图解
![]()
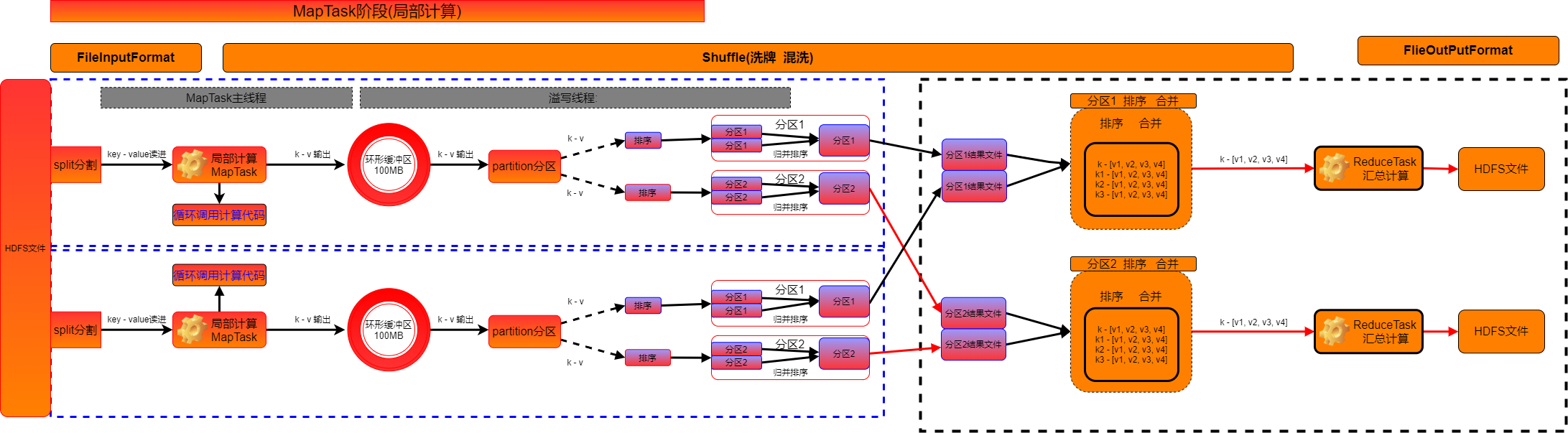
mapreduce工作流程
# 0. 任务提交
1. 拆-split逻辑切片--任务切分。
FileInputFormat--split切片计算工具
FileSplit--单个计算任务的数据范围。
2. 获得split信息和个数。
# MapTask阶段
1. 读取split范围内的数据。k(偏移量)-v(行数据)
关键API:TextInputFormat。
2. 循环调用mapper.map(k,v)
关键代码:
while(xx.next){
mapper.map(k,v);
}
3. mapper.map执行完毕后,输出k-v,调用k-v的分区计算
Partitioner.getPartition(k,v,reduceTask数量)--分区号。
4. 将输出k-v{分区号},存入临时缓冲区。环形缓冲区。
MapOutputBuffer--环形缓冲区。
5. 如果缓冲区写满80%(mapper代码执行完毕),触发spill溢写过程。
① 读取k-v{分区号},对溢写范围内的数据进行排序。
② 存放到本地磁盘文件中,产生分区内的溢写文件。
6. 溢写完毕后,产生多个溢写文件
① 将多个溢写文件合并成1个有序---归并排序。
② combiner(分区 合并 调用reducer--局部reduce操作)【如果开启】
结果:
每个MapTask执行完毕后本地磁盘,每个分区(目录)内只有一个文件。(Key有序)
# ReduceTask阶段
1. 从各个MapTask节点下载对应分区的结果文件。
MapTask(分区0文件)
MapTask(分区0文件)→ ReduceTask-0
MapTask(分区0文件)
2. merge操作
① 排序
② 按照key分组``
③ 将key相同的多个value--->[v,v,v,v]
3. 循环调用Reducer.reduce方法处理数据
while(xxx){
reducer.reduce(k,vs);
}
4. reducer.reduce输出key-value,将数据写入HDFS中。
TextOutputForamt 格式化数据的工具类
FileOutputFormat 指定输出HDFS的路径位置。
MapReduce源码讲解
1. 提交Job
//4. 启动job
boolean b = job.waitForCompletion(true);
// 提交job
submit();
// 如果参数为true,在监控job的执行,并打印日志。
monitorAndPrintJob();
// 提交job
return submitter.submitJobInternal(Job.this, cluster);
// 为Job 创建Split:对本次job操作的HDFS文件,进行split切片。
int maps = writeSplits(job, submitJobDir);
// 使用新API,创建split
maps = writeNewSplits(job, jobSubmitDir);
// 反射获得当前job绑定的InputFormat对象:TextInputFormat
InputFormat<?, ?> input = ReflectionUtils.newInstance(job.getInputFormatClass(), conf);
// 根据inputformat,获得split切片。(这里进入FileInputFormat类):
// InputSplit:offset length host
List<InputSplit> splits = input.getSplits(job);
|- 自此,进入split具体切片操作---->FileInputFormat
// 真正的提交job。
status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());
// 修改job的状态为RUNING
state = JobState.RUNNING;
/**
* 对文件生成逻辑上的切片Split,对应InputSplit,多个split对应List集合。
* @param job the job context
* @throws IOException
*/
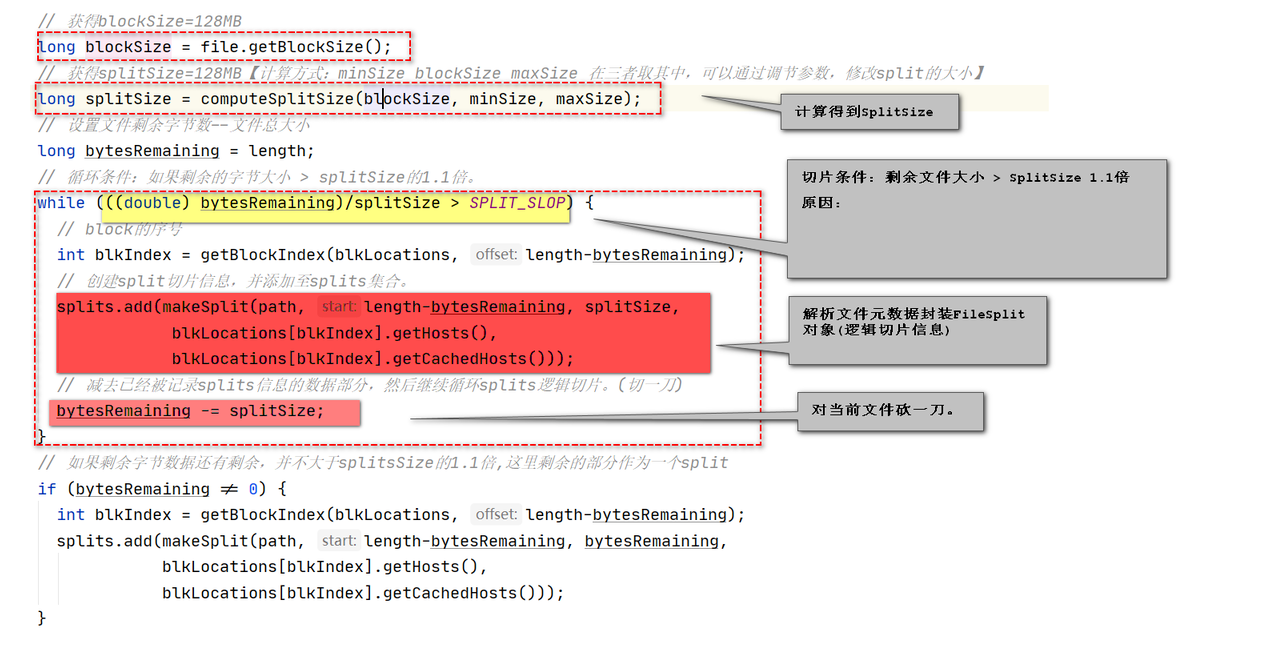
public List<InputSplit> getSplits(JobContext job) throws IOException{
// 最小值 1,本质上就是【mapreduce.input.fileinputformat.split.minsize】
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
// 最大值 LongMax, 本质上对应:【mapreduce.input.fileinputformat.split.maxsize】
long maxSize = getMaxSplitSize(job);
// 创建空的InputSplit的List,一会切一个,放里面放一个Split信息。
List<InputSplit> splits = new ArrayList<InputSplit>();
// 获得blockSize=128MB
long blockSize = file.getBlockSize();//128MB
// 获得splitSize=128MB【计算方式:minSize blockSize maxSize 在三者取其中,可以通过调节参数,修改split的大小】
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
// 循环条件:如果剩余的字节大小 > splitSize的1.1倍。
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
// block的序号
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
// 构造一个split(文件路径 start length host 内存host)
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
// 切一刀,减去当前split的字节数。
bytesRemaining -= splitSize;
}
}
# 重点1:SplitSize大小如何计算?
计算splitsize算法
splitsize = 三者取其中.
修改splitsize(切割大小):
1.如果想把splitsize(切割大小)放大:minsize(最小大小)参数修改大于128MB。
splitsize = mapreduce.input.fileinputformat.split.minsize2
如果想把splitsize(切割大小)放小:maxsize(最大大小)参数修改,小于128MB
splitsize = mapreduce.input.fileinputformat.split.maxsize
# 重点2:FileSplit每个计算任务范围,如何切分?
是否对剩余文件进行切片判断标准:
剩余大小 > splitsize * 1.1
目的:防止出现极小split切片,为此启动maptask浪费盗源
![]()
3. MapTask
启动MapTask
// map程序入口
public void run(final JobConf job, final TaskUmbilicalProtocol umbilical){
// 使用newMapper的API运行MapTask
runNewMapper(job, splitMetaInfo, umbilical, reporter);
}
private <INKEY,INVALUE,OUTKEY,OUTVALUE> void runNewMapper(final JobConf job,
final TaskSplitIndex splitIndex,
final TaskUmbilicalProtocol umbilical,
TaskReporter reporter
){
// 创建1一个Mapper对象
org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE> mapper =
(org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>)
ReflectionUtils.newInstance(taskContext.getMapperClass(), job);
// 创建一个输入工具,InputFormat
org.apache.hadoop.mapreduce.InputFormat<INKEY,INVALUE> inputFormat =
(org.apache.hadoop.mapreduce.InputFormat<INKEY,INVALUE>)
ReflectionUtils.newInstance(taskContext.getInputFormatClass(), job);
// 获得split信息。
split = getSplitDetails(new Path(splitIndex.getSplitLocation()),
splitIndex.getStartOffset());
// 创建一个RecordReader,inputformat中负责读取数据的。//LineRecordReader
org.apache.hadoop.mapreduce.RecordReader<INKEY,INVALUE> input =
new NewTrackingRecordReader<INKEY,INVALUE>
(split, inputFormat, reporter, taskContext);
// 初始化当前split范围的数据读取:开启输入流。
input.initialize(split, mapperContext);
//启动Mapper的run方法的执行。-------------------------【数据处理核心位置】
mapper.run(mapperContext);
// job 状态更新()
mapPhase.complete();
// 进入 NewOutputCollector?????
output.close(mapperContext);// 将清空环形缓冲区中的数据,最后溢写一次。
// 进入--->MapOutputBuffer:环形缓冲区对象
collector.flush();
// spill finished
resetSpill();
// 排序并溢写。下面继续
sortAndSpill();
// 合并溢写文件。到此MapTask阶段基本结束。
mergeParts();
// 关闭缓冲区的流
collector.close();
}
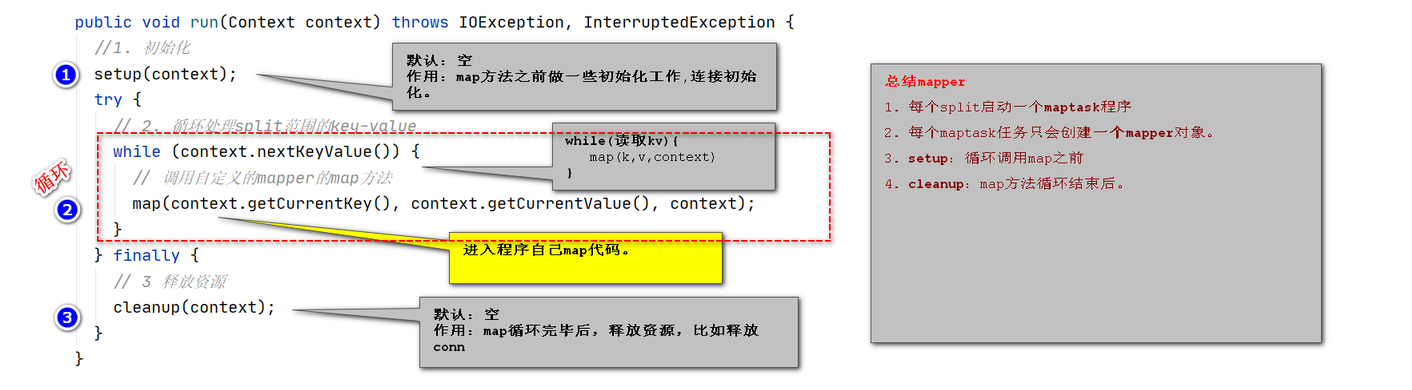
Mapper执行
// 一个split切片处理,创建一个Mapper对象
class 自定义Mapper extends Mapper{
public void run(Context context) throws IOException, InterruptedException{
//1: 调用setup 一次。:一般用来覆盖后,天加初始化资源操作。---调用1次。
setup(context);
// 循环读取 行数据 k(偏移量)-v(行)
while (context.nextKeyValue()) {
//2: 每读1行,调用1次map方法。
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
//3: 调用cleanup一次:一般覆盖,重写一些释放资源的代码----调用1次。
cleanup(context);
}
// 数据处理map方法:被子类覆盖。
protected void map(KEYIN key, VALUEIN value,
Context context) throws IOException, InterruptedException {}
}
![]()
MapOutputBuffer环形缓冲区
//MapTask内部类:环形缓冲区操作类类
private class NewOutputCollector<K,V>
extends org.apache.hadoop.mapreduce.RecordWriter<K,V> {
// map写出key-value,调用该方法。
@Override
public void write(K key, V value){
// 从Maper写出去:这里用的partition类,默认是HashPartition
// ----> MapOutputBuffer:缓冲区,暂时存放map的输出key-value
collector.collect(key, value,
partitioner.getPartition(key, value, partitions));
}
}
//环形缓冲区类
public static class MapOutputBuffer<K extends Object, V extends Object>{
// 将key value partition 存入环形缓冲区中。
public synchronized void collect(key,value){
// bufferRemaining参考:上面 spillper 和 softLimit
bufferRemaining -= METASIZE;// 环形缓冲区80%容量内,剩余多少。
// 如果缓冲区80% 用完了,多线程环形溢写线程,启动spill操作。
if (bufferRemaining <= 0) {
// 上次溢出完毕,回收空间
resetSpill();
// 下次开始溢写。
startSpill();
spillLock.unlock();// 唤醒SpillThread.run(),进入SpillTread类的run方法。
}
// 序列化key到缓冲区中。
int keystart = bufindex;
keySerializer.serialize(key);
// 序列化value到缓冲区中。
final int valstart = bufindex;
valSerializer.serialize(value);
}
}
spill溢写
// 溢写操作的线程类:MapTask内部类
protected class SpillThread extends Thread{
public void run() {
// 进入一次溢写。
sortAndSpill();// 一旦唤醒,就开始执行溢写操作。(溢写过程中,进行排序。)
// 进入环形缓冲区操作类的sortAndSpill方法内部
// 新建一个溢写文件,参数接受了一个分区数。
final SpillRecord spillRec = new SpillRecord(partitions);
// 快速排序,对环形缓冲区中的元素进行排序
sorter.sort(MapOutputBuffer.this, mstart, mend, reporter);
// 判断是否需要combine
if (combinerRunner == null) {
// 直接写入文件
}else{
// 先做combine再溢写。
}
}
}
4. ReduceTask
启动ReduceTask
public class ReduceTask extends Task{
public void run(JobConf job, final TaskUmbilicalProtocol umbilical){
runNewReducer(job, umbilical, reporter, rIter, comparator,
keyClass, valueClass);
}
private <INKEY,INVALUE,OUTKEY,OUTVALUE> void runNewReducer(JobConf job,
final TaskUmbilicalProtocol umbilical,
final TaskReporter reporter,
RawKeyValueIterator rIter,
RawComparator<INKEY> comparator,
Class<INKEY> keyClass,
Class<INVALUE> valueClass
) {
// 根据job绑定的Reducer的类,反射创建出Reducer对象。
org.apache.hadoop.mapreduce.Reducer<INKEY,INVALUE,OUTKEY,OUTVALUE> reducer =
(org.apache.hadoop.mapreduce.Reducer<INKEY,INVALUE,OUTKEY,OUTVALUE>)
ReflectionUtils.newInstance(taskContext.getReducerClass(), job);
// 进入Reducer的run方法
reducer.run(reducerContext);
}
}
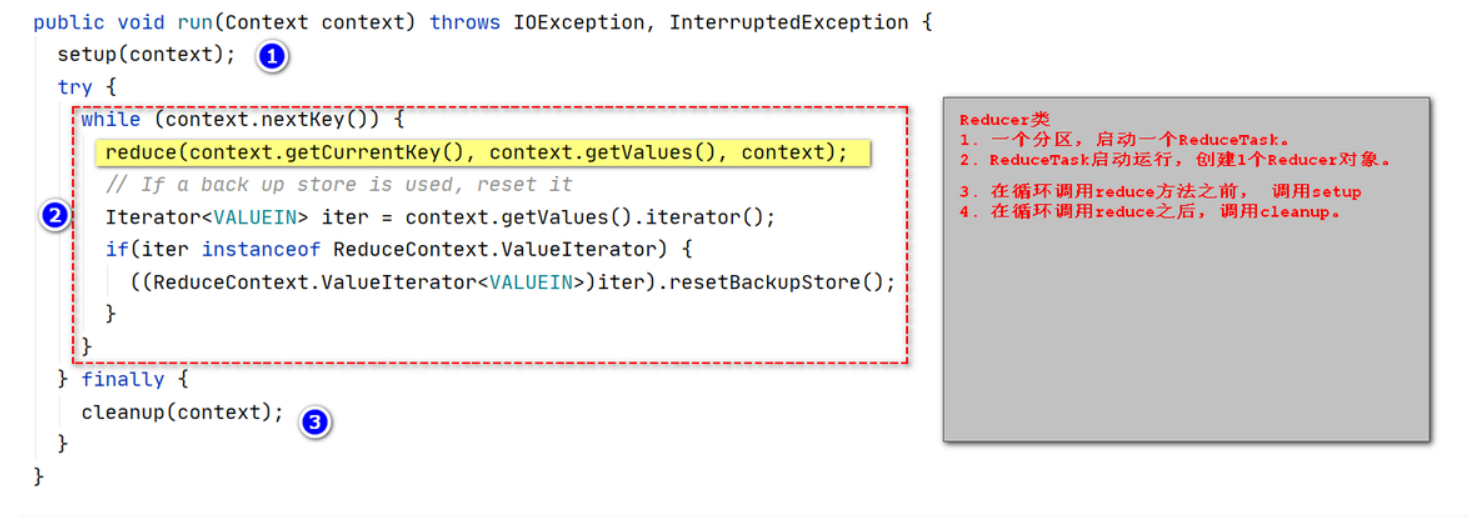
Reducer执行
/**
* 控制reduce任务如何工作
* ReduceTask处理一个合并结果,调用run
*/
public void run(Context context) throws IOException, InterruptedException {
//1. 调用setup方法。 1次。
setup(context);
try {
while (context.nextKey()) {
// 2:循环读取一组k-vs,调用reduce方法处理:循环调用。
reduce(context.getCurrentKey(), context.getValues(), context);
// 如果使用了备份存储,则重置它
Iterator<VALUEIN> iter = context.getValues().iterator();
if(iter instanceof ReduceContext.ValueIterator) {
((ReduceContext.ValueIterator<VALUEIN>)iter).resetBackupStore();
}
}
} finally {
// 3:调用cleanup方法。 reduce方法之后调用一次。
cleanup(context);
}
}
![]()
案例代码编写
案例文件
张三 语文 10
李四 数学 30
王五 语文 20
赵6 英语 40
张三 数据 50
李四 语文 10
张三 英语 70
李四 英语 80
王五 英语 45
王五 数学 10
赵6 数学 10
赵6 语文 100
编写实体类
package hadoop.PartitionWordJob;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* 实体
*/
public class Partition implements Writable {
private String name;//名字
private String subject;//科目
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(name);
dataOutput.writeUTF(subject);
}
public void readFields(DataInput dataInput) throws IOException {
name = dataInput.readUTF();
subject = dataInput.readUTF();
}
public Partition() {
}
public Partition(String name, String subject) {
this.name = name;
this.subject = subject;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSubject() {
return subject;
}
public void setSubject(String subject) {
this.subject = subject;
}
@Override
public String toString() {
return name + "\t" + subject;
}
}
定义排序
package hadoop.PartitionWordJob;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* 排序
*/
public class DESCWordJob implements WritableComparable<DESCWordJob> {
private Double score;
public int compareTo(DESCWordJob o) {
return (int)(o.score*100 - this.score*100);//因成绩为Double类型 强转为int类型会导致数据不准确
}
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeDouble(score);
}
public void readFields(DataInput dataInput) throws IOException {
score = dataInput.readDouble();
}
public DESCWordJob() {
}
public DESCWordJob(Double score) {
this.score = score;
}
public Double getScore() {
return score;
}
public void setScore(Double score) {
this.score = score;
}
@Override
public String toString() {
return "DESCWordJob{" +
"score=" + score +
'}';
}
}
定义分区
package hadoop.PartitionWordJob;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.mapreduce.Partitioner;
/**
* 分区
* Partitioner<DoubleWritable, Partition> MapperTask输出的键值类型
*/
public class GradePartition extends Partitioner<DoubleWritable, Partition> {
/**
* 根据 科目(subject) 计算分区号
* @param doubleWritable
* @param partition
* @param i
* @return
*/
public int getPartition(DoubleWritable doubleWritable, Partition partition, int i) {
// 1. 得到科目(subject)
String subject = partition.getSubject();
switch (subject){
case "语文" : return 0;
case "数学" : return 1;
case "英语" : return 2;
default : return 3;
}
}
}
定义MapReducer
package hadoop.PartitionWordJob;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
public class PartitionWordJob extends Configured implements Tool {
public static void main(String[] args) throws Exception {
ToolRunner.run(new PartitionWordJob(), args);
}
public int run(String[] strings) throws Exception {
//1. 初始化配置
Configuration entries = new Configuration();
entries.set("fs.defaultFS","hdfs://hadoop10:9000");
//2. 创建Job 并绑定Job所在的Java类
Job instance = Job.getInstance(entries);
instance.setJarByClass(PartitionWordJob.class);
/** 解决Hadoop处理大量小文件的问题 CombineTextInputFormat类
* //3. 组装Job 并设置输入格式化工具和输出格式化工具
* instance.setInputFormatClass(CombineTextInputFormat.class);
* instance.setOutputFormatClass(TextOutputFormat.class);
* //4. 组装Job 设置输入路径和输出路径
* //10M,只要加起来不超过10M的block数据,都会合并成1个split处理。
* CombineTextInputFormat.setMaxInputSplitSize(instance,1024*1024*10);
* CombineTextInputFormat .addInputPath(instance, new Path("/文件目录"));
* FileOutputFormat.setOutputPath(instance, new Path("/OutNameCount/definePartition"));
*/
//3. 组装Job 并设置输入格式化工具和输出格式化工具
instance.setInputFormatClass(TextInputFormat.class);
instance.setOutputFormatClass(TextOutputFormat.class);
//4. 组装Job 设置输入路径和输出路径
TextInputFormat.addInputPath(instance, new Path("/definePartition.txt"));
TextOutputFormat.setOutputPath(instance, new Path("/OutNameCount/definePartition"));
//5. 组装Job 绑定Mapper和Reducer的相关信息
instance.setMapperClass(PartitionWordCountJobMapper.class);
instance.setReducerClass(PartitionWordCountJobReducer.class);
// 绑定自定义分区类
instance.setPartitionerClass(GradePartition.class);
// 设置Reducer的个数--默认为1
instance.setNumReduceTasks(4);
//6. 绑定Mapper和Reducer的key-value类型
instance.setMapOutputKeyClass(DoubleWritable.class);
instance.setMapOutputValueClass(Partition.class);
instance.setOutputKeyClass(Partition.class);
instance.setOutputValueClass(DoubleWritable.class);
//7. 启动Job 并返回一个值
boolean b = instance.waitForCompletion(true);
return b ? 1 : 0;
}
/** Mapper 接受:k(偏移量)-v(行数据) 输出:k - v
* LongWritable: 输入的偏移量
* Text: 输入行数据
* Text: 输出的键
* Flow: 输出的值
*/
public static class PartitionWordCountJobMapper extends Mapper<LongWritable, Text, DoubleWritable, Partition> {
/**
* 执行时机:每读取一行k-v,调用一次map方法
* @param key
* @param value
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1. 接受kv value="张三 语文 10"
String[] split = value.toString().trim().split("\t");
System.out.println("split = " + split[0]);
String s = split[0];//获取名字
String s1 = split[1];//获取科目
String s2 = split[2];//获取成绩
//new DoubleWritable 对象进行排序(作为键输出) new Partition(作为值输出)
context.write(new DoubleWritable(Double.parseDouble(split[2])), new Partition(split[0], split[1]));
}
}
/**
* Text: 输入的键(FlowWordCountJobMapper 输出的键)
* Flow: 输入的值(FlowWordCountJobMapper 输出的值)
* Text: 输出的键
* Text: 输出的值
*/
public static class PartitionWordCountJobReducer extends Reducer<DoubleWritable, Partition, Partition, DoubleWritable> {
/**
*
* @param key 手机号 FlowWordCountJobMapper 输出的键
* @param values 集合 FlowWordCountJobMapper 输出的值
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(DoubleWritable key, Iterable<Partition> values, Context context) throws IOException, InterruptedException {
for (Partition value : values) {
context.write(value, key);
}
}
}
}


 浙公网安备 33010602011771号
浙公网安备 33010602011771号