空闲内存)
历史内存数据:
sar -r 1 3 #每秒采样内存,共三次
sar -B 1 3 #查看分页统计(缺页异常、Swap活动)
进程级内存分析:
定位高内存进程:
ps aux --sort=-%mem | head -n 10 # 按内存使用排序显示前10进程 pmap -X <PID> # 显示进程详细内存分配(需安装procps)
查看进程内存映射:
pmap -X <PID> # 显示进程详细内存分配(需安装procps)
检测内存泄漏工具:
valgrind --leak-check=full ./your_program # 适用于C/C++程序
jstak -gctil <PID> 1000 # 适用于java ;每秒输出GC统计,观察老年代占用
内核与缓存分析:
详细信息:
cat /proc/meminfo |grep -E 'MemTotal|MemFree|Buffers|Cached|Swap|Slab'
Slab内存分析:
slabtop -o # 按占用排序显示Slab缓存
手动释放缓存:
echo 3 > /proc/sys/vm/drop_caches # 释放PaageCache、Slab等(不影响进程)
Swap优化与配置:
调正Swap使用倾向: sysctl vm.swappiness=10 # 默认60,值越低越倾向保留物理内存(临时生效) 永久生效写入 /etc/sysctl.conf 禁用或扩容Swap: swapoff -a # 禁用所有Swap分区 dd if=/dev/zero of=/swapfile bs=1G count=8 # 创建8G Swap文件 mkswap /swapfile && swapon /swapfile
JVM内存分析:
方法一:使用JDK工具jmap获取dump文件
# ps -ef|grep java # 获取javaGC进程 # jmap -dump:format=b,file=/path/to/dumpfile.hprof <PID> # 其中 /path/to/dumpfile.hprof 是dump文件保存的路径,PID 是进程的 ID
方法二:在应用程序中编写代码获取线程dump文件
ThreadInfo[] threadInfos = ManagementFactory.getThreadMXBean().dumpAllThreads(true, true); PrintWriter pw = new PrintWriter(new FileWriter("/path/to/dumpfile.txt")); for (ThreadInfo threadInfo : threadInfos) { pw.print(threadInfo.toString()); } pw.close(); # 其中 /path/to/dumpfile.txt 是dump文件保存的路径
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=D:\tmp # 模拟OOM错误,出发产生dump文件 private static Map<String, String> map = new HashMap<>(); @RequestMapping("/oom") public String oom() throws Exception { for (int i = 0; i < 100000; i++){ map.put("key" + i, "value" + i); } return "oom"; }
dump文件分析:
将Linux文件移动至Windows
步骤一 压缩:# tar -zcvf newdump.tar.gz user.dump 步骤二 分割:# split-b 100M newdump.tar.gz -d newdump_offshoot.tar.gz 步骤三 合并:cmd进入windows控制台:
# copy /b 分割文件1 + 分割文件2 + .... 合并文件名

 浙公网安备 33010602011771号
浙公网安备 33010602011771号