

LRU Cache
2018-11-05 21:05:38
LRU是Least Recently Used的缩写,即最近最少使用,常用于页面置换算法,是为虚拟页式存储管理服务。
LRU算法的提出,是基于这样一个事实:在前面几条指令中使用频繁的页面很可能在后面的几条指令中频繁使用。反过来说,已经很久没有使用的页面很可能在未来较长的一段时间内不会被用到。这个,就是著名的局部性原理——比内存速度还要快的cache,也是基于同样的原理运行的。因此,我们只需要在每次调换时,找到最近最久未使用的那个页面调出内存。这就是LRU算法的全部内容。
下面我们使用Java来实现一个高效的LRU Cache。
问题描述:
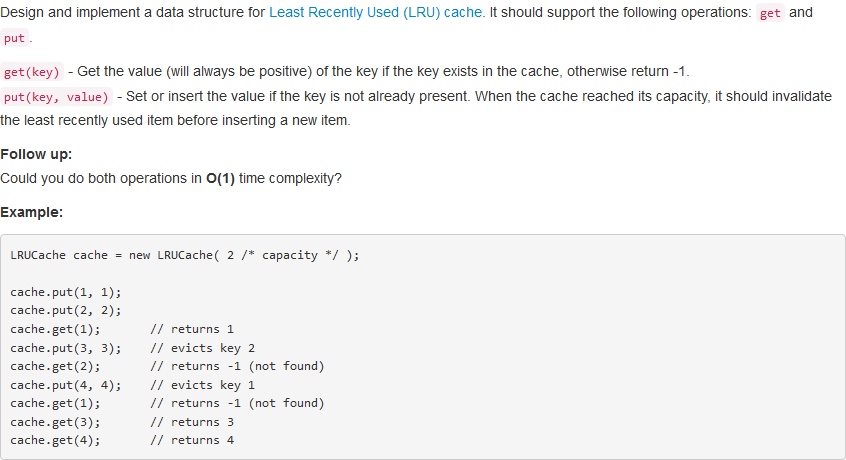
问题求解:
首先如果要高效的get一个数值,那么首选的自然是hash,但是需要注意的是这里get之后需要对Cache进行维护,也就是说当前get到的数据目前应该在Cache的最前端,如何快速的更改位置,自然会想到链表。另外,由于在put数据的时候,可能会产生数据量超过容量的情况,这个时候需要删除链表的最后一个元素,如果使用普通的链表,那么这里的开销就是O(n)的时间复杂度,那么如何将这里的开销降到最低呢?答案就是使用双向链表并且增加一个tail节点,这样就可以非常迅速的对尾节点进行删除操作。
public class LRUCache {
int capacity;
int count;
CacheNode head; // 方便在头部添加节点
CacheNode tail; // 方便删除最后一个节点
Map<Integer, CacheNode> key2node;
public LRUCache(int capacity) {
this.capacity = capacity;
this.count = 0;
this.key2node = new HashMap<>();
this.head = new CacheNode(-1, -1);
this.tail = new CacheNode(Integer.MAX_VALUE, Integer.MAX_VALUE);
this.head.next = tail;
this.tail.pre = head;
}
public int get(int key) {
if (capacity == 0) return -1;
if (key2node.containsKey(key)) {
int res = key2node.get(key).val;
delete(key2node.get(key));
addToHead(key2node.get(key));
return res;
}
return -1;
}
public void put(int key, int value) {
if (capacity == 0) return;
if (key2node.containsKey(key)) {
key2node.get(key).val = value;
delete(key2node.get(key));
addToHead(key2node.get(key));
}
else {
maintainSize();
CacheNode node = new CacheNode(key, value);
key2node.put(key, node);
addToHead(node);
count++;
}
}
private void delete(CacheNode node) {
node.pre.next = node.next;
node.next.pre = node.pre;
}
private void addToHead(CacheNode node) {
node.next = head.next;
head.next.pre = node;
head.next = node;
node.pre = head;
}
private void maintainSize() {
if (count == capacity) {
key2node.remove(tail.pre.key);
delete(tail.pre);
count--;
}
}
}
class CacheNode {
public int key; // 方便在删除尾部节点的时候维护Map
public int val;
public CacheNode pre;
public CacheNode next;
public CacheNode(int key, int val) {
this.key = key;
this.val = val;
this.pre = null;
this.next = null;
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号