

k8s下安装metrics-server
环境:
OS:Centos 7
k8s:1.24.0
1.部署了hpa后发现无法获取指标数据
[root@master hpa]# kubectl describe hpa nginx-deployment-hpa -n ns-hpa
Warning: autoscaling/v2beta2 HorizontalPodAutoscaler is deprecated in v1.23+, unavailable in v1.26+; use autoscaling/v2 HorizontalPodAutoscaler
Name: nginx-deployment-hpa
Namespace: ns-hpa
Labels: <none>
Annotations: <none>
CreationTimestamp: Wed, 09 Apr 2025 17:20:38 +0800
Reference: Deployment/nginx-deployment
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): <unknown> / 50%
Min replicas: 1
Max replicas: 10
Deployment pods: 1 current / 0 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True SucceededGetScale the HPA controller was able to get the target's current scale
ScalingActive False FailedGetResourceMetric the HPA was unable to compute the replica count: failed to get cpu utilization: unable to get metrics for resource cpu: unable to fetch metrics from resource metrics API: the server could not find the requested resource (get pods.metrics.k8s.io)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedGetResourceMetric 2m37s (x1140 over 4h47m) horizontal-pod-autoscaler failed to get cpu utilization: unable to get metrics for resource cpu: unable to fetch metrics from resource metrics API: the server could not find the requested resource (get pods.metrics.k8s.io)
the HPA was unable to compute the replica count: failed to get cpu utilization: unable to get metrics for resource cpu: unable to fetch metrics from resource metrics API: the server could not find the requested resource (get pods.metrics.k8s.io)
[root@master hpa]# kubectl get hpa -n ns-hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx-deployment-hpa Deployment/nginx-deployment <unknown>/50% 1 10 1 39s
2.需要安装metrics-server
获取yaml配置文件
wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
重命名
mv components.yaml metrics-server.yaml
修改镜像为阿里云镜像
image: registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server:v0.7.2
应用
kubectl apply -f metrics-server.yaml
3.发现包如下错误
Readiness probe failed: HTTP probe failed with statuscode: 500
解决办法:
解决办法:
kubectl delete -f metrics-server.yaml
vi metrics-server.yaml
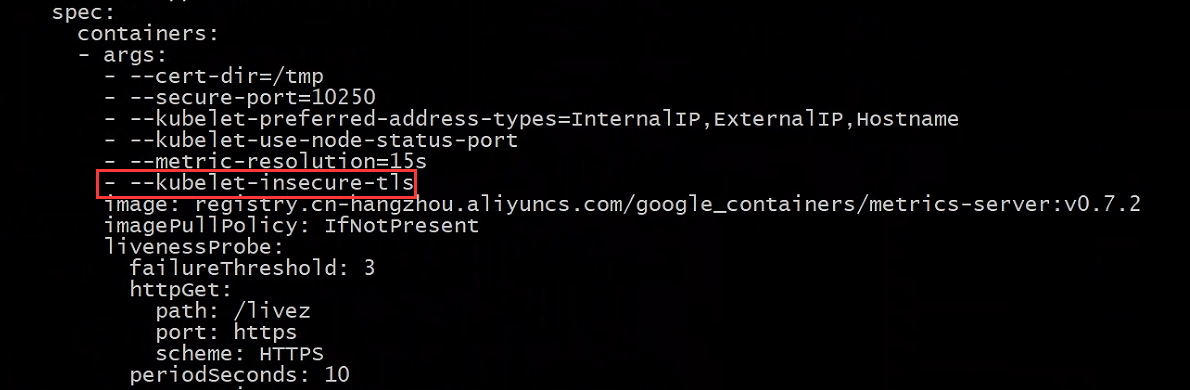
在如图所示添加 - --kubelet-insecure-tls
重新应用
kubectl apply -f metrics-server.yaml
4.查看
[root@master hpa]# kubectl top pod -A
NAMESPACE NAME CPU(cores) MEMORY(bytes)
cert-manager cert-manager-bcc6fc947-g4jvd 1m 22Mi
cert-manager cert-manager-cainjector-74b489f78f-pmh8m 1m 24Mi
cert-manager cert-manager-webhook-68dc7956b4-n2j4j 1m 17Mi
kube-system calico-kube-controllers-6b668cd977-lv54j 2m 22Mi
kube-system calico-node-gpdrp 21m 105Mi
kube-system calico-node-klbrm 17m 124Mi
kube-system calico-node-vtmch 34m 128Mi
kube-system coredns-c676cc86f-6rrp4 2m 18Mi
kube-system coredns-c676cc86f-pjl52 1m 16Mi
kube-system etcd-master 24m 122Mi
kube-system kube-apiserver-master 55m 463Mi
kube-system kube-controller-manager-master 19m 64Mi
kube-system kube-proxy-ptb4h 1m 22Mi
kube-system kube-proxy-v6b8x 1m 19Mi
kube-system kube-proxy-xjmxk 1m 17Mi
kube-system kube-scheduler-master 3m 22Mi
kube-system metrics-server-7667bfbfbb-vrn6z 5m 18Mi
middleware milvus-dev-milvus-datanode-555c8859fc-nqdjw 20m 100Mi
middleware milvus-dev-milvus-indexnode-68f89cbb65-bj6p8 4m 113Mi
middleware milvus-dev-milvus-mixcoord-5879ddb6bf-zq5qb 43m 204Mi
middleware milvus-dev-milvus-proxy-6d7656657f-pwm29 26m 132Mi
middleware milvus-dev-milvus-querynode-0-5cd5fb96b6-j5xzc 18m 150Mi
milvus-operator milvus-operator-75bccd859c-gxj2j 3m 30Mi
ns-hpa nginx-deployment-cb5988cbd-tchrh 0m 3Mi
ns-mysql hxl-mysql-deploy-5c579f8d6f-qp55t 1m 212Mi
velero velero-75cd89cf9b-fjvcw 3m 31Mi
[root@master hpa]# kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
master 332m 16% 2657Mi 46%
node1 112m 11% 1412Mi 24%
node2 189m 9% 3322Mi 57%

 浙公网安备 33010602011771号
浙公网安备 33010602011771号