
性能测试三:测试指标
一、性能指标
TPS(Transactions Per Second每秒事务数)
服务器在单位时间内(秒)可以处理的事务数量,一般以request/sec为单位。
与请求对CPU的消耗、外部系统接口、IO等等紧密关联,单个请求对CPU消耗越高,外部系统接口和IO速度越慢,系统吞吐能力越低,反之越高。
备注: 1.TPS是以事务为基础,秒级为单位的平均值,统计值,而非瞬时值。重点基与事务,毫秒微秒的瞬息值可能无法完成事务。 2.TSP和QPS区别:TPS事务由脚本定义可能报告多个接口,脚本请求单个接口时,TPS=QPS
如何评价一个系统的TPS?
- 公式一:TPS = 总请求 / 总时间,实际会考虑二八原则
- 公式二:TPS = 并发数 / 业务平均时间
- 公式三: F = VU * R / T(其中F为吞吐量,VU表示虚拟用户个数,R表示每个虚拟用户发出的请求数,T表示性能测试所用的时间)
RT(Response time 响应时间)
RT = DNS延迟 + TCP连接延迟(三次握手时间) + TCP数据传输时间
一般性能测试中,平均响应时间(ART)更具有代表意义。细分的话,还有最大最小响应时间,50%、90%用户响应时间等。
延迟(Latency):
也被称为网络延迟,是指数据从发送端到接收端的传输时间。这个传输时间不仅包括数据包在物理传输媒体上传播的时间,还包括了数据包在网络设备上进行处理的时间,以及在队列中等待处理的时间。
- 传输延迟(Transmission Latency)数据在传输媒体上传播的时间,受到物理传输媒体的特性、传输距离和信号传输速度的影响。传输延迟通常是物理延迟的一部分。
- 处理延迟(Processing Latency)数据在网络设备上进行处理所需的时间,包括路由器、交换机和计算机等设备。处理延迟受到设备性能、负载和协议的影响。
- 排队延迟(Queueing Latency)当多个数据包在网络设备上等待处理时,它们会进入一个队列。排队延迟是数据包在队列中等待的时间,它受到网络拥塞程度的影响。
- 传播延迟(Propagation Latency)这是数据包从发送端到接收端传播所需的时间,受到信号传播速度和传输距离的影响。
如何减少延迟?
- 使用高速网络连接:选择具有高带宽和低延迟的网络连接,如光纤连接,以减小传输延迟和传播延迟。
- 优化路由和设备:使用高性能的路由器和交换机,并确保网络设备的正常运行。升级网络设备和协议可以减小处理延迟。
- 负载均衡:在多个服务器或连接之间均衡负载,以减小排队延迟和网络拥塞的可能性。
- 使用内容分发网络(CDN):CDN可以将数据和内容缓存在接近用户的位置,减小传输延迟和排队延迟。
- QoS管理:使用服务质量(QoS)策略,以优先处理重要的数据流量,确保较低的延迟。
VU( Virtual Users虚拟用户数)
并发指的是所有用户在同一时间点进行同样的操作,一般指同一类型的业务场景;广义上的并发指,多各用户与系统发生了交互,这些业务场景可以是相同也可以是不同的。
如何确定系统并发用户数?
计算并发用户数的方法一般分为两类,一类为有业务数据参考,一类为无业务数据参考。
有业务数据参考:
方法一 - 平均并发用户数:C = nL / T - 最大并发用户数:Ñ ≈ C + C根号3 C代表平均并发用户数, Ñ代表最大并发用户数, n是访问系统用户数量(一般平均每天的用户访问量), L是用户访问系统平均 时间(单位分钟), T是用户使用系统时间段(单位分钟)。 方法二 - 并发用户数:系统最大在线用户数的8%到12%。
无业务数据参考:
- 公式为 C = (Think Time + RT) * TPS
RT代表系统响应时间
Think Time代表用户思考时间。
一般情况下,性能测试是将系统处理能力容量测出来,而不是测试并发用户数,除了服务器长连接可能影响并发用户数外,系统处理能力不受并发用户数影响;
并发用户数指标的另一个作用是作为微服务限流(以连接数为准)大小的依据。
Availability (事物成功率)
性能测试中,定义事务用于度量一个或者多个业务流程的性能指标。一般成功率≥99.99%
成功率指系统在负载情况下,失败成功的概率。可以根据交易数或请求数直接计算得出。对于稳定性较好的系统,其错误大概率由超时引起,即为超时率。
计算公式为:成功率=(失败成功数/交易总数)× 100%。
二、资源指标
CPU使用率
CPU 利用率要低于业界警戒值范围之内,即小于或者等于75%;
- CPU sys%小于或者等于30%;
- CPU wait%小于或者等于5%
- CPU Load要小于CPU 核数
内存使用率
现代的操作系统为了最大利用内存,在内存中存放了缓存,因此内存利用率100%并不代表内存有瓶颈,衡量系统内有有瓶颈主要靠SWAP(与虚拟内存交换)交换空间利用率,一般情况下,SWAP交换空间利用率要低于70%,太多的交换将会引起系统性能低下。
- SWAP交换空间利用率低于70%
nmon内存利用率计 = memtotal - ( memfree + membuffer + mencached ) / memtotal * 100%
网络IO
网络吞吐量是指在无网络故障的情况下单位时间内通过的网络的数据数量。单位为Byte/s。
网络吞吐量指标用于衡量系统对于网络设备或链路传输能力的需求。
当网络吞吐量指标接近网络设备或链路最大传输能力时,则需要考虑升级网络设备。
网络吞吐量指标主要有每秒有多少兆流量进出
- 网络吞吐不能超过最大传输能力70%
磁盘IO
磁盘指标主要有每秒读写多少兆,磁盘繁忙率,磁盘队列数,平均服务时间,平均等待时间,空间利用率。其中磁盘繁忙率是直接反映磁盘是否有瓶颈的的重要依据,一般情况下,磁盘繁忙率要低于70%。
- 磁盘繁忙率低于70%
三、中间件指标
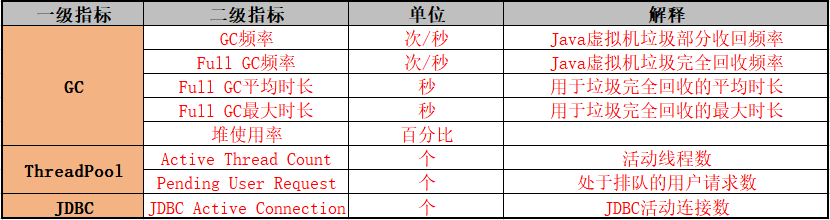
对于中间件指标,行业的参考标准如下。
GC频率不能过高,特别是FulGC。在系统性能较好的情况下,一般JVM最小堆大小和最大堆大小分别设置为1024MB比较合适。
当前正在运行的线程数不能超过设定的最大值。在系统性能较好的情况下,一般线程数最小值设置为50,最大值设置为200。
当前运行的JDBC活动连接数不能超过设定的最大值。在系统性能较好的情况下,一般JDBC最小值设置为50,最大值设置为200。
四、数据库指标
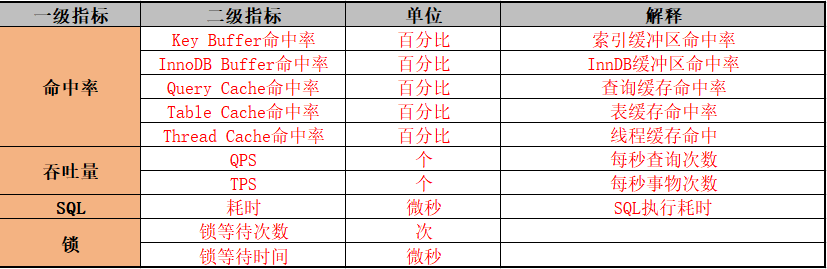
对于数据库指标,行业的参考标准如下:
SQL耗时越小越好,一般情况下为微秒级别;
命中率越高越好,一般情况下不能低于95%;
锁等待次数越少越好,等待时间越短越好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号