(爬虫)Python爬虫03(隐藏)
目录:
一、模拟浏览器访问
二、延迟提交时间
三、使用代理
四、相关资源及问题
因为爬虫会给服务器带来太大的工作压力,所以好多服务器是将爬虫拒之门外的,那么我们如何让服务器觉得是人类在访问,而非是代码爬虫呢?实现代码如下:


import urllib.request #引入请求依赖 import urllib.parse #引入解析依赖 import json #引入json依赖 while 1: #将输入内容存为变量 content = input("请输入需要翻译的内容(输入exit退出程序):") #判断是否要退出程序 if content == "exit": print("退出成功!") break #将链接Request URL存储为变量,便于使用 url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule" #将表单From Data赋值给字典data data = {} data["i"] = content #将表单中i的值换为变量content(自己输入的内容) data["from"] = "AUTO" data["to"] = "AUTO" data["smartresult"] = "dict" data["client"] = "fanyideskweb" data["salt"] = "15838472422107" data["sign"] = "85a1e803f3f0d04882d66c8cca808347" data["ts"] = "1583847242210" data["bv"] = "d6c3cd962e29b66abe48fcb8f4dd7f7d" data["doctype"] = "json" data["version"] = "2.1" data["keyfrom"] = "fanyi.web" data["action"] = "FY_BY_CLICKBUTTION" #将data编码为url的形式,且将Unicode硬编码为utf-8的形式,存储到data_utf8变量中 data_utf8 = urllib.parse.urlencode(data).encode("utf-8") #*********************************较Python02博客的增加处********************************* #让服务器认为这是一个浏览器在访问,而非代码爬虫(如果不自定义User-Agent,在爬虫时会是代码的有关信息,而非客户端的基本信息) #自定义Request Headers中的User-Agent,存储到字典head中(如果Request Headers和User-Agent不知道是什么,请查看本人的上篇博客(爬虫)Python02(实战)) head = {} head["User-Agent"] = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" #*********************************较Python02博客的修改处********************************* #根据url,data_utf8,head获取请求对象(urlopen不能自动转化带head的,所以要用Request去获取请求对象了) req = urllib.request.Request(url,data_utf8,head) #访问 请求对象req,并返回 应答对象response response = urllib.request.urlopen(req) ''' #注意:也可以将上边的增加处和修改处全部去掉,换成如下代码效果和原理是一模一样的: req = urllib.request.Request(url,data_utf8) req.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36") response = urllib.request.urlopen(req) ''' #将读取的utf-8编码的文件解码回Unicode编码形式 html = response.read().decode("utf-8") print("******返回的原始数据******") #打印输出 (观察会发现:返回的是json结构) print(html) #用json载入字符串(观察发现是一个字典) target = json.loads(html) #打印输出字典中的指定值(即翻译结果) print("******显示处理后的结果******") print("翻译结果:%s" % (target["translateResult"][0][0]["tgt"]))
因为人类访问不会像爬虫那样特别频繁访问请求,所以服务器会判断同一IP如果访问过于频繁,会判定为是代码爬虫,爬虫同样会被拒之门外,为了让代码爬虫更像是人类在访问,我们可以延迟提交时间,实现代码如下(注意:只在文件开头和结尾处做了两行添加):
import urllib.request #引入请求依赖 import urllib.parse #引入解析依赖 import json #引入json轻量级数据依赖 #*********************************较 一、模拟浏览器访问 增加处********************************* import time #引入时间处理依赖 while 1: #将输入内容存为变量 content = input("请输入需要翻译的内容(输入exit退出程序):") #判断是否要退出程序 if content == "exit": print("退出成功!") break #将链接Request URL存储为变量,便于使用 url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule" #将表单From Data赋值给字典data data = {} data["i"] = content #将表单中i的值换为变量content(自己输入的内容) data["from"] = "AUTO" data["to"] = "AUTO" data["smartresult"] = "dict" data["client"] = "fanyideskweb" data["salt"] = "15838472422107" data["sign"] = "85a1e803f3f0d04882d66c8cca808347" data["ts"] = "1583847242210" data["bv"] = "d6c3cd962e29b66abe48fcb8f4dd7f7d" data["doctype"] = "json" data["version"] = "2.1" data["keyfrom"] = "fanyi.web" data["action"] = "FY_BY_CLICKBUTTION" #将data编码为url的形式,且将Unicode硬编码为utf-8的形式,存储到data_utf8变量中 data_utf8 = urllib.parse.urlencode(data).encode("utf-8") #让服务器认为这是一个浏览器在访问,而非代码爬虫(如果不自定义User-Agent,在爬虫时会是代码的有关信息,而非客户端的基本信息) #自定义Request Headers中的User-Agent,存储到字典head中(如果Request Headers和User-Agent不知道是什么,请查看本人的上篇博客(爬虫)Python02(实战)) head = {} head["User-Agent"] = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" #根据url,data_utf8,head获取请求对象(urlopen不能自动转化带head的,所以要用Request去获取请求对象了) req = urllib.request.Request(url,data_utf8,head) #访问 请求对象req,并返回 应答对象response response = urllib.request.urlopen(req) ''' #注意:也可以将上边的增加处和修改处全部去掉,换成如下代码效果和原理是一模一样的: req = urllib.request.Request(url,data_utf8) req.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36") response = urllib.request.urlopen(req) ''' #将读取的utf-8编码的文件解码回Unicode编码形式 html = response.read().decode("utf-8") print("******返回的原始数据******") #打印输出 (观察会发现:返回的是json结构) print(html) #用json载入字符串(观察发现是一个字典) target = json.loads(html) #打印输出字典中的指定值(即翻译结果) print("******显示处理后的结果******") print("翻译结果:%s" % (target["translateResult"][0][0]["tgt"])) #*********************************较 一、模拟浏览器访问 增加处********************************* #让程序睡2秒,让远端服务器更觉得是人类使用客户端在访问,而非代码爬虫 time.sleep(2)
由于使用延迟提交时间的方法爬虫效率太低,那么可以使用另一种方式——代理,实现代码如下:
import urllib.request #爬虫依赖 import random #导入随机抽取的依赖,用于从资源池中随机抽取代理 #可以测试目前访问该网页的IP是什么(要用http类型的代理IP) url_1 = "http://httpbin.org/ip" #代理资源池(因为免费代理很不稳定,可以预先存储多个) iplist_1 = ["101.4.136.34:81","221.180.170.104:8080"] #显示从资源池中随机抽取到的IP地址 ip = random.choice(iplist_1) print(ip) #设置http类型的代理IP proxy_support_1 = urllib.request.ProxyHandler({"http":ip}) #定制自己的opener opener_1 = urllib.request.build_opener(proxy_support_1) #为定制的opener添加header(也可以在请求时再加header信息) opener_1.addheaders = [("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36")] #安装opener(类似创建opener全局变量,以后在使用urlopen()时就默认使用该opener) urllib.request.install_opener(opener_1) """ #调用opener(只在本次使用自定义的opener访问url) opener.open(url_1) """ print("*********************************HTTP代理IP*********************************") response_1 = urllib.request.urlopen(url_1) html_1 = response_1.read ().decode("utf-8") print(html_1) """ #与http代理ip实现原理相同(资源池之类实现代码及相关注释的就不再这里赘余了) #可以测试目前访问该网页的IP是什么(要用https类型的代理IP) url_2 = "https://www.ip.cn/" #https类型的带来IP proxy_support_2 = urllib.request.ProxyHandler({"https":"27.43.188.230:3000"}) opener_2 = urllib.request.build_opener(proxy_support_2) opener_2.addheaders = [("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36")] urllib.request.install_opener(opener_2) print("*********************************HTTPS代理IP*********************************") response_2 = urllib.request.urlopen(url_2) html_2 = response_2.read ().decode("utf-8") print(html_2) """
运行截图:
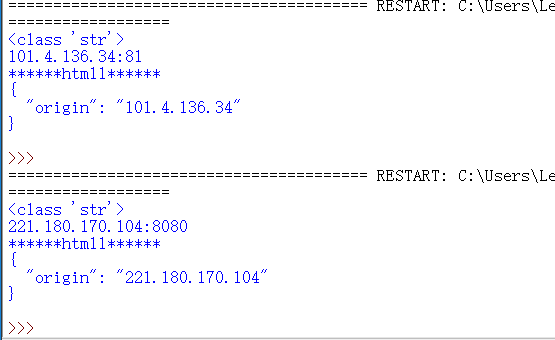
1、相关资源:免费代理的网站(要多试几个,毕竟是免费的嘛,你懂得~~)
西刺免费代理IP : https://www.xicidaili.com/
无忧代理 : http://www.data5u.com/
全国代理IP : http://www.goubanjia.com/
2、相关问题:
(1)
问题:在执行第三个示例:使用代理的代码时,有可能会报错,类似: 主机频繁拒绝;连接方在一段时间后没有正确答复或主机没有反应,连接尝试失败 等等这类的信息(基本上等的时间比较长的(8秒左右),差不多都会返回这类信息)
解决办法:基本都是由于代理IP不好用,多换几个试试。
(2)
问题:返回的IP不是代理IP而是本机IP
解决办法:多半是因为你的代理IP类型与访问网址的协议类型不匹配(HTTP类型的代理只能访问HTTP开头的网址,不可以访问HTTPS开头的网址;HTTPS类型的代理同理。所以一定要对应好类型)
(3)
注意:HTTP类型的免费代理还是比较好找到的,但是HTTPS类型的免费代理比较难试成功,就算试成功了也只能维持一小小小会儿。
当然如果你们有好的免费代理IP资源可以留言呦!!!
爬虫上一篇:(爬虫)Python爬虫02(实战)
本博客参考:
零基础入门学习Python https://www.bilibili.com/video/av4050443?p=56

 浙公网安备 33010602011771号
浙公网安备 33010602011771号