


本章内容
-
认识模块
-
常用模块
-
模块与包
认识模块
什么是模块
什么是模块
常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀。
但其实import加载的模块分为四个通用类别:
1 使用python编写的代码(.py文件)
2 已被编译为共享库或DLL的C或C++扩展
3 包好一组模块的包
4 使用C编写并链接到python解释器的内置模块
为何要使用模块?
导入模块,实现功能的重复利用。
模块的导入与使用:模块的导入应该在程序开始的地方,更多相关内容 http://www.cnblogs.com/Eva-J/articles/7292109.html
常用模块
colletions模块
在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。
1.namedtuple: 生成可以使用名字来访问元素内容的tuple
2.deque: 双端队列,可以快速的从另外一侧追加和推出对象
3.Counter: 计数器,主要用来计数
4.OrderedDict: 有序字典
5.defaultdict: 带有默认值的字典
时间模块
和时间有关系的我们就要用到时间模块。在使用模块之前,应该首先导入这个模块。
#常用方法 1.time.sleep(secs) (线程)推迟指定的时间运行。单位为秒。 2.time.time() 获取当前时间戳
random模块
>>> import random #随机小数 >>> random.random() # 大于0且小于1之间的小数 0.7664338663654585 >>> random.uniform(1,3) #大于1小于3的小数 1.6270147180533838 #恒富:发红包 #随机整数 >>> random.randint(1,5) # 大于等于1且小于等于5之间的整数 >>> random.randrange(1,10,2) # 大于等于1且小于10之间的奇数 #随机选择一个返回 >>> random.choice([1,'23',[4,5]]) # #1或者23或者[4,5] #随机选择多个返回,返回的个数为函数的第二个参数 >>> random.sample([1,'23',[4,5]],2) # #列表元素任意2个组合 [[4, 5], '23'] #打乱列表顺序 >>> item=[1,3,5,7,9] >>> random.shuffle(item) # 打乱次序 >>> item [5, 1, 3, 7, 9] >>> random.shuffle(item) >>> item [5, 9, 7, 1, 3]
练习:生成随机验证码


import random def v_code(): code = '' for i in range(5): num=random.randint(0,9) alf=chr(random.randint(65,90)) add=random.choice([num,alf]) code="".join([code,str(add)]) return code print(v_code())
os模块
os模块是与操作系统交互的一个接口
''' os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd os.curdir 返回当前目录: ('.') os.pardir 获取当前目录的父目录字符串名:('..') os.makedirs('dirname1/dirname2') 可生成多层递归目录 os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove() 删除一个文件 os.rename("oldname","newname") 重命名文件/目录 os.stat('path/filename') 获取文件/目录信息 os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/" os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n" os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为: os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix' os.system("bash command") 运行shell命令,直接显示 os.popen("bash command).read() 运行shell命令,获取执行结果 os.environ 获取系统环境变量 os.path os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。 即os.path.split(path)的第二个元素 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) 如果path是绝对路径,返回True os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间 os.path.getsize(path) 返回path的大小 '''
注意:os.stat('path/filename') 获取文件/目录信息 的结构说明
stat 结构: st_mode: inode 保护模式 st_ino: inode 节点号。 st_dev: inode 驻留的设备。 st_nlink: inode 的链接数。 st_uid: 所有者的用户ID。 st_gid: 所有者的组ID。 st_size: 普通文件以字节为单位的大小;包含等待某些特殊文件的数据。 st_atime: 上次访问的时间。 st_mtime: 最后一次修改的时间。 st_ctime: 由操作系统报告的"ctime"。在某些系统上(如Unix)是最新的元数据更改的时间,在其它系统上(如Windows)是创建时间(详细信息参见平台的文档)。
sys模块
sys模块是与python解释器交互的一个接口
sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0),错误退出sys.exit(1) sys.version 获取Python解释程序的版本信息 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称
import sys try: sys.exit(1) except SystemExit as e: print(e)
序列化模块
什么叫序列化——将原本的字典、列表等内容转换成一个字符串的过程就叫做序列化。
比如,我们在python代码中计算的一个数据需要给另外一段程序使用,那我们怎么给? 现在我们能想到的方法就是存在文件里,然后另一个python程序再从文件里读出来。 但是我们都知道,对于文件来说是没有字典这个概念的,所以我们只能将数据转换成字典放到文件中。 你一定会问,将字典转换成一个字符串很简单,就是str(dic)就可以办到了,为什么我们还要学习序列化模块呢? 没错序列化的过程就是从dic 变成str(dic)的过程。现在你可以通过str(dic),将一个名为dic的字典转换成一个字符串, 但是你要怎么把一个字符串转换成字典呢? 聪明的你肯定想到了eval(),如果我们将一个字符串类型的字典str_dic传给eval,就会得到一个返回的字典类型了。 eval()函数十分强大,但是eval是做什么的?e官方demo解释为:将字符串str当成有效的表达式来求值并返回计算结果。 BUT!强大的函数有代价。安全性是其最大的缺点。 想象一下,如果我们从文件中读出的不是一个数据结构,而是一句"删除文件"类似的破坏性语句,那么后果实在不堪设设想。 而使用eval就要担这个风险。 所以,我们并不推荐用eval方法来进行反序列化操作(将str转换成python中的数据结构)
序列化的目的

re模块
首先来看一个手机号验证的例子,那么这个功能怎么实现啊?
假如现在你用python写一段代码,类似:
phone_number = input('please input your phone number : ')
你怎么判断这个phone_number是合法的呢?
根据手机号码一共11位并且是只以13、14、15、18开头的数字这些特点,我们用python写了如下代码:
while True: phone_number = input('please input your phone number : ') if len(phone_number) == 11 \ and phone_number.isdigit()\ and (phone_number.startswith('13') \ or phone_number.startswith('14') \ or phone_number.startswith('15') \ or phone_number.startswith('18')): print('是合法的手机号码') else: print('不是合法的手机号码')
这是大家在没学re模块的写法,现在介绍一种使用re模块和正则表达式的写法:
import re phone_number = input('please input your phone number : ') if re.match('^(13|14|15|18)[0-9]{9}$',phone_number): print('是合法的手机号码') else: print('不是合法的手机号码')
对比上面的两种写法,此时此刻,我要问你你喜欢哪种方法呀?你肯定还是会说第一种,为什么呢?因为第一种不用学呀!
但是如果现在有一个文件,我让你从整个文件里匹配出所有的手机号码。你用python给我写个试试?
但是学了今天的技能之后,分分钟帮你搞定!
今天我们要学习python里的re模块和正则表达式,学会了这个就可以帮我们解决刚刚的疑问。正则表达式不仅在python领域,在整个编程届都占有举足轻重的地位。
re模块下的常用方法

import re
ret = re.findall('a', 'eva egon yuan') # 返回所有满足匹配条件的结果,放在列表里
print(ret) #结果 : ['a', 'a']
ret = re.search('a', 'eva egon yuan').group()
print(ret) #结果 : 'a'
# 函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以
# 通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。
ret = re.match('a', 'abc').group() # 同search,不过尽在字符串开始处进行匹配
print(ret)
#结果 : 'a'
ret = re.split('[ab]', 'abcd') # 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割
print(ret) # ['', '', 'cd']
ret = re.sub('\d', 'H', 'eva3egon4yuan4', 1)#将数字替换成'H',参数1表示只替换1个
print(ret) #evaHegon4yuan4
ret = re.subn('\d', 'H', 'eva3egon4yuan4')#将数字替换成'H',返回元组(替换的结果,替换了多少次)
print(ret)
obj = re.compile('\d{3}') #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字
ret = obj.search('abc123eeee') #正则表达式对象调用search,参数为待匹配的字符串
print(ret.group()) #结果 : 123
import re
ret = re.finditer('\d', 'ds3sy4784a') #finditer返回一个存放匹配结果的迭代器
print(ret) # <callable_iterator object at 0x10195f940>
print(next(ret).group()) #查看第一个结果
print(next(ret).group()) #查看第二个结果
print([i.group() for i in ret]) #查看剩余的左右结果
注意:
1 findall的优先级查询:
import re
ret = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com')
print(ret) # ['oldboy'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可
ret = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com')
print(ret) # ['www.oldboy.com']
2 split的优先级查询
ret=re.split("\d+","eva3egon4yuan")
print(ret) #结果 : ['eva', 'egon', 'yuan']
ret=re.split("(\d+)","eva3egon4yuan")
print(ret) #结果 : ['eva', '3', 'egon', '4', 'yuan']
#在匹配部分加上()之后所切出的结果是不同的,
#没有()的没有保留所匹配的项,但是有()的却能够保留了匹配的项,
#这个在某些需要保留匹配部分的使用过程是非常重要的。
综合练习与拓展
import re ret = re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>") #还可以在分组中利用?<name>的形式给分组起名字 #获取的匹配结果可以直接group('名字')拿到对应的值 print(ret.group('tag_name')) #结果:h1 print(ret.group()) #结果:<h1>hello</h1> ret = re.search(r"<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>") #如果不给组起名字,也可以用\序号来找到对应的组,表示找的内容和前面的组内容一致 #获取的匹配结果可以直接用group(序号)拿到对应的值 print((ret.group(1))) #结果:h1 print((ret.group())) #结果:<h1>hello</h1>
import re ret = re.findall(r"\d+","1-2*(60+(-40.35/5)-(-4*3))") print(ret)#结果为:['1', '2', '60', '40', '35', '5', '4', '3'] ret = re.findall(r"-?\d+\.\d*|(-?\d+)","1-2*(60+(-40.35/5)-(-4*3))") print(ret)#结果为:['1', '-2', '60', '', '5', '-4', '3'] ret.remove("") print(ret)#结果为:['1', '-2', '60', '5', '-4', '3']
1、 匹配一段文本中的每行的邮箱 http://blog.csdn.net/make164492212/article/details/51656638 2、 匹配一段文本中的每行的时间字符串,比如:‘1990-07-12’; 分别取出1年的12个月(^(0?[1-9]|1[0-2])$)、 一个月的31天:^((0?[1-9])|((1|2)[0-9])|30|31)$ 3、 匹配qq号。(腾讯QQ号从10000开始) [1,9][0,9]{4,} 4、 匹配一个浮点数。 ^(-?\d+)(\.\d+)?$ 或者 -?\d+\.?\d* 5、 匹配汉字。 ^[\u4e00-\u9fa5]{0,}$ 6、 匹配出所有整数
import requests import re import json def getPages(url): response = requests.get(url) return response.text def parsePage(s): com = re.compile('<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>' '.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>',re.S) ret = com.finditer(s) for i in ret: yield{ "id":i.group("id"), "title":i.group("title"), "rating_num":i.group("rating_num"), "comment_num":i.group("comment_num"), } def main(num): url = 'https://movie.douban.com/top250?start=%s&filter='%num response_html=getPages(url) ret = parsePage(response_html) print(ret) f=open("move_info","a",encoding="utf-8") for obj in ret: print(obj) data = json.dumps(obj,ensure_ascii=False) f.write(data+"\n") if __name__=='__main__': count = 0 for i in range(10): main(count) count+=25
flags有很多可选值: re.I(IGNORECASE)忽略大小写,括号内是完整的写法 re.M(MULTILINE)多行模式,改变^和$的行为 re.S(DOTALL)点可以匹配任意字符,包括换行符 re.L(LOCALE)做本地化识别的匹配,表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境,不推荐使用 re.U(UNICODE) 使用\w \W \s \S \d \D使用取决于unicode定义的字符属性。在python3中默认使用该flag re.X(VERBOSE)冗长模式,该模式下pattern字符串可以是多行的,忽略空白字符,并可以添加注释
hashlib模块
算法介绍
Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等。
什么是摘要算法呢?摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示)。
摘要算法就是通过摘要函数f()对任意长度的数据data计算出固定长度的摘要digest,目的是为了发现原始数据是否被人篡改过。
摘要算法之所以能指出数据是否被篡改过,就是因为摘要函数是一个单向函数,计算f(data)很容易,但通过digest反推data却非常困难。而且,对原始数据做一个bit的修改,都会导致计算出的摘要完全不同。
我们以常见的摘要算法MD5为例,计算出一个字符串的MD5值:
import hashlib
md5 = hashlib.md5()
md5.update('how to use md5 in python hashlib?')
print md5.hexdigest()
计算结果如下:
d26a53750bc40b38b65a520292f69306
如果数据量很大,可以分块多次调用update(),最后计算的结果是一样的:
md5 = hashlib.md5()
md5.update('how to use md5 in ')
md5.update('python hashlib?')
print md5.hexdigest()
MD5是最常见的摘要算法,速度很快,生成结果是固定的128 bit字节,通常用一个32位的16进制字符串表示。另一种常见的摘要算法是SHA1,调用SHA1和调用MD5完全类似:
import hashlib
sha1 = hashlib.sha1()
sha1.update('how to use sha1 in ')
sha1.update('python hashlib?')
print sha1.hexdigest()
SHA1的结果是160 bit字节,通常用一个40位的16进制字符串表示。比SHA1更安全的算法是SHA256和SHA512,不过越安全的算法越慢,而且摘要长度更长。
摘要算法应用
任何允许用户登录的网站都会存储用户登录的用户名和口令。如何存储用户名和口令呢?方法是存到数据库表中:
name | password --------+---------- michael | 123456 bob | abc999 alice | alice2008
如果以明文保存用户口令,如果数据库泄露,所有用户的口令就落入黑客的手里。此外,网站运维人员是可以访问数据库的,也就是能获取到所有用户的口令。正确的保存口令的方式是不存储用户的明文口令,而是存储用户口令的摘要,比如MD5:
username | password ---------+--------------------------------- michael | e10adc3949ba59abbe56e057f20f883e bob | 878ef96e86145580c38c87f0410ad153 alice | 99b1c2188db85afee403b1536010c2c9
考虑这么个情况,很多用户喜欢用123456,888888,password这些简单的口令,于是,黑客可以事先计算出这些常用口令的MD5值,得到一个反推表:
'e10adc3949ba59abbe56e057f20f883e': '123456' '21218cca77804d2ba1922c33e0151105': '888888' '5f4dcc3b5aa765d61d8327deb882cf99': 'password'
这样,无需破解,只需要对比数据库的MD5,黑客就获得了使用常用口令的用户账号。
对于用户来讲,当然不要使用过于简单的口令。但是,我们能否在程序设计上对简单口令加强保护呢?
由于常用口令的MD5值很容易被计算出来,所以,要确保存储的用户口令不是那些已经被计算出来的常用口令的MD5,这一方法通过对原始口令加一个复杂字符串来实现,俗称“加盐”:
hashlib.md5("salt".encode("utf8"))
经过Salt处理的MD5口令,只要Salt不被黑客知道,即使用户输入简单口令,也很难通过MD5反推明文口令。
但是如果有两个用户都使用了相同的简单口令比如123456,在数据库中,将存储两条相同的MD5值,这说明这两个用户的口令是一样的。有没有办法让使用相同口令的用户存储不同的MD5呢?
如果假定用户无法修改登录名,就可以通过把登录名作为Salt的一部分来计算MD5,从而实现相同口令的用户也存储不同的MD5。
摘要算法在很多地方都有广泛的应用。要注意摘要算法不是加密算法,不能用于加密(因为无法通过摘要反推明文),只能用于防篡改,但是它的单向计算特性决定了可以在不存储明文口令的情况下验证用户口令。
configparser模块
该模块适用于配置文件的格式与windows ini文件类似,可以包含一个或多个节(section),每个节可以有多个参数(键=值)。
创建文件
来看一个好多软件的常见文档格式如下:
[DEFAULT] ServerAliveInterval = 45 Compression = yes CompressionLevel = 9 ForwardX11 = yes [bitbucket.org] User = hg [topsecret.server.com] Port = 50022 ForwardX11 = no
如果想用python生成一个这样的文档怎么做呢?
import configparser
config = configparser.ConfigParser()
config["DEFAULT"] = {'ServerAliveInterval': '45',
'Compression': 'yes',
'CompressionLevel': '9',
'ForwardX11':'yes'
}
config['bitbucket.org'] = {'User':'hg'}
config['topsecret.server.com'] = {'Host Port':'50022','ForwardX11':'no'}
with open('example.ini', 'w') as configfile:
config.write(configfile)
查找文件
import configparser
config = configparser.ConfigParser()
#---------------------------查找文件内容,基于字典的形式
print(config.sections()) # []
config.read('example.ini')
print(config.sections()) # ['bitbucket.org', 'topsecret.server.com']
print('bytebong.com' in config) # False
print('bitbucket.org' in config) # True
print(config['bitbucket.org']["user"]) # hg
print(config['DEFAULT']['Compression']) #yes
print(config['topsecret.server.com']['ForwardX11']) #no
print(config['bitbucket.org']) #<Section: bitbucket.org>
for key in config['bitbucket.org']: # 注意,有default会默认default的键
print(key)
print(config.options('bitbucket.org')) # 同for循环,找到'bitbucket.org'下所有键
print(config.items('bitbucket.org')) #找到'bitbucket.org'下所有键值对
print(config.get('bitbucket.org','compression')) # yes get方法Section下的key对应的value
增删改操作
import configparser
config = configparser.ConfigParser()
config.read('example.ini')
config.add_section('yuan')
config.remove_section('bitbucket.org')
config.remove_option('topsecret.server.com',"forwardx11")
config.set('topsecret.server.com','k1','11111')
config.set('yuan','k2','22222')
config.write(open('new2.ini', "w"))
logging模块
函数式简单配置
import logging
logging.debug('debug message')
logging.info('info message')
logging.warning('warning message')
logging.error('error message')
logging.critical('critical message')
默认情况下Python的logging模块将日志打印到了标准输出中,且只显示了大于等于WARNING级别的日志,这说明默认的日志级别设置为WARNING(日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG),默认的日志格式为日志级别:Logger名称:用户输出消息。
灵活配置日志级别,日志格式,输出位置:
import logging
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
datefmt='%a, %d %b %Y %H:%M:%S',
filename='/tmp/test.log',
filemode='w')
logging.debug('debug message')
logging.info('info message')
logging.warning('warning message')
logging.error('error message')
logging.critical('critical message')
配置参数:
logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有: filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。 filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。 format:指定handler使用的日志显示格式。 datefmt:指定日期时间格式。 level:设置rootlogger(后边会讲解具体概念)的日志级别 stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open(‘test.log’,’w’)),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。 format参数中可能用到的格式化串: %(name)s Logger的名字 %(levelno)s 数字形式的日志级别 %(levelname)s 文本形式的日志级别 %(pathname)s 调用日志输出函数的模块的完整路径名,可能没有 %(filename)s 调用日志输出函数的模块的文件名 %(module)s 调用日志输出函数的模块名 %(funcName)s 调用日志输出函数的函数名 %(lineno)d 调用日志输出函数的语句所在的代码行 %(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示 %(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数 %(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 %(thread)d 线程ID。可能没有 %(threadName)s 线程名。可能没有 %(process)d 进程ID。可能没有 %(message)s用户输出的消息
logger对象配置
import logging
logger = logging.getLogger()
# 创建一个handler,用于写入日志文件
fh = logging.FileHandler('test.log',encoding='utf-8')
# 再创建一个handler,用于输出到控制台
ch = logging.StreamHandler()
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
fh.setLevel(logging.DEBUG)
fh.setFormatter(formatter)
ch.setFormatter(formatter)
logger.addHandler(fh) #logger对象可以添加多个fh和ch对象
logger.addHandler(ch)
logger.debug('logger debug message')
logger.info('logger info message')
logger.warning('logger warning message')
logger.error('logger error message')
logger.critical('logger critical message')
logging库提供了多个组件:Logger、Handler、Filter、Formatter。Logger对象提供应用程序可直接使用的接口,Handler发送日志到适当的目的地,Filter提供了过滤日志信息的方法,Formatter指定日志显示格式。另外,可以通过:logger.setLevel(logging.Debug)设置级别,当然,也可以通过
fh.setLevel(logging.Debug)单对文件流设置某个级别。
如何使用模块?
import
示例文件:自定义模块my_module.py,文件名my_module.py,模块名my_module
#my_module.py print('from the my_module.py') money=1000 def read1(): print('my_module->read1->money',money) def read2(): print('my_module->read2 calling read1') read1() def change(): global money money=0
模块可以包含可执行的语句和函数的定义,这些语句的目的是初始化模块,它们只在模块名第一次遇到导入import语句时才执行(import语句是可以在程序中的任意位置使用的,且针对同一个模块很import多次,为了防止你重复导入,python的优化手段是:第一次导入后就将模块名加载到内存了,后续的import语句仅是对已经加载大内存中的模块对象增加了一次引用,不会重新执行模块内的语句),如下
#demo.py import my_module #只在第一次导入时才执行my_module.py内代码,此处的显式效果是只打印一次'from the my_module.py',当然其他的顶级代码也都被执行了,只不过没有显示效果. import my_module import my_module import my_module ''' 执行结果: from the my_module.py '''
我们可以从sys.modules中找到当前已经加载的模块,sys.modules是一个字典,内部包含模块名与模块对象的映射,该字典决定了导入模块时是否需要重新导入。
每个模块都是一个独立的名称空间,定义在这个模块中的函数,把这个模块的名称空间当做全局名称空间,这样我们在编写自己的模块时,就不用担心我们定义在自己模块中全局变量会在被导入时,与使用者的全局变量冲突
总结:首次导入模块my_module时会做三件事:
1.为源文件(my_module模块)创建新的名称空间,在my_module中定义的函数和方法若是使用到了global时访问的就是这个名称空间。
2.在新创建的命名空间中执行模块中包含的代码,见初始导入import my_module
1 提示:导入模块时到底执行了什么? 2 3 In fact function definitions are also ‘statements’ that are ‘executed’; the execution of a module-level function definition enters the function name in the module’s global symbol table. 4 事实上函数定义也是“被执行”的语句,模块级别函数定义的执行将函数名放入模块全局名称空间表,用globals()可以查看
3.创建名字my_module来引用该命名空间
1 这个名字和变量名没什么区别,都是‘第一类的’,且使用my_module.名字的方式可以访问my_module.py文件中定义的名字,my_module.名字与test.py中的名字来自两个完全不同的地方。
为模块名起别名,相当于m1=1;m2=m1
1 import my_module as sm 2 print(sm.money)
示范用法一:
有两中sql模块mysql和oracle,根据用户的输入,选择不同的sql功能
#mysql.py def sqlparse(): print('from mysql sqlparse') #oracle.py def sqlparse(): print('from oracle sqlparse') #test.py db_type=input('>>: ') if db_type == 'mysql': import mysql as db elif db_type == 'oracle': import oracle as db db.sqlparse() 复制代码
示范用法二:
为已经导入的模块起别名的方式对编写可扩展的代码很有用,假设有两个模块xmlreader.py和csvreader.py,它们都定义了函数read_data(filename):用来从文件中读取一些数据,但采用不同的输入格式。可以编写代码来选择性地挑选读取模块,例如
if file_format == 'xml': import xmlreader as reader elif file_format == 'csv': import csvreader as reader data=reader.read_date(filename)
在一行导入多个模块
1 import sys,os,re
from ... import...
对比import my_module,会将源文件的名称空间'my_module'带到当前名称空间中,使用时必须是my_module.名字的方式
而from 语句相当于import,也会创建新的名称空间,但是将my_module中的名字直接导入到当前的名称空间中,在当前名称空间中,直接使用名字就可以了、
1 from my_module import read1,read2
这样在当前位置直接使用read1和read2就好了,执行时,仍然以my_module.py文件全局名称空间
#测试一:导入的函数read1,执行时仍然回到my_module.py中寻找全局变量money #demo.py from my_module import read1 money=1000 read1() ''' 执行结果: from the my_module.py spam->read1->money 1000 ''' #测试二:导入的函数read2,执行时需要调用read1(),仍然回到my_module.py中找read1() #demo.py from my_module import read2 def read1(): print('==========') read2() ''' 执行结果: from the my_module.py my_module->read2 calling read1 my_module->read1->money 1000 '''
如果当前有重名read1或者read2,那么会有覆盖效果。
#测试三:导入的函数read1,被当前位置定义的read1覆盖掉了 #demo.py from my_module import read1 def read1(): print('==========') read1() ''' 执行结果: from the my_module.py ========== '''
需要特别强调的一点是:python中的变量赋值不是一种存储操作,而只是一种绑定关系,如下:
from my_module import money,read1 money=100 #将当前位置的名字money绑定到了100 print(money) #打印当前的名字 read1() #读取my_module.py中的名字money,仍然为1000 ''' from the my_module.py my_module->read1->money 1000 '''
也支持as
1 from my_module import read1 as read
也支持导入多行
1 from my_module import (read1, 2 read2, 3 money)
把模块当做脚本执行
我们可以通过模块的全局变量__name__来查看模块名:
当做脚本运行:
__name__ 等于'__main__'
当做模块导入:
__name__= 模块名
作用:用来控制.py文件在不同的应用场景下执行不同的逻辑
if __name__ == '__main__':
def fib(n): a, b = 0, 1 while b < n: print(b, end=' ') a, b = b, a+b print() if __name__ == "__main__": print(__name__) num = input('num :') fib(int(num))
模块搜索路径
python解释器在启动时会自动加载一些模块,可以使用sys.modules查看
在第一次导入某个模块时(比如my_module),会先检查该模块是否已经被加载到内存中(当前执行文件的名称空间对应的内存),如果有则直接引用
如果没有,解释器则会查找同名的内建模块,如果还没有找到就从sys.path给出的目录列表中依次寻找my_module.py文件。
所以总结模块的查找顺序是:内存中已经加载的模块->内置模块->sys.path路径中包含的模块
sys.path的初始化的值来自于:
The directory containing the input script (or the current directory when no file is specified).
PYTHONPATH (a list of directory names, with the same syntax as the shell variable PATH).
The installation-dependent default.
需要特别注意的是:我们自定义的模块名不应该与系统内置模块重名。虽然每次都说,但是仍然会有人不停的犯错。
在初始化后,python程序可以修改sys.path,路径放到前面的优先于标准库被加载。
1 >>> import sys
2 >>> sys.path.append('/a/b/c/d')
3 >>> sys.path.insert(0,'/x/y/z') #排在前的目录,优先被搜索
注意:搜索时按照sys.path中从左到右的顺序查找,位于前的优先被查找,sys.path中还可能包含.zip归档文件和.egg文件,python会把.zip归档文件当成一个目录去处理。
#首先制作归档文件:zip module.zip foo.py bar.py import sys sys.path.append('module.zip') import foo,bar #也可以使用zip中目录结构的具体位置 sys.path.append('module.zip/lib/python') #windows下的路径不加r开头,会语法错误 sys.path.insert(0,r'C:\Users\Administrator\PycharmProjects\a')
官网解释
#官网链接:https://docs.python.org/3/tutorial/modules.html#the-module-search-path 搜索路径: 当一个命名为my_module的模块被导入时 解释器首先会从内建模块中寻找该名字 找不到,则去sys.path中找该名字 sys.path从以下位置初始化 执行文件所在的当前目录 PTYHONPATH(包含一系列目录名,与shell变量PATH语法一样) 依赖安装时默认指定的 注意:在支持软连接的文件系统中,执行脚本所在的目录是在软连接之后被计算的,换句话说,包含软连接的目录不会被添加到模块的搜索路径中 在初始化后,我们也可以在python程序中修改sys.path,执行文件所在的路径默认是sys.path的第一个目录,在所有标准库路径的前面。这意味着,当前目录是优先于标准库目录的,需要强调的是:我们自定义的模块名不要跟python标准库的模块名重复,除非你是故意的,傻叉。
编译python文件
为了提高加载模块的速度,强调强调强调:提高的是加载速度而绝非运行速度。python解释器会在__pycache__目录中下缓存每个模块编译后的版本,格式为:module.version.pyc。通常会包含python的版本号。例如,在CPython3.3版本下,my_module.py模块会被缓存成__pycache__/my_module.cpython-33.pyc。这种命名规范保证了编译后的结果多版本共存。
Python检查源文件的修改时间与编译的版本进行对比,如果过期就需要重新编译。这是完全自动的过程。并且编译的模块是平台独立的,所以相同的库可以在不同的架构的系统之间共享,即pyc使一种跨平台的字节码,类似于JAVA火.NET,是由python虚拟机来执行的,但是pyc的内容跟python的版本相关,不同的版本编译后的pyc文件不同,2.5编译的pyc文件不能到3.5上执行,并且pyc文件是可以反编译的,因而它的出现仅仅是用来提升模块的加载速度的。
python解释器在以下两种情况下不检测缓存
1 如果是在命令行中被直接导入模块,则按照这种方式,每次导入都会重新编译,并且不会存储编译后的结果(python3.3以前的版本应该是这样)
python -m my_module.py
2 如果源文件不存在,那么缓存的结果也不会被使用,如果想在没有源文件的情况下来使用编译后的结果,则编译后的结果必须在源目录下
提示:
1.模块名区分大小写,foo.py与FOO.py代表的是两个模块
2.你可以使用-O或者-OO转换python命令来减少编译模块的大小
-O转换会帮你去掉assert语句 -OO转换会帮你去掉assert语句和__doc__文档字符串 由于一些程序可能依赖于assert语句或文档字符串,你应该在在确认需要的情况下使用这些选项。
3.在速度上从.pyc文件中读指令来执行不会比从.py文件中读指令执行更快,只有在模块被加载时,.pyc文件才是更快的
4.只有使用import语句是才将文件自动编译为.pyc文件,在命令行或标准输入中指定运行脚本则不会生成这类文件,因而我们可以使用compieall模块为一个目录中的所有模块创建.pyc文件
模块可以作为一个脚本(使用python -m compileall)编译Python源 python -m compileall /module_directory 递归着编译 如果使用python -O -m compileall /module_directory -l则只一层 命令行里使用compile()函数时,自动使用python -O -m compileall 详见:https://docs.python.org/3/library/compileall.html#module-compileall
补充:dir()函数
内建函数dir是用来查找模块中定义的名字,返回一个有序字符串列表
import my_module dir(my_module)
如果没有参数,dir()列举出当前定义的名字
dir()不会列举出内建函数或者变量的名字,它们都被定义到了标准模块builtin中,可以列举出它们,
import builtins dir(builtins)
二 包
包是一种通过使用‘.模块名’来组织python模块名称空间的方式。
1. 无论是import形式还是from...import形式,凡是在导入语句中(而不是在使用时)遇到带点的,都要第一时间提高警觉:这是关于包才有的导入语法
2. 包是目录级的(文件夹级),文件夹是用来组成py文件(包的本质就是一个包含__init__.py文件的目录)
3. import导入文件时,产生名称空间中的名字来源于文件,import 包,产生的名称空间的名字同样来源于文件,即包下的__init__.py,导入包本质就是在导入该文件
强调:
1. 在python3中,即使包下没有__init__.py文件,import 包仍然不会报错,而在python2中,包下一定要有该文件,否则import 包报错
2. 创建包的目的不是为了运行,而是被导入使用,记住,包只是模块的一种形式而已,包即模块
包A和包B下有同名模块也不会冲突,如A.a与B.a来自俩个命名空间
import os os.makedirs('glance/api') os.makedirs('glance/cmd') os.makedirs('glance/db') l = [] l.append(open('glance/__init__.py','w')) l.append(open('glance/api/__init__.py','w')) l.append(open('glance/api/policy.py','w')) l.append(open('glance/api/versions.py','w')) l.append(open('glance/cmd/__init__.py','w')) l.append(open('glance/cmd/manage.py','w')) l.append(open('glance/db/models.py','w')) map(lambda f:f.close() ,l)
glance/ #Top-level package ├── __init__.py #Initialize the glance package ├── api #Subpackage for api │ ├── __init__.py │ ├── policy.py │ └── versions.py ├── cmd #Subpackage for cmd │ ├── __init__.py │ └── manage.py └── db #Subpackage for db ├── __init__.py └── models.py
#文件内容 #policy.py def get(): print('from policy.py') #versions.py def create_resource(conf): print('from version.py: ',conf) #manage.py def main(): print('from manage.py') #models.py def register_models(engine): print('from models.py: ',engine)
注意事项
1.关于包相关的导入语句也分为import和from ... import ...两种,但是无论哪种,无论在什么位置,在导入时都必须遵循一个原则:凡是在导入时带点的,点的左边都必须是一个包,否则非法。可以带有一连串的点,如item.subitem.subsubitem,但都必须遵循这个原则。
2.对于导入后,在使用时就没有这种限制了,点的左边可以是包,模块,函数,类(它们都可以用点的方式调用自己的属性)。
3.对比import item 和from item import name的应用场景:
如果我们想直接使用name那必须使用后者。
import
我们在与包glance同级别的文件中测试
1 import glance.db.models 2 glance.db.models.register_models('mysql')
from ... import ...
需要注意的是from后import导入的模块,必须是明确的一个不能带点,否则会有语法错误,如:from a import b.c是错误语法
我们在与包glance同级别的文件中测试
1 from glance.db import models
2 models.register_models('mysql')
3
4 from glance.db.models import register_models
5 register_models('mysql')
__init__.py文件
不管是哪种方式,只要是第一次导入包或者是包的任何其他部分,都会依次执行包下的__init__.py文件(我们可以在每个包的文件内都打印一行内容来验证一下),这个文件可以为空,但是也可以存放一些初始化包的代码。
from glance.api import *
在讲模块时,我们已经讨论过了从一个模块内导入所有*,此处我们研究从一个包导入所有*。
此处是想从包api中导入所有,实际上该语句只会导入包api下__init__.py文件中定义的名字,我们可以在这个文件中定义__all___:
#在__init__.py中定义
x=10
def func():
print('from api.__init.py')
__all__=['x','func','policy']
此时我们在于glance同级的文件中执行from glance.api import *就导入__all__中的内容(versions仍然不能导入)。
glance/ ├── __init__.py ├── api │ ├── __init__.py __all__ = ['policy','versions'] │ ├── policy.py │ └── versions.py ├── cmd __all__ = ['manage'] │ ├── __init__.py │ └── manage.py └── db __all__ = ['models'] ├── __init__.py └── models.py from glance.api import * policy.get()
绝对导入和相对导入
我们的最顶级包glance是写给别人用的,然后在glance包内部也会有彼此之间互相导入的需求,这时候就有绝对导入和相对导入两种方式:
绝对导入:以glance作为起始
相对导入:用.或者..的方式最为起始(只能在一个包中使用,不能用于不同目录内)
例如:我们在glance/api/version.py中想要导入glance/cmd/manage.py
在glance/api/version.py #绝对导入 from glance.cmd import manage manage.main() #相对导入 from ..cmd import manage manage.main()
测试结果:注意一定要在于glance同级的文件中测试
1 from glance.api import versions
注意:在使用pycharm时,有的情况会为你多做一些事情,这是软件相关的东西,会影响你对模块导入的理解,因而在测试时,一定要回到命令行去执行,模拟我们生产环境,你总不能拿着pycharm去上线代码吧!!!
特别需要注意的是:可以用import导入内置或者第三方模块(已经在sys.path中),但是要绝对避免使用import来导入自定义包的子模块(没有在sys.path中),应该使用from... import ...的绝对或者相对导入,且包的相对导入只能用from的形式。
比如我们想在glance/api/versions.py中导入glance/api/policy.py,有的同学一抽这俩模块是在同一个目录下,十分开心的就去做了,它直接这么做
1 #在version.py中 2 3 import policy 4 policy.get()
没错,我们单独运行version.py是一点问题没有的,运行version.py的路径搜索就是从当前路径开始的,于是在导入policy时能在当前目录下找到
但是你想啊,你子包中的模块version.py极有可能是被一个glance包同一级别的其他文件导入,比如我们在于glance同级下的一个test.py文件中导入version.py,如下
from glance.api import versions ''' 执行结果: ImportError: No module named 'policy' ''' ''' 分析: 此时我们导入versions在versions.py中执行 import policy需要找从sys.path也就是从当前目录找policy.py, 这必然是找不到的 '''
glance/ ├── __init__.py from glance import api from glance import cmd from glance import db ├── api │ ├── __init__.py from glance.api import policy from glance.api import versions │ ├── policy.py │ └── versions.py ├── cmd from glance.cmd import manage │ ├── __init__.py │ └── manage.py └── db from glance.db import models ├── __init__.py └── models.py
glance/ ├── __init__.py from . import api #.表示当前目录 from . import cmd from . import db ├── api │ ├── __init__.py from . import policy from . import versions │ ├── policy.py │ └── versions.py ├── cmd from . import manage │ ├── __init__.py │ └── manage.py from ..api import policy #..表示上一级目录,想再manage中使用policy中的方法就需要回到上一级glance目录往下找api包,从api导入policy └── db from . import models ├── __init__.py └── models.py
单独导入包
单独导入包名称时不会导入包中所有包含的所有子模块,如
#在与glance同级的test.py中 import glance glance.cmd.manage.main() ''' 执行结果: AttributeError: module 'glance' has no attribute 'cmd' '''
解决方法:
1 #glance/__init__.py 2 from . import cmd 3 4 #glance/cmd/__init__.py 5 from . import manage
执行:
1 #在于glance同级的test.py中 2 import glance 3 glance.cmd.manage.main()
千万别问:__all__不能解决吗,__all__是用于控制from...import
import glance之后直接调用模块中的方法
glance/ ├── __init__.py from .api import * from .cmd import * from .db import * ├── api │ ├── __init__.py __all__ = ['policy','versions'] │ ├── policy.py │ └── versions.py ├── cmd __all__ = ['manage'] │ ├── __init__.py │ └── manage.py └── db __all__ = ['models'] ├── __init__.py └── models.py import glance policy.get()
软件开发规范
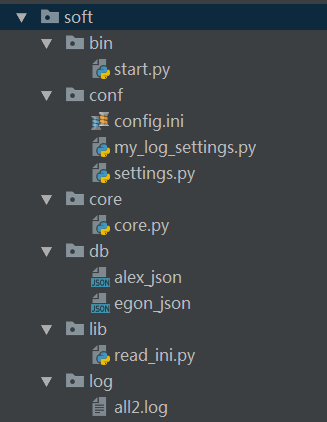
#=============>bin目录:存放执行脚本 #start.py import sys,os BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__))) sys.path.append(BASE_DIR) from core import core from conf import my_log_settings if __name__ == '__main__': my_log_settings.load_my_logging_cfg() core.run() #=============>conf目录:存放配置文件 #config.ini [DEFAULT] user_timeout = 1000 [egon] password = 123 money = 10000000 [alex] password = alex3714 money=10000000000 [yuanhao] password = ysb123 money=10 #settings.py import os config_path=r'%s\%s' %(os.path.dirname(os.path.abspath(__file__)),'config.ini') user_timeout=10 user_db_path=r'%s\%s' %(os.path.dirname(os.path.dirname(os.path.abspath(__file__))),\ 'db') #my_log_settings.py """ logging配置 """ import os import logging.config # 定义三种日志输出格式 开始 standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \ '[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字 simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s' id_simple_format = '[%(levelname)s][%(asctime)s] %(message)s' # 定义日志输出格式 结束 logfile_dir = r'%s\log' %os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # log文件的目录 logfile_name = 'all2.log' # log文件名 # 如果不存在定义的日志目录就创建一个 if not os.path.isdir(logfile_dir): os.mkdir(logfile_dir) # log文件的全路径 logfile_path = os.path.join(logfile_dir, logfile_name) # log配置字典 LOGGING_DIC = { 'version': 1, 'disable_existing_loggers': False, 'formatters': { 'standard': { 'format': standard_format }, 'simple': { 'format': simple_format }, }, 'filters': {}, 'handlers': { #打印到终端的日志 'console': { 'level': 'DEBUG', 'class': 'logging.StreamHandler', # 打印到屏幕 'formatter': 'simple' }, #打印到文件的日志,收集info及以上的日志 'default': { 'level': 'DEBUG', 'class': 'logging.handlers.RotatingFileHandler', # 保存到文件 'formatter': 'standard', 'filename': logfile_path, # 日志文件 'maxBytes': 1024*1024*5, # 日志大小 5M 'backupCount': 5, 'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了 }, }, 'loggers': { #logging.getLogger(__name__)拿到的logger配置 '': { 'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕 'level': 'DEBUG', 'propagate': True, # 向上(更高level的logger)传递 }, }, } def load_my_logging_cfg(): logging.config.dictConfig(LOGGING_DIC) # 导入上面定义的logging配置 logger = logging.getLogger(__name__) # 生成一个log实例 logger.info('It works!') # 记录该文件的运行状态 if __name__ == '__main__': load_my_logging_cfg() #=============>core目录:存放核心逻辑 #core.py import logging import time from conf import settings from lib import read_ini config=read_ini.read(settings.config_path) logger=logging.getLogger(__name__) current_user={'user':None,'login_time':None,'timeout':int(settings.user_timeout)} def auth(func): def wrapper(*args,**kwargs): if current_user['user']: interval=time.time()-current_user['login_time'] if interval < current_user['timeout']: return func(*args,**kwargs) name = input('name>>: ') password = input('password>>: ') if config.has_section(name): if password == config.get(name,'password'): logger.info('登录成功') current_user['user']=name current_user['login_time']=time.time() return func(*args,**kwargs) else: logger.error('用户名不存在') return wrapper @auth def buy(): print('buy...') @auth def run(): print(''' 购物 查看余额 转账 ''') while True: choice = input('>>: ').strip() if not choice:continue if choice == '1': buy() if __name__ == '__main__': run() #=============>db目录:存放数据库文件 #alex_json #egon_json #=============>lib目录:存放自定义的模块与包 #read_ini.py import configparser def read(config_file): config=configparser.ConfigParser() config.read(config_file) return config #=============>log目录:存放日志 #all2.log [2017-07-29 00:31:40,272][MainThread:11692][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!] [2017-07-29 00:31:41,789][MainThread:11692][task_id:core.core][core.py:25][ERROR][用户名不存在] [2017-07-29 00:31:46,394][MainThread:12348][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!] [2017-07-29 00:31:47,629][MainThread:12348][task_id:core.core][core.py:25][ERROR][用户名不存在] [2017-07-29 00:31:57,912][MainThread:10528][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!] [2017-07-29 00:32:03,340][MainThread:12744][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!] [2017-07-29 00:32:05,065][MainThread:12916][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!] [2017-07-29 00:32:08,181][MainThread:12916][task_id:core.core][core.py:25][ERROR][用户名不存在] [2017-07-29 00:32:13,638][MainThread:7220][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!] [2017-07-29 00:32:23,005][MainThread:7220][task_id:core.core][core.py:20][INFO][登录成功] [2017-07-29 00:32:40,941][MainThread:7220][task_id:core.core][core.py:20][INFO][登录成功] [2017-07-29 00:32:47,222][MainThread:7220][task_id:core.core][core.py:20][INFO][登录成功] [2017-07-29 00:32:51,949][MainThread:7220][task_id:core.core][core.py:25][ERROR][用户名不存在] [2017-07-29 00:33:00,213][MainThread:7220][task_id:core.core][core.py:20][INFO][登录成功] [2017-07-29 00:33:50,118][MainThread:8500][task_id:conf.my_log_settings][my_log_settings.py:75][INFO][It works!] [2017-07-29 00:33:55,845][MainThread:8500][task_id:core.core][core.py:20][INFO][登录成功] [2017-07-29 00:34:06,837][MainThread:8500][task_id:core.core][core.py:25][ERROR][用户名不存在] [2017-07-29 00:34:09,405][MainThread:8500][task_id:core.core][core.py:25][ERROR][用户名不存在] [2017-07-29 00:34:10,645][MainThread:8500][task_id:core.core][core.py:25][ERROR][用户名不存在]
参考学习:http://www.cnblogs.com/Eva-J/articles/7228075.html
http://www.cnblogs.com/Eva-J/articles/7292109.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号