scrapy爬虫框架
一、安装
#1 pip3 install scrapy(mac,linux)
#2 windows上(80%能成功,少部分人成功不了)
1、pip3 install wheel #安装后,便支持通过wheel文件安装软件,wheel文件官网:https://www.lfd.uci.edu/~gohlke/pythonlibs
3、pip3 install lxml
4、pip3 install pyopenssl
5、下载并安装pywin32:https://sourceforge.net/projects/pywin32/files/pywin32/
6、下载twisted的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
7、执行pip3 install 下载目录\Twisted-17.9.0-cp36-cp36m-win_amd64.whl
8、pip3 install scrapy
# 3 就有scrapy命令
-D:\Python36\Scripts\scrapy.exe 用于创建项目
二、框架简介
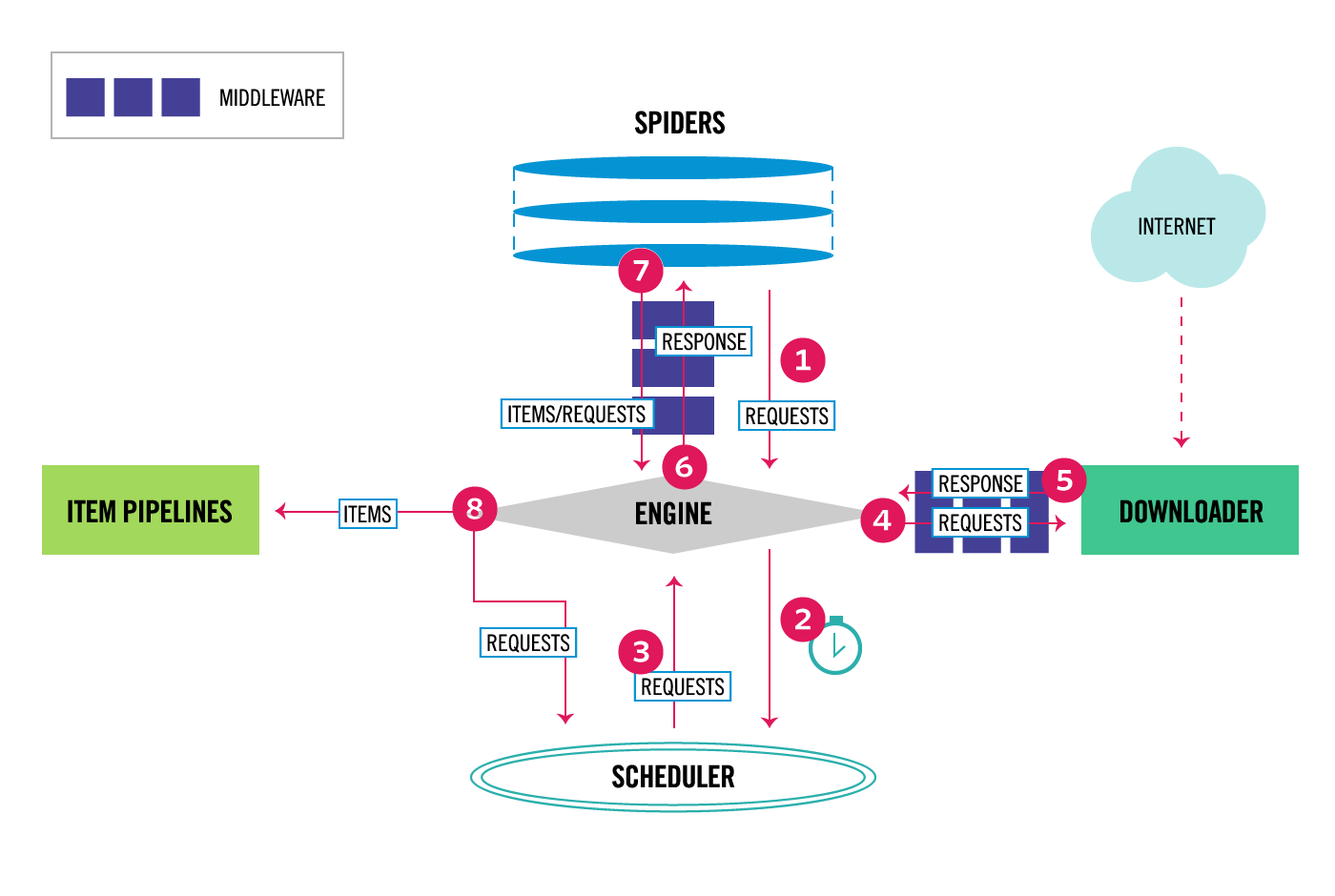
执行流程图
-
引擎(EGINE)
引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。有关详细信息,请参见上面的数据流部分。
(scrapy的核心,用于转发数据或请求,如果是数据,转到管道去保存,如果是请求,转到调度器,如果来的是响应对象,转给爬虫)
-
调度器(SCHEDULER)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL的优先级队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址(用于处理要爬取的url的顺序,深度优先/表示一条路走到黑,还是广度优先/表示同一层先爬下来,,去重)
-
下载器(DOWLOADER)
用于下载网页内容, 并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的(向外要爬取的地址发送请求)
-
爬虫(SPIDERS)
SPIDERS是开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求 -
项目管道(ITEM PIPLINES)
在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作(需要在settings中配置)
-
下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间,主要用来处理从EGINE传到DOWLOADER的请求request,已经从DOWNLOADER传到EGINE的响应response,你可用该中间件做以下几件事
- process a request just before it is sent to the Downloader (i.e. right before Scrapy sends the request to the website);
- change received response before passing it to a spider;
- send a new Request instead of passing received response to a spider;
- pass response to a spider without fetching a web page;
- silently drop some requests.
-
爬虫中间件(Spider Middlewares)
位于EGINE和SPIDERS之间,主要工作是处理SPIDERS的输入(即responses)和输出(即requests)
执行顺序:爬虫把要爬的url转发给引擎,引擎再转发给调度器,由调度器决定顺序,返回给引擎,引擎再把要爬取的url通过下载中间件(用于加个头,cookie啥的)向需要爬取的服务端发送请求,响应回来之后也通过下载中间件给引擎,引擎判断是响应数据之后,转发给爬虫,爬虫对数据进行处理,返回一个新的需要爬的地址(就继续上面的流程)或者需要保存的数据,数据部分由引擎转发给管道,保存数据
目录介绍
firstscrapy # 项目名字
firstscrapy # 包
-spiders # 所有的爬虫文件放在里面
-baidu.py # 一个个的爬虫(以后基本上都在这写东西)
-chouti.py
-middlewares.py # 中间件(爬虫,下载中间件都写在这)
-pipelines.py # 持久化相关写在这(items.py中类的对象)
-main.py # 自己加的,执行爬虫
-items.py # 一个一个的类,
-settings.py # 配置文件
scrapy.cfg # 上线相关
settings参数介绍
1 默认情况,scrapy会去遵循爬虫协议
2 修改配置文件参数,强行爬取,不遵循协议
-ROBOTSTXT_OBEY = False
3 USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
4 LOG_LEVEL='ERROR' # 运行的时候就不会把其他日志展示出来
三、基本使用
1 基本命令
# 创建项目
scrapy startproject firstscrapy
# 创建爬虫
scrapy genspider 爬虫名 爬虫地址
scrapy genspider chouti dig.chouti.com
# 一执行就会在spider文件夹下创建出一个py文件
# 运行爬虫
scrapy crawl chouti # 带运行日志
scrapy crawl chouti --nolog # 不带日志
# 支持右键执行爬虫
# 在项目路径下新建一个main.py
from scrapy.cmdline import execute
execute(['scrapy','crawl','chouti'])
2 数据解析
#xpath:
-response.xpath('//a[contains(@class,"link-title")]/text()').extract() # 取文本
-response.xpath('//a[contains(@class,"link-title")]/@href').extract() #取属性
#css
-response.css('.link-title::text').extract() # 取文本
-response.css('.link-title::attr(href)').extract_first() # 取属性
3 数据持久化
items.py
# 持久化匹配的字段
class ChoutiItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
laiyuan = scrapy.Field()
spiders/chouti.py
import scrapy
class ChoutiSpider(scrapy.Spider):
name = 'chouti'
allowed_domains = ['dig.chouti.com']
start_urls = ['http://dig.chouti.com/']
def parse(self, response):
# 返回要爬取的页面,或者返回要保存的数据
# 下面两者效果相同
from pachong.items import ChoutiItem
item = ChoutiItem()
div_list = response.css('.link-con .link-item')
# div_list = response.xpath('//div[contains(@class,"link-item")]')
for div in div_list:
title = div.css('.link-title::text').extract_first()
laiyuan = div.css('.link-from::text').extract_first()
# title = div.xpath('//a[contains(@class,"link-title")]/text()').extract()
if not laiyuan:
laiyuan = ''
print(title,laiyuan)
item['title'] = title
item['laiyuan'] = laiyuan
yield item
pipelines.py
import pymysql
class PachongPipeline:
def open_spider(self,spider):
self.conn = pymysql.connect(host='127.0.0.1', user='root', password="root",
database='pachong', port=3306)
def process_item(self, item, spider):
cursor = self.conn.cursor()
sql = 'insert into chouti (title,laiyuan)values(%s,%s)'
cursor.execute(sql,[item['title'],item['laiyuan']])
self.conn.commit()
return item
def close_spider(self,spider):
self.conn.close()
settings.py
ITEM_PIPELINES = {
'pachong.pipelines.PachongPipeline': 300,
}
# 配置优先级
四、scrapy高级
1 提升scrapy爬取数据的效率
- 在配置文件中进行相关的配置即可:(默认还有一套setting)
#1 增加并发:
默认scrapy开启的并发线程为32个,可以适当进行增加。在settings配置文件中修改CONCURRENT_REQUESTS = 100值为100,并发设置成了为100。
#2 降低日志级别:
在运行scrapy时,会有大量日志信息的输出,为了减少CPU的使用率。可以设置log输出信息为INFO或者ERROR即可。在配置文件中编写:LOG_LEVEL = ‘INFO’
# 3 禁止cookie:
如果不是真的需要cookie,则在scrapy爬取数据时可以禁止cookie从而减少CPU的使用率,提升爬取效率。在配置文件中编写:COOKIES_ENABLED = False
# 4禁止重试:
对失败的HTTP进行重新请求(重试)会减慢爬取速度,因此可以禁止重试。在配置文件中编写:RETRY_ENABLED = False
# 5 减少下载超时:
如果对一个非常慢的链接进行爬取,减少下载超时可以能让卡住的链接快速被放弃,从而提升效率。在配置文件中进行编写:DOWNLOAD_TIMEOUT = 10 超时时间为10s
2 scrapy的中间件(下载中间件)
# 1 都写在middlewares.py
# 2 爬虫中间件
# 3 下载中间件
# 4 要生效,一定要配置,配置文件
# 下载中间件
-process_request:返回不同的对象,后续处理不同(加代理...)
# 1 更换请求头
# print(type(request.headers))
# print(request.headers)
#
# from scrapy.http.headers import Headers
# request.headers['User-Agent']=''
# 2 加cookie ---cookie池
# 假设你你已经搭建好cookie 池了,
# print('00000--',request.cookies)
# request.cookies={'username':'asdfasdf'}
# 3 加代理
# print(request.meta)
# request.meta['download_timeout'] = 20
# request.meta["proxy"] = 'http://27.188.62.3:8060'
-process_response:返回不同的对象,后续处理不同
- process_exception
def process_exception(self, request, exception, spider):
print('xxxx')
# 不允许直接改url
# request.url='https://www.baidu.com'
from scrapy import Request
request=Request(url='https://www.baidu.com',callback=spider.parser)
return request
3 selenium在scrapy中的使用流程
# 当前爬虫用的selenium是同一个
# 1 在爬虫中初始化webdriver对象
from selenium import webdriver
class CnblogSpider(scrapy.Spider):
name = 'cnblog'
...
bro=webdriver.Chrome(executable_path='../chromedriver.exe')
# 2 在中间件中使用(process_request)
spider.bro.get('https://dig.chouti.com/') response=HtmlResponse(url='https://dig.chouti.com/',body=spider.bro.page_source.encode('utf-8'),request=request)
return response
# 3 在爬虫中关闭
def close(self, reason):
print("我结束了")
self.bro.close()
4 分布式爬虫(scrapy-redis)
# 1 pip3 install scrapy-redis
# 2 原来继承Spider,现在继承RedisSpider
# 3 不能写start_urls = ['https:/www.cnblogs.com/']
# 4 需要写redis_key = 'myspider:start_urls'
# 5 setting中配置:
# redis的连接
REDIS_HOST = 'localhost' # 主机名
REDIS_PORT = 6379 # 端口
# 使用scrapy-redis的去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 使用scrapy-redis的Scheduler
# 分布式爬虫的配置
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 持久化的可以配置,也可以不配置
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 299
}
# 9现在要让爬虫运行起来,需要去redis中以myspider:start_urls为key,插入一个起始地址lpush myspider:start_urls https://www.cnblogs.com/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号