



一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
NBA球星科比布莱恩特20年职业生涯季后赛赛季48分钟场均数据爬取
2.主题式网络爬虫爬取的内容与数据特征分析
科比20年生涯巅峰季后赛赛季(得分、篮板、助攻、抢断、盖帽)、总得分以及最强数据
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
1.numpy函数、requests库、re正则获取网页数据
2.BeautifulSoup库解析页面内容
3.padads库将爬取的数据保存为xls形式
4.pandas数据清洗和处理
5.matplotilb库可视化数据绘图
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征

2.Htmls页面解析
import requests from bs4 import BeautifulSoup url = 'http://www.stat-nba.com/player/195.html' def getHTMLText(url,timeout=30): try: r=requests.get(url,timeout=30) r.raise_for_status() r.encoding=r.apparent_encoding return r.text except: return '产生异常' html = getHTMLText(url) soup=BeautifulSoup(html,'html.parser') print(soup.prettify())
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
查找方法:find_all
1.数据爬取与采集
遍历方法:for循环
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。1.数据爬取与采集
import requests
from bs4 import BeautifulSoup
import bs4
import pandas as pd
url = 'http://www.stat-nba.com/query.php?QueryType=ss&SsType=season&Player_id=195&AT=48&Mp0=0'
def getHTMLText(url,timeout=30):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return '产生异常'
#获取所有页面的URL列表
html=getHTMLText(url)
soup=BeautifulSoup(html,'html.parser')
final_list=[]
def get_uniInfo(html,final_list):
soup=BeautifulSoup(html,'html.parser')
body=soup.body
data=body.find('tbody',{'class':'normal'})
trs=data.find_all('tr')
for uniInfo in trs:
temp_list=[]
info=uniInfo.find_all('tr')#找到所有“tr”标签
#数据提取
temp_list.append(info[0].string)
temp_list.append(info[1].string)
temp_list.append(info[2].string)
temp_list.append(info[3].string)
temp_list.append(info[4].string)
temp_list.append(info[5].string)
temp_list.append(info[6].string)
temp_list.append(info[7].string)
temp_list.append(info[8].string)
temp_list.append(info[9].string)
temp_list.append(info[10].string)
temp_list.append(info[11].string)
temp_list.append(info[12].string)
temp_list.append(info[13].string)
temp_list.append(info[14].string)
temp_list.append(info[15].string)
temp_list.append(info[16].string)
temp_list.append(info[17].string)
temp_list.append(info[18].string)
temp_list.append(info[19].string)
temp_list.append(info[20].string)
temp_list.append(info[21].string)
temp_list.append(info[22].string)
temp_list.append(info[23].string)
temp_list.append(info[24].string)
temp_list.append(info[25].string)
#数据存取在列表中
if info[0].find('td'):#找到tr标签下的第1个td标签的值
kobe=info[0].find('td').string
temp_list.append(kobe)
if info[1].find('td'):#找到tr标签下的第2个td标签的值
kobe=info[1].find('td').string
temp_list.append(kobe)#添加到find_list列表中
if info[2].find('td'):
kobe=info[2].find('td').string
temp_list.append(kobe)
if info[3].find('td'):
kobe=info[3].find('td').string
temp_list.append(kobe)
if info[4].find('td'):
kobe=info[4].find('td').string
temp_list.append(kobe)
if info[5].find('td'):
kobe=info[5].find('td').string
temp_list.append(kobe)
if info[6].find('td'):
kobe=info[6].find('td').string
temp_list.append(kobe)
if info[7].find('td'):
kobe=info[7].find('td').string
temp_list.append(kobe)
if info[8].find('td'):
kobe=info[8].find('td').string
temp_list.append(kobe)
if info[9].find('td'):
kobe=info[9].find('td').string
temp_list.append(kobe)
if info[10].find('td'):
kobe=info[10].find('td').string
temp_list.append(kobe)
if info[11].find('td'):#找到tr标签下的第11个td标签的值
kobe=info[11].find('td').string
temp_list.append(kobe)#添加到find_list列表中
if info[12].find('td'):
kobe=info[12].find('td').string
temp_list.append(kobe)
if info[13].find('td'):
kobe=info[13].find('td').string
temp_list.append(kobe)
if info[14].find('td'):
kobe=info[14].find('td').string
temp_list.append(kobe)
if info[15].find('td'):
kobe=info[15].find('td').string
temp_list.append(kobe)
if info[16].find('td'):
kobe=info[16].find('td').string
temp_list.append(kobe)
if info[17].find('td'):
kobe=info[17].find('td').string
temp_list.append(kobe)
if info[18].find('td'):
kobe=info[18].find('td').string
temp_list.append(kobe)
if info[19].find('td'):
kobe=info[19].find('td').string
temp_list.append(kobe)
if info[20].find('td'):
kobe=info[20].find('td').string
temp_list.append(kobe)
if info[21].find('td'):#找到tr标签下的第21个td标签的值
kobe=info[21].find('td').string
temp_list.append(kobe)#添加到find_list列表中
if info[22].find('td'):
kobe=info[22].find('td').string
temp_list.append(kobe)
if info[23].find('td'):
kobe=info[23].find('td').string
temp_list.append(kobe)
if info[24].find('td'):
kobe=info[24].find('td').string
temp_list.append(kobe)
if info[25].find('td'):
kobe=info[25].find('td').string
temp_list.append(kobe)
final_list.append(temp_list)
#print(final_list)
#转为数据框,保存为csv文件
get_uniInfo(html,final_list)
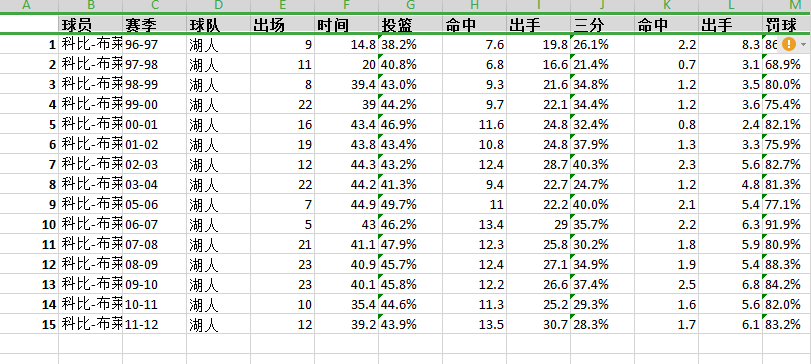
df=pd.DataFrame(final_list,columns=['球员','赛季','球队','出场','时间','投篮','命中','出手','三分','命中','三分','罚球','命中','出手','篮板','前场','后场','助攻','抢断','盖帽','失误','犯规','得分'])
filename="kobe.csv"
df.to_csv('D://filename.csv',encoding="utf-8")#csv文件存储在D盘
#导入数据并显示
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
kobe = pd.DataFrame(pd.read_excel('C:\\kobe.xlsx',sep = '\t',encoding = 'utf-8'))#导入爬取的数据(xls格式)
kobe.shape
kobe.head()#显示前五行

def getcommodity(coms):
for i in range(1, 3):
html = ahtml('http://www.stat-nba.com/query.php?QueryType=ss&SsType=season&Player_id=195&AT=48&Mp0=0'.format(i))
soup = BeautifulSoup(html, "html.parser")
for span in soup.find_all("p", attrs="name"):
temp = span.a.attrs['href']
temp1 = temp.split('/')[2]
temp2 = temp1.split('-')[0]
coms.append(temp2)
return coms
删除无效列(‘命中’和‘出手’)
kobe.drop('出手',axis=1,inplace=True) #删除无效列出手
kobe.head()#显示前五行
kobe.drop('命中',axis=1,inplace=True) #删除无效列命中
kobe.head()#显示前五行
kobe.describe()

total_points=(kobe.得分*kobe.出场).sum()#总得分 avg_points=total_points/kobe.出场.sum()#平均分 total_points avg_points
数据清洗后,得出数据显示20年20年职业生涯季后赛赛季48分钟场均30.9706分,总分为6814.8分,最低得分5.00分,最高36.800分


季后赛得分最高得分为11-12赛季,得分超过30分的赛季有00-01、02-03、06-07、07-08、08-09、09-10、10-11、11-12赛季
max_point=kobe.得分.max() print(kobe[kobe.得分==max_point])#显示最高得分赛季 print(kobe.loc[kobe.得分>=30])#显示得分超过30分的赛季

科比20年生涯巅峰季后赛赛季最强数据(得分、篮板、助攻、抢断、盖帽)
max_kobe={'point':kobe.得分.max(),'rebounds':kobe.篮板.max(),'assistants':kobe.助攻.max(),'steals':kobe.抢断.max(),'blocks':kobe.盖帽.max()}
best_kobe=pd.Series(max_kobe)
best_kobe

3.文本分析(可选):jieba分词、wordcloud可视化
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
kobe = pd.DataFrame(pd.read_excel('C:\\kobe.xlsx',sep = '\t',encoding = 'utf-8'))
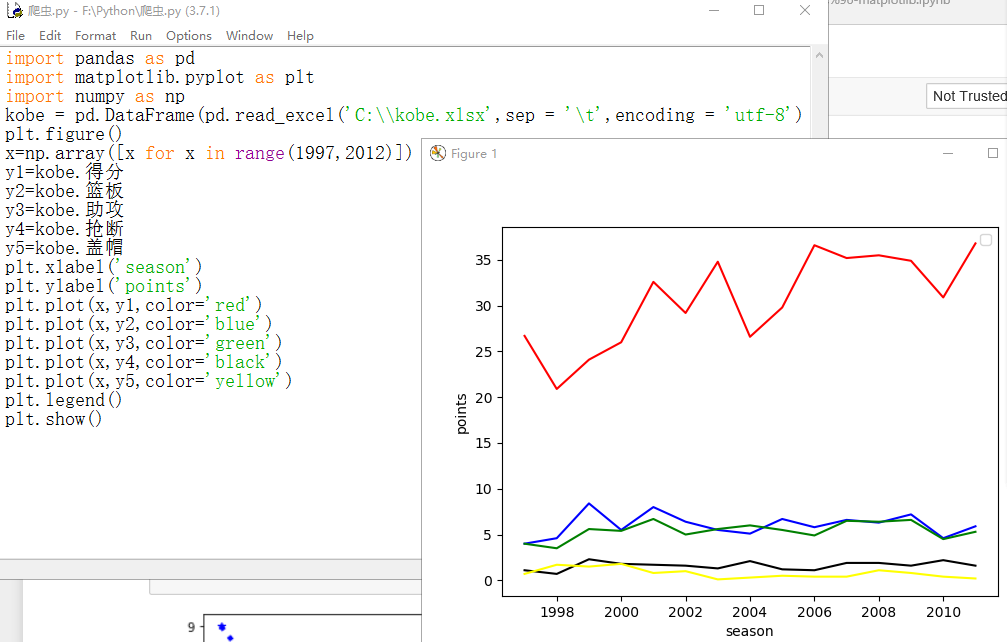
plt.figure()#绘制画板
x=np.array([x for x in range(1997,2012)])#x轴为年份
y1=kobe.得分#y1轴为得分
y2=kobe.篮板#y2轴为篮板
y3=kobe.助攻#y3轴为助攻
y4=kobe.抢断#y4轴为抢断
y5=kobe.盖帽#y5轴为盖帽
plt.xlabel('season')
plt.ylabel('points')
plt.plot(x,y1,color='red')
plt.plot(x,y2,color='blue')
plt.plot(x,y3,color='green')
plt.plot(x,y4,color='black')
plt.plot(x,y5,color='yellow')
plt.legend()
plt.show()
x=np.array([x for x in range(1997,2017)])
y=kobe.助攻
plt.xlabel('season')
plt.ylabel('points')
plt.bar(x,y,width=0.5,color='m')
plt.xticks(x)
ax=plt.gca()
x_lables=ax.xaxis
for each in x_lables.get_ticklabels():
each.set.set_rotation(-45)
plt.show()
5.数据持久化
for into in printUnivList:
#数据保存
dataSave()
try:
# 创建文件用于存储爬取到的数据
with open("C:\\kobe.txt", "a") as f:
f.write("球员","赛季","球队","出场","首发","时间","投篮","命中","出手","三分","命中","出手","罚球","命中","出手","篮板",
"前场","后场","助攻","抢断","盖帽","失误","犯规","得分","胜","负",chr(12288)))
except:
"存储失败"
print("正在存储".format(into))
for x in dic.get(into):
url = "view-source:http://www.stat-nba.com/query.php?QueryType=ss&SsType=season&Player_id=195&AT=48&Mp0=0" + x
html = getHtml(url)
try:
# 创建文件用于存储爬取到的数据
with open("C:\\kobe.txt", "a") as f:
f.write(tplt.format(u[0],u[1],u[2],u[3],u[4],u[5],u[6],u[7],u[8],u[9],u[10],u[11],u[12],u[13],u[14],u[15],u[16],u[17],u[18],u[19],u[20],
u[21],u[22],u[23],u[24],u[25],u[26],chr(12288)))
except:
"存储失败"
print("存储成功")
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论? 通过以上的各种可视化数据可以很明显看出科比布莱恩特在96-97赛季开始,连续15个赛季进入季后赛,且进步十分神速,在进三四个赛季来得分在30分左右徘徊。从青涩少年到联盟球星1996年,得分7.6,篮板1.9,助攻1.3(新秀年,科比的数据还算可以)1997年,得分15.4,篮板3.5,助攻2.5(开始慢慢进步)1998年,得分19.9,篮板5.3,助攻3.8(这一年迎来质的飞跃)1999年,得分22.5,篮板6.3,助攻4.9(场均20多分让他步入了球星行列)从球星到总冠军2000年,得分28.5,篮板5.9,助攻5.0(此时科比虽已有奥尼尔,但科比的数据相当亮眼,这一年,OK组合开启夺冠模式)2001年,得分25.2,篮板5.5,助攻5.5(虽说比上年有所下滑,但科比秋风更加成熟)2002年,得分30.0,篮板6.9,助攻5.9(三连冠最后一年,他火力全开)2003年,得分24.0,篮板5.5,助攻5.1(马龙和佩顿的到来,让科比的得分有所下降)独自带队,前途漫漫2004年,得分27.6,篮板5.9,助攻6.0(F4解体,科比独自带队)2005年,得分35.4,篮板5.3,助攻4.5(开启生涯里最强飙分模式)2006年,得分31.6,篮板5.7,助攻5.4(81分便是这年)2007年,得分28.3,篮板6.3,助攻5.4(加索尔中途来到湖人)。紧接着连续两年的冠军后,科比一度受伤惨重,负伤恢复后逐渐走下坡路。爬取球星职业生涯的数据本意是对于篮球的热爱,从各种数据更直观的去了解球星 职业生涯的表现。
2.对本次程序设计任务完成的情况做一个简单的小结。
刚开始对爬虫仅停留在基础的位置,并不是很了解。但通过爬虫的这实战项目,个人觉得非常适合python爬虫初学者,掌握python基本编程语法后,通过几周嵩老师的讲解和老师上课泰坦尼克号的案例,就可以进行定向爬取所需基本的一些案例。如果掌握学习的程度还是需要通过实战进行更深度的了解,通过这个比较大型的实战让我对于网络爬虫有深刻的理解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号