

Spark-Core RDD依赖关系
scala> var rdd1 = sc.textFile("./words.txt")
rdd1: org.apache.spark.rdd.RDD[String] = ./words.txt MapPartitionsRDD[16] at textFile at <console>:24
scala> val rdd2 = rdd1.flatMap(_.split(" "))
rdd2: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[17] at flatMap at <console>:26
scala> val rdd3 = rdd2.map((_, 1))
rdd3: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[18] at map at <console>:28
scala> val rdd4 = rdd3.reduceByKey(_ + _)
rdd4: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[19] at reduceByKey at <console>:30
1、查看 RDD 的血缘关系
scala> rdd1.toDebugString
res1: String =
(2) ./words.txt MapPartitionsRDD[1] at textFile at <console>:24 []
| ./words.txt HadoopRDD[0] at textFile at <console>:24 []
scala> rdd2.toDebugString
res2: String =
(2) MapPartitionsRDD[2] at flatMap at <console>:26 []
| ./words.txt MapPartitionsRDD[1] at textFile at <console>:24 []
| ./words.txt HadoopRDD[0] at textFile at <console>:24 []
scala> rdd3.toDebugString
res3: String =
(2) MapPartitionsRDD[3] at map at <console>:28 []
| MapPartitionsRDD[2] at flatMap at <console>:26 []
| ./words.txt MapPartitionsRDD[1] at textFile at <console>:24 []
| ./words.txt HadoopRDD[0] at textFile at <console>:24 []
scala> rdd4.toDebugString
res4: String =
(2) ShuffledRDD[4] at reduceByKey at <console>:30 []
+-(2) MapPartitionsRDD[3] at map at <console>:28 []
| MapPartitionsRDD[2] at flatMap at <console>:26 []
| ./words.txt MapPartitionsRDD[1] at textFile at <console>:24 []
| ./words.txt HadoopRDD[0] at textFile at <console>:24 []
说明:
圆括号(2): 2表示RDD的并行度,几个分区
2、查看RDD的依赖关系
scala> rdd1.dependencies
res28: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.OneToOneDependency@70dbde75)
scala> rdd2.dependencies
res29: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.OneToOneDependency@21a87972)
scala> rdd3.dependencies
res30: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.OneToOneDependency@4776f6af)
scala> rdd4.dependencies
res31: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.ShuffleDependency@4809035f)
RDD之间的关系可以从两个维度来理解:
(1)一个是RDD从哪些RDD转换而来,也就是RDD的parent RDD(s)是什么
(2)另一个是RDD依赖于parent RDD(s)的哪些 Partitions(s),这种关系称为RDD之间的依赖
RDD依赖的 2 中策略:
(1)窄依赖(transformations with narrow dependencies)
(2)宽依赖(transformations with wide dependencies)
宽依赖对 Spark 去评估一个 transformations 有更加重要的影响, 比如对性能的影响.
3、窄依赖
如果 B-RDD 是由 A-RDD 计算得到的, 则 B-RDD 就是Child RDD, A-RDD 就是 parent RDD.
如果依赖关系在设计的时候就可以确定,而不需要考虑父RDD分区中的记录。并且如果父RDD中的每个分区最多只有一个分区,这样的依赖就是窄依赖
总结:父RDD的每个分区最多被一个RDD的分区使用
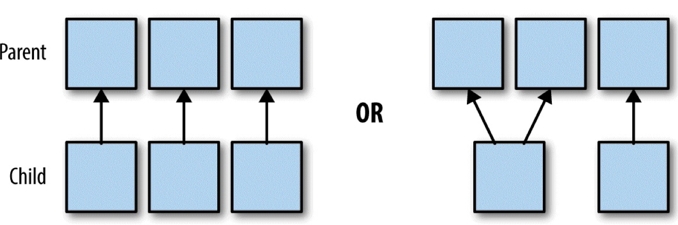
具体来说,窄依赖的时候,子RDD中的分区要么只依赖一个父RDD中的一个分区(map,filter),要么在设计的时候就能确定子RDD是父RDD的一个子集(coalesce)
所以, 窄依赖的转换可以在任何的的一个分区上单独执行, 而不需要其他分区的任何信息.
4、宽依赖
如果 父 RDD 的分区被不止一个子 RDD 的分区依赖, 就是宽依赖.
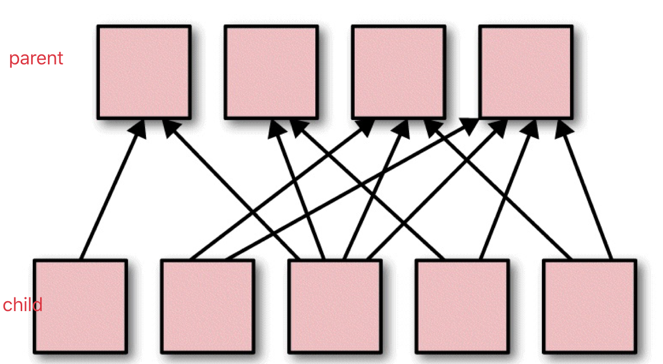
宽依赖工作的时候, 不能随意在某些记录上运行, 而是需要使用特殊的方式(比如按照 key)来获取分区中的所有数据.
例如: 在排序(sort)的时候, 数据必须被分区, 同样范围的 key 必须在同一个分区内. 具有宽依赖的 transformations 包括: sort, reduceByKey, groupByKey, join, 和调用rePartition函数的任何操作.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号