EFK
下载安装EFK
导入 GPG 密钥
sudo rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
在 /etc/yum.repos.d/ 目录下创建一个新的仓库配置文件,例如 elasticsearch.repo。
[elastic-8.x]
name=Elastic repository for 8.x packages
baseurl=https://artifacts.elastic.co/packages/8.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
sudo yumdownloader --releasever=7 filebeat-8.13.4
sudo yumdownloader --releasever=7 elasticsearch-8.13.4
sudo yumdownloader --releasever=7 kibana-8.13.4
releasever=7 :
表示指定使用 CentOS 7 或者 RHEL 7(Red Hat Enterprise Linux 7)
这类基于 RHEL 7 分支的操作系统版本的软件仓库配置
rpm -ivh filebeat-8.13.4-x86_64.rpm
rpm -ivh elasticsearch-8.13.4-x86_64.rpm
rpm -ivh kibana-8.13.4-x86_64.rpm
rpm卸载
sudo systemctl stop elasticsearch
sudo systemctl disable elasticsearch
sudo rpm -e elasticsearch // 卸载 rpm 软件包
sudo rm -rf /etc/elasticsearch // 删除配置文件
sudo rm -rf /var/lib/elasticsearch // 删除数据文件
sudo rm -rf /var/log/elasticsearch // 删除日志文件
sudo rm -f /usr/lib/systemd/system/elasticsearch.service
sudo systemctl daemon-reload // 重新加载 systemd 管理器配置
rpm -qa | grep elasticsearch // 查看是否卸载干净
安装Elasticsearch
vi /etc/elasticsearch/elasticsearch.yml
# ---------------------------------- Cluster -----------------------------------
# Use a descriptive name for your cluster:
cluster.name: Wise_ES
# ----------------------------------- Paths ------------------------------------
# Path to directory where to store the data (separate multiple locations by comma):
path.data: /var/lib/elasticsearch
# Path to log files:
path.logs: /var/log/elasticsearch
# ---------------------------------- Network -----------------------------------
# Set the bind address to a specific IP (IPv4 or IPv6):
network.host: 192.168.248.20
# Set a custom port for HTTP:
http.port: 9200
# --------------------------------- Discovery ----------------------------------
# Bootstrap the cluster using an initial set of master-eligible nodes:
cluster.initial_master_nodes: ["Wise_ES"]
# --------------------------------------------------------------------------------
xpack.security.enabled: false # 系统不会开启身份验证、授权、加密等安全特性
xpack.security.enrollment.enabled: false # 禁用 Elasticsearch 的节点自动加入集群的功能
xpack.security.http.ssl.enabled: false # 禁用 Elasticsearch 的 HTTP 和传输层之间的 SSL/TLS 加密
xpack.security.transport.ssl.enabled: false # 禁用 Elasticsearch 的节点间通信的 SSL/TLS 加密
systemctl start elasticsearch
systemctl enable elasticsearch
curl -X GET "192.168.248.20:9200/_cat/indices?v" # 查看索引
curl -X GET "192.168.248.20:9200/nginx-access-2025.04/_mapping?pretty" # 查看索引详情
curl -X DELETE "192.168.248.20:9200/.task*" # 删除索引
安装 Kibana
vi /etc/kibana/kibana.yml
server.port: 5601
server.host: "192.168.248.20"
elasticsearch.hosts: ["http://192.168.248.20:9200"]
i18n.locale: "zh-CN" # 添加这一行,设置为中文
# logging.dest: /path/to/your/custom/log/file.log
xpack.encryptedSavedObjects.enabled: false # 关闭 Kibana 的加密密钥
systemctl start kibana
systemctl enable kibana
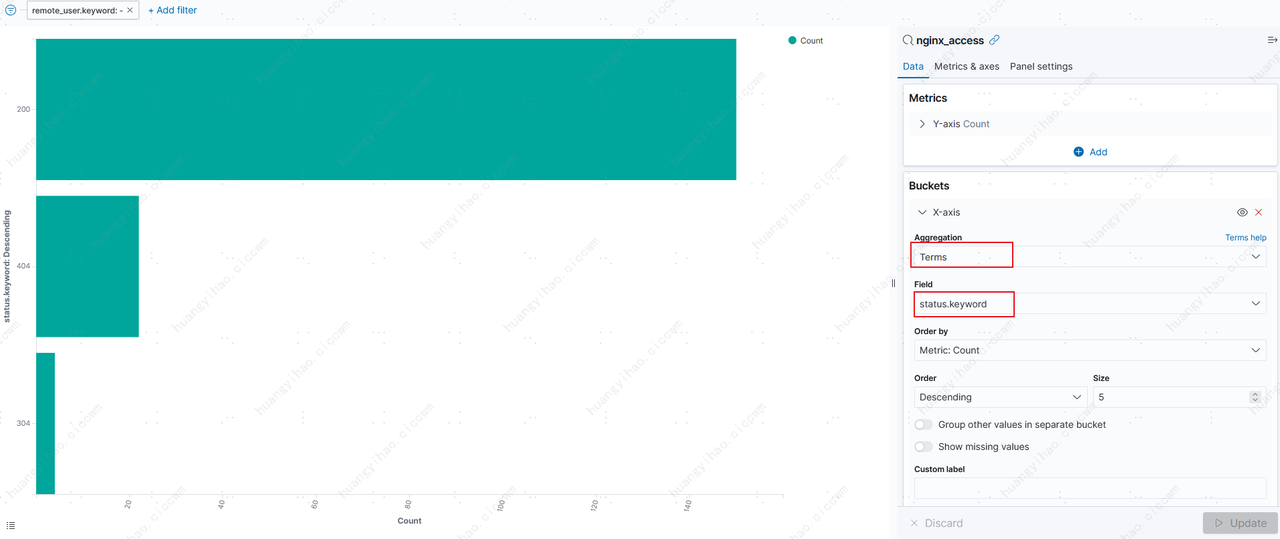
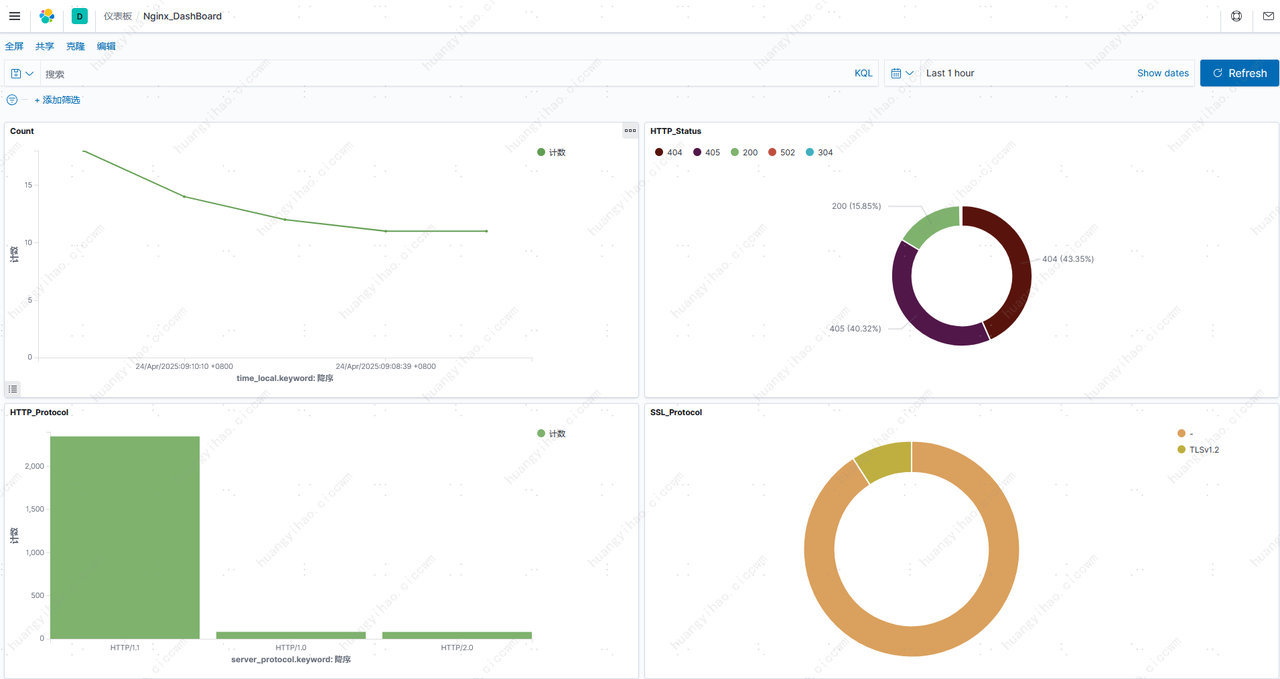
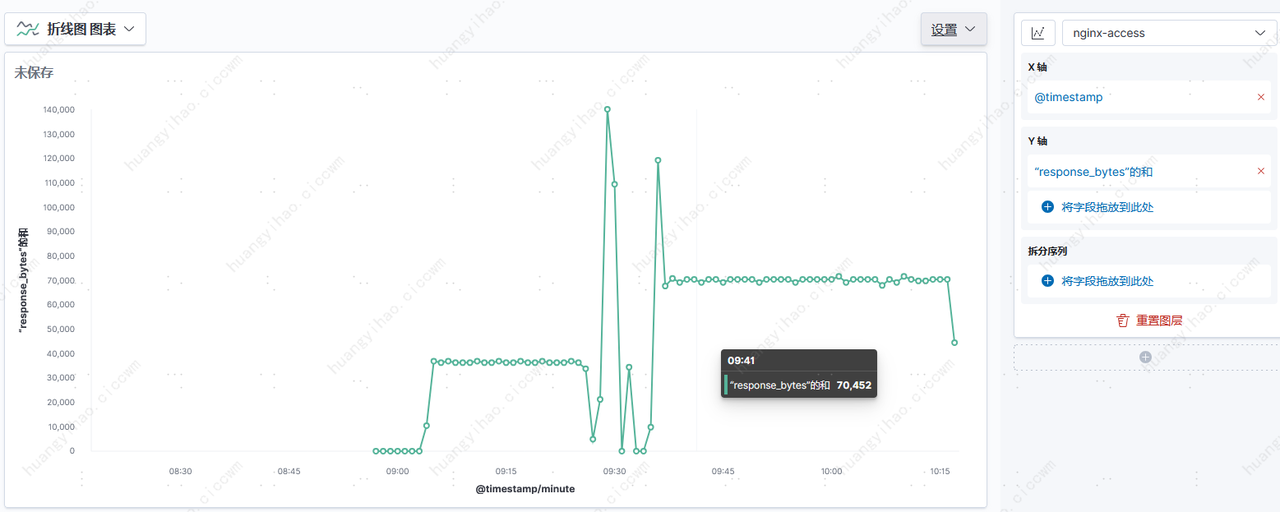
安装 Filebeat
filebeat工作流程
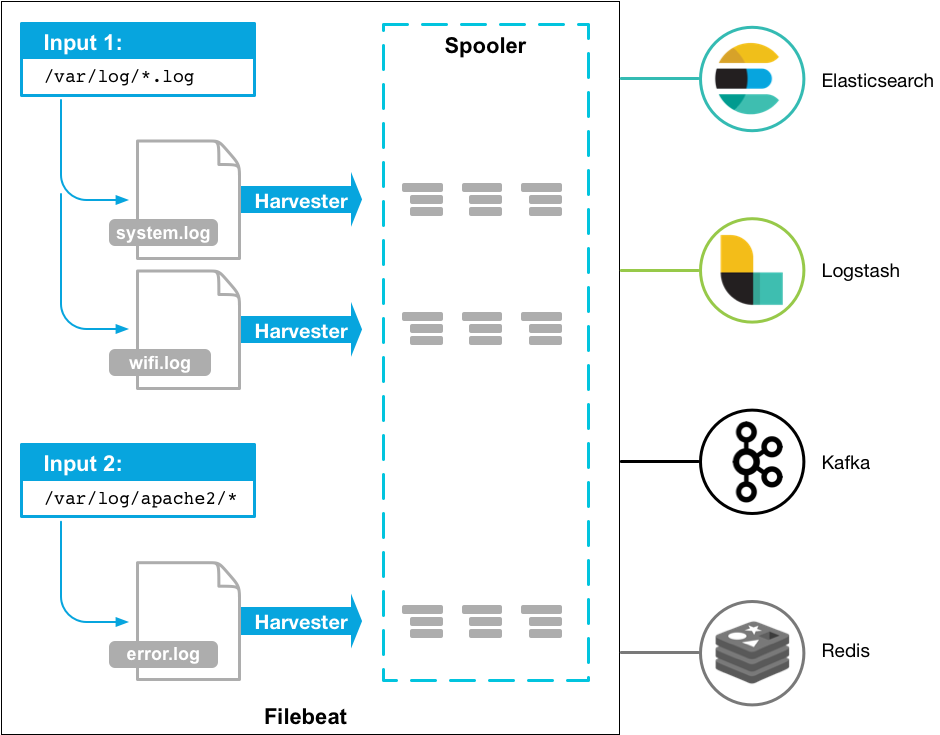
1. Inputs
输入模块定义了 Filebeat 要监控的日志源。
2. Prospector
- 监控输入模块指定的日志源(如文件路径),检测文件的新增、修改或删除事件。
- 为每个符合条件的文件(如未被监控过的新文件、有更新的旧文件)创建对应的 Harvester。
例如,若输入配置为监控 /var/log/*.log,Prospector 会定期扫描该目录,发现新日志文件时立即启动 Harvester 读取数据。
3. Harvester:
每个被监控的文件对应一个 Harvester 实例
- 逐行读取文件内容(仅读取新增数据,避免重复采集)
- 记录文件的 偏移量(Offset):通过记录文件的当前读取位置(如字节位置或行号),确保重启后能从上次中断的位置继续读取。
- 如果在读取时文件重命名或删除,磁盘空间会被保留直到 harvester 关闭
4. 事件处理与元数据添加
Harvester 读取到日志数据后,会将其封装为 事件(Event),并自动添加元数据(如文件路径、采集时间、主机名等)。
5. Outputs
Filebeat 收集到事件后,会将其发送到配置的输出目标。
filebeat命令
filebeat test config # 检查配置文件是否有语法错误
filebeat test output # 检查配置文件是否有语法错误,并尝试连接到输出目标(如Elasticsearch)以验证连接性
filebeat modules list # 列出所有可用的模块
filebeat version # 查看 Filebeat 的版本信息
filebeat modules enable nginx # 启用 nginx 日志采集模块
filebeat export config # 导出配置文件到当前目录,默认路径为 /etc/filebeat
filebeat export config --path.config /etc/filebeat # 导出配置文件到指定路径
filebeat采集Nginx
Json to Json
缺点:会导致数据类型都是String,kibana制图时无法进行数值计算
Nginx日志格式
log_format json '{'
'"remote_addr":"$remote_addr",'
'"remote_user":"$remote_user",'
'"time_local":"$time_local",'
'"method":"$request_method",'
'"uri":"$request_uri",'
'"status_code":"$status",'
'"response_bytes":"$body_bytes_sent",'
'"referer":"$http_referer",'
'"user_agent":"$http_user_agent",'
'"x_forwarded_for":"$http_x_forwarded_for",'
'"server_protocol":"$server_protocol",'
'"ssl_protocol":"$ssl_protocol"}';
access_log /var/log/nginx/access.log json;
配置解释
$request_method:Nginx 内置变量,用于获取请求的 HTTP 方法,如 GET、POST 等。
$request_uri:用于获取完整的请求 URI,包括路径和查询参数。
$server_protocol:表示请求使用的 HTTP 协议版本,如 HTTP/1.1、HTTP/2 等
$request = $request_method + $request_uri + $server_protocol
建议做拆分
Filebeat配置
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
json.keys_under_root: true # JSON 数据中的字段会成为 Filebeat 事件的顶级字段
json.overwrite_keys: true # 在解析 JSON 数据时,JSON 对象中的某个键与 Filebeat 事件中已存在的键名冲突,JSON 数据中的值会覆盖 Filebeat 事件中原有键的值
output.elasticsearch:
hosts: ["192.168.248.70:9200"]
bulk_max_size: 2048 # 每次批量请求发送的最大事件数
flush_interval: 5s # 批量刷新的时间间隔
index: "nginx_test"
setup.ilm.enabled: false
setup.template.enabled: false
- bulk_max_size:表示每次批量发送到 Elasticsearch 的最大事件数量。当收集到的事件数量达到这个值时,Filebeat 会立即将这些事件推送到 Elasticsearch。
- flush_interval:表示无论收集到的事件数量是否达到 bulk_max_size,Filebeat 每隔flush_interval 秒就会将已收集到的事件推送到 Elasticsearch。
String to Json
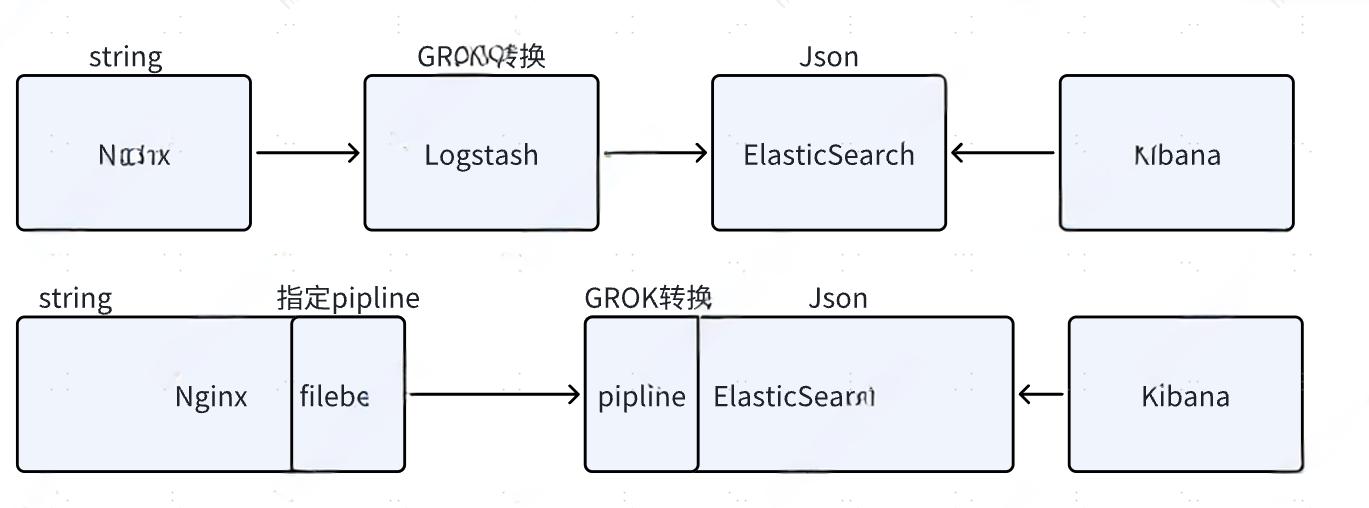
Nginx日志格式
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
Nginx日志样式
192.168.248.10 - - [29/May/2025:11:06:56 +0800] "GET / HTTP/1.1" 200 245 "-" "curl/7.29.0" "-"
192.168.248.50 - - [29/May/2025:11:06:59 +0800] "GET / HTTP/1.1" 200 245 "-" "curl/7.29.0" "-"
192.168.248.60 - - [29/May/2025:11:07:01 +0800] "GET / HTTP/1.1" 200 245 "-" "curl/7.29.0" "-"
Grok
%{IP:remote_addr} - %{DATA:remote_user} \[%{HTTPDATE:time_local}\] \"%{DATA:method} %{DATA:uri} %{DATA:server_protocol}\" %{NUMBER:status_code:long} %{NUMBER:response_bytes:long} \"%{DATA:referer}\" \"%{DATA:user_agent}\" \"%{DATA:x_forwarded_for}\"
Grok测试路径:
192.168.248.70:5601 > Management > 开发工具 > Grok Debugger

创建pipeline
Grok和pipeline的写法有点区别,注意转义
PUT _ingest/pipeline/mynginx
{
"description": "Wise Nginx Access Log",
"processors": [
{
"grok": {
"field": "message",
"patterns": [
"%{IP:remote_addr} - %{DATA:remote_user} \\[%{HTTPDATE:time_local}\\] \"%{DATA:method} %{DATA:uri} %{DATA:server_protocol}\" %{NUMBER:status_code:long} %{NUMBER:response_bytes:long} \"%{DATA:referer}\" \"%{DATA:user_agent}\" \"%{DATA:x_forwarded_for}\""
]
}
},
{
"remove": {
"field": "message"
}
}
]
}
测试pipeline
192.168.248.10 - - [29/May/2025:11:06:56 +0800] "GET / HTTP/1.1" 200 245 "-" "curl/7.29.0" "-"
以这条日志为例[需要进行转义,即在双引号前面加上反斜杠]
POST _ingest/pipeline/test/_simulate
{
"docs": [
{
"_source": {
"message": "192.168.248.10 - - [29/May/2025:11:06:56 +0800] \"GET / HTTP/1.1\" 200 245 \"-\" \"curl/7.29.0\" \"-\""
}
}
]
}
Filebeat配置
logging.json: true
filebeat.inputs:
- type: filestream
id: nginx-access
paths:
- /var/log/nginx/access.log
fields_under_root: true
processors:
- drop_fields:
fields: ["agent.name", "agent.ephemeral_id", "agent.type", "agent.version", "log.offset", "agent.id"]
ignore_missing: true
output.elasticsearch:
hosts: ["192.168.248.70:9200"]
pipeline: "mynginx"
indices:
- index: "nginx-access"
踩坑
Cannot index event publisher.Event{Content:beat.Event{Timestamp:time.Time
背景:这个报错出现在同时两台Nginx通过不同方式推送到相同索引时出现
根本原因:原有的Nginx是Json To Json模式,对应的字段是string类型
而在使用String To Json时,使用grok转化了两个字段的数据类型
解决方法:统一Nginx的推送方式[推荐:Json to Json],更换新的索引即可
在创建pipline时,使用的名称是MyNginx,配置filebeat时也是使用的MyNginx,但是日志里显示的是mynginx
解决方法:重新创建pipeline时,都用小写

 浙公网安备 33010602011771号
浙公网安备 33010602011771号