

优化算法
2018-12-07 14:41:57
一、SGD 和 BGD
BGD:又称Vanilla梯度下降法,用运行整个训练集(一个epoch)来做一次更新。
SGD:运行一个或者几个batch(Minibatch Stochastic gradient Descent)时来更新一次更新。
BGD:
for i in range(nb_epochs):
params_grad = evaluate_gradient(loss_function, data, params)
params = params - learning_rate * params_grad
SGD:
for i in range(nb_epochs):
np.random.shuffle(data)
for example in data:
params_grad = evaluate_gradient(loss_function, example, params)
params = params - learning_rate * params_grad
二、带有动量梯度下降法
我们先看一下随机梯度下降的示意图:

很显然,我们希望下降的方向在纵轴上减小,在横轴上加大,正如红线所示,这样就能更快的到达最中心点的位置。那么如果做到这一点呢?
其中一个想法就是取均值不就可以完成上述的要求了么?纵轴上由于波动取均值后波动会减少,横轴上由于方向一致,取均值后会加快横轴的进度。这就诞生了带有动量的梯度下降法。
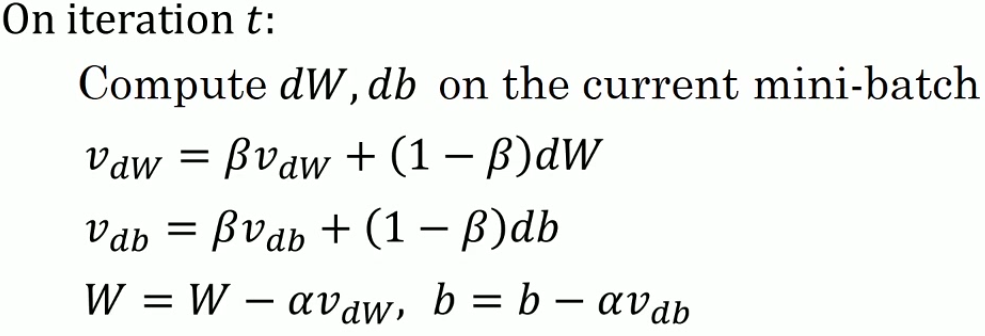
这里取均值使用了指数加权平均的思路。Beta ~= 0.9 / 0.99
为什么叫带有动量的梯度下降呢,因为在很多地方这个公式是使用物理学的方式进行解释的,也就是说,可以将这个公式使用物理学里面的速度,摩擦力,动量等概念进行形象的描述,当然这种方式对物理学得好的同学来说理解起来是会更方便,这里就不多介绍了。
三、RMSProp
RMSProp : root mean square prop算法。
RMSProp是在计算dw ^ 2的均值,最后使用dw / mean(dw ^ 2)来更新w,这样做的目的是为了减小w的剧烈晃动,因为dw ^ 2的含义可以看成x ^ 2 + y ^ 2,求均值就是将横轴的值和纵轴的平方值相加,纵轴晃动过大,当除以这个数的时候就会得到小的数,横轴求和相对较小,当除这个数的时候就可以加速横轴的速度。
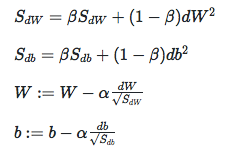
为了避免分母为0,一般可以加上一个小数如1e-7。
四、Adam
有了上面两种算法的铺垫,Adam算法其实就非常简单了,所谓Adam算法其实就是将上述的两种算法进行了组合,在RMSProp中很显然的,我们可以使用均值来替代dw,db,如果这样做了,那么就得到了Adam算法。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号