



1、实验目的
熟悉Python 的基本操作,掌握对数据集的读写实现、对模型性能的评估实现的能力;
加深对训练集、测试集、N折交叉验证、模型评估标准的理解。
2、实验内容
(1)利用pandas库从本地读取iris数据集;
(2)从scikit-learn 库中直接加载iris 数据集;
(3)实现五折交叉验证进行模型训练;
(4)计算并输出模型的准确度、精度、召回率和F1值。
3、操作要点
(1)安装Python及pycharm(一种Python开发IDE),并熟悉Python基本操作;
(2)学习pandas库里存取文件的相关函数,以及scikit-learn库里数据集下载、交叉验
证、模型评估等相关操作;
(3)可能用的库有pandas,scikit-learn,numpy 等,需要提前下载pip;
(4)测试模型可使用随机森林rf_classifier=RandomForestClassifier(n_estimators=100),
或其它分类器
实验代码:
"""
Iris数据集分类任务
实现五折交叉验证并计算模型评估指标
"""
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import KFold, cross_val_predict
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
import warnings
import sys
import io
# 设置输出编码为UTF-8,解决Windows PowerShell中文乱码问题
if sys.platform == 'win32':
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
sys.stderr = io.TextIOWrapper(sys.stderr.buffer, encoding='utf-8')
warnings.filterwarnings('ignore')
# # ==================== 步骤1:使用pandas从本地读取iris数据集 ====================
# print("=" * 70)
# print("步骤1:使用pandas从本地读取iris数据集")
# print("=" * 70)
#
# # 读取本地iris数据文件
# iris_local_path = 'iris/iris.data'
# iris_local = pd.read_csv(iris_local_path, header=None,
# names=['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species'])
#
# print(f"本地数据集形状: {iris_local.shape}")
# print(f"前5行数据:")
# print(iris_local.head())
# print(f"\n类别分布:")
# print(iris_local['species'].value_counts())
# print()
#
# # 分离特征和标签
# X_local = iris_local.iloc[:, :-1].values
# y_local = iris_local.iloc[:, -1].values
# ==================== 步骤2:从scikit-learn库中直接加载iris数据集 ====================
print("=" * 70)
print("步骤2:从scikit-learn库中直接加载iris数据集")
print("=" * 70)
# 从sklearn加载iris数据集
iris_sklearn = load_iris()
X_sklearn = iris_sklearn.data
y_sklearn = iris_sklearn.target
feature_names = iris_sklearn.feature_names
target_names = iris_sklearn.target_names
print(f"Sklearn数据集形状: {X_sklearn.shape}")
print(f"特征名称: {feature_names}")
print(f"类别名称: {target_names}")
print(f"类别分布: {np.bincount(y_sklearn)}")
print()
# 将sklearn数据转换为DataFrame以便查看
iris_sklearn_df = pd.DataFrame(X_sklearn, columns=feature_names)
iris_sklearn_df['species'] = [target_names[i] for i in y_sklearn]
print("前5行数据:")
print(iris_sklearn_df.head())
print()
# ==================== 步骤3:实现五折交叉验证进行模型训练 ====================
print("=" * 70)
print("步骤3:实现五折交叉验证进行模型训练")
print("=" * 70)
# 选择使用sklearn加载的数据集(更标准)
X = X_sklearn
y = y_sklearn
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 创建模型(使用逻辑回归作为示例)
model = LogisticRegression(random_state=42, max_iter=1000)
# 创建五折交叉验证
kfold = KFold(n_splits=5, shuffle=True, random_state=42)
# 存储每折的预测结果
all_y_true = []
all_y_pred = []
print("开始五折交叉验证...")
fold_num = 1
for train_idx, test_idx in kfold.split(X_scaled):
print(f"\n第 {fold_num} 折:")
print(f" 训练集大小: {len(train_idx)}, 测试集大小: {len(test_idx)}")
# 划分训练集和测试集
X_train, X_test = X_scaled[train_idx], X_scaled[test_idx]
y_train, y_test = y[train_idx], y[test_idx]
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 保存预测结果
all_y_true.extend(y_test)
all_y_pred.extend(y_pred)
# 计算当前折的指标
acc = accuracy_score(y_test, y_pred)
prec = precision_score(y_test, y_pred, average='weighted', zero_division=0)
rec = recall_score(y_test, y_pred, average='weighted', zero_division=0)
f1 = f1_score(y_test, y_pred, average='weighted', zero_division=0)
print(f" 准确度: {acc:.4f}")
print(f" 精度: {prec:.4f}")
print(f" 召回率: {rec:.4f}")
print(f" F1值: {f1:.4f}")
fold_num += 1
print("\n五折交叉验证完成!")
print()
# ==================== 步骤4:计算并输出模型的准确度、精度、召回率和F1值 ====================
print("=" * 70)
print("步骤4:计算并输出模型的评估指标(整体结果)")
print("=" * 70)
# 计算整体指标
accuracy = accuracy_score(all_y_true, all_y_pred)
precision = precision_score(all_y_true, all_y_pred, average='weighted', zero_division=0)
recall = recall_score(all_y_true, all_y_pred, average='weighted', zero_division=0)
f1 = f1_score(all_y_true, all_y_pred, average='weighted', zero_division=0)
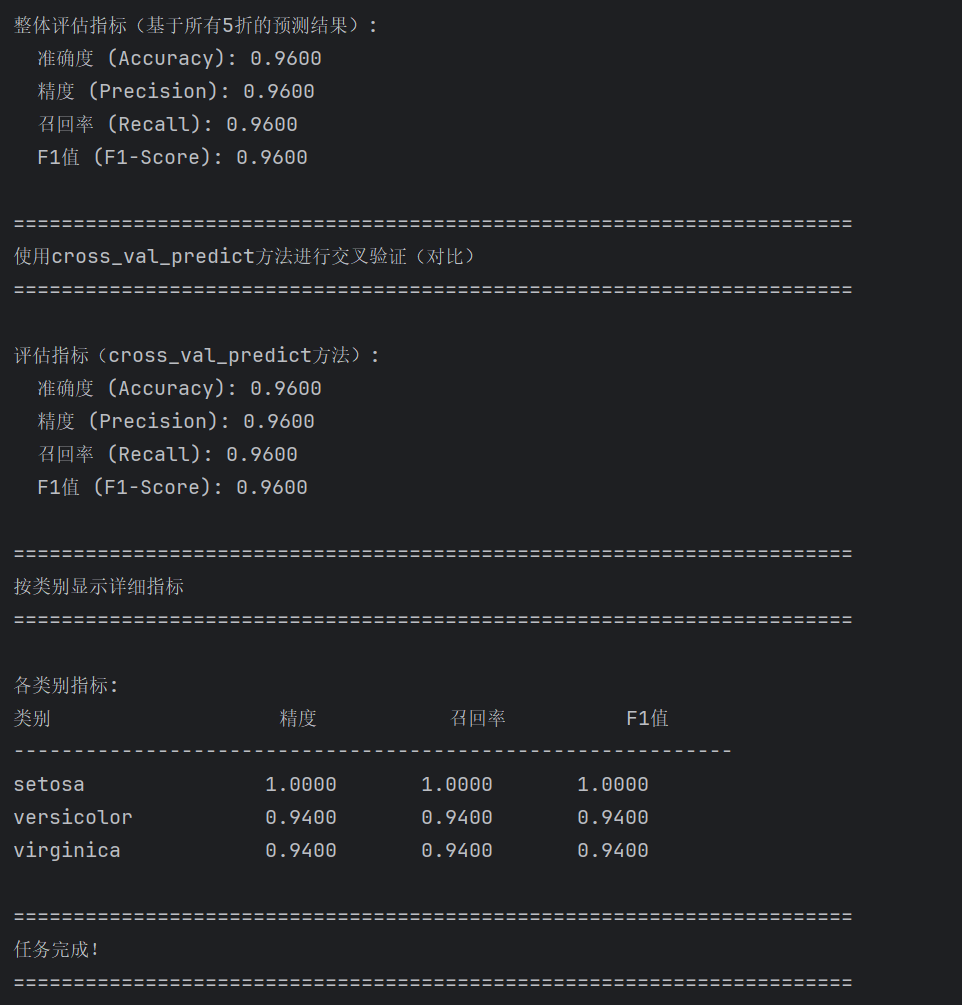
print(f"\n整体评估指标(基于所有5折的预测结果):")
print(f" 准确度 (Accuracy): {accuracy:.4f}")
print(f" 精度 (Precision): {precision:.4f}")
print(f" 召回率 (Recall): {recall:.4f}")
print(f" F1值 (F1-Score): {f1:.4f}")
print()
# 使用cross_val_predict方法(另一种方式)
print("=" * 70)
print("使用cross_val_predict方法进行交叉验证(对比)")
print("=" * 70)
y_pred_cv = cross_val_predict(model, X_scaled, y, cv=5)
accuracy_cv = accuracy_score(y, y_pred_cv)
precision_cv = precision_score(y, y_pred_cv, average='weighted', zero_division=0)
recall_cv = recall_score(y, y_pred_cv, average='weighted', zero_division=0)
f1_cv = f1_score(y, y_pred_cv, average='weighted', zero_division=0)
print(f"\n评估指标(cross_val_predict方法):")
print(f" 准确度 (Accuracy): {accuracy_cv:.4f}")
print(f" 精度 (Precision): {precision_cv:.4f}")
print(f" 召回率 (Recall): {recall_cv:.4f}")
print(f" F1值 (F1-Score): {f1_cv:.4f}")
print()
# 按类别显示详细指标
print("=" * 70)
print("按类别显示详细指标")
print("=" * 70)
precision_per_class = precision_score(all_y_true, all_y_pred, average=None, zero_division=0)
recall_per_class = recall_score(all_y_true, all_y_pred, average=None, zero_division=0)
f1_per_class = f1_score(all_y_true, all_y_pred, average=None, zero_division=0)
print("\n各类别指标:")
print(f"{'类别':<20} {'精度':<12} {'召回率':<12} {'F1值':<12}")
print("-" * 60)
for i, class_name in enumerate(target_names):
print(f"{class_name:<20} {precision_per_class[i]:<12.4f} {recall_per_class[i]:<12.4f} {f1_per_class[i]:<12.4f}")
print("\n" + "=" * 70)
print("任务完成!")
print("=" * 70)
实验结果得到的数据:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号