

Elaticsearch(一)--基础原理及用法
一、基础概念
1、Elasticsearch简介
Lucene是Java语言编写的全文(全部的文本内容进行分析,建立索引,使之可以被搜索)检索引擎工具包(全文检索引擎的架构),用于处理纯文本的数据,提供建立索引、执行搜索等接口,但不包含分布式服务。
Elasticsearch是近实时(新增到 ES 中的数据在1秒后就可以被检索到,这种新增数据对搜索的可见性称为“准实时搜索”)的分布式搜索分析引擎,内部使用Lucene做索引与搜索。ES分布式意味着可以动态调整集群规模,弹性扩容,从官方的描述,集群规模支持“上百”个节点。因此,目前认为ES适合中等数据量的业务,不适合存储海量数据。
基于ES可以很容易地搭建自己的搜索引擎,用于分析日志,或者建立某个垂直领域的搜索引擎。此外,ES 还提供了大量的聚合功能,所以它不单单是一个搜索引擎,还可以进行数据分析、统计,生成指标数据。
2、常用概念
2.1)索引词(term)
在Elasticsearch中索引词(term)是一个能够被索引的精确值。索引词(term)是可以通过term查询进行准确搜索。
2.2)文本(text)
文本是一段普通的非结构化文字。文本会被分析成一个个的索引词,存储在Elasticsearch的索引库中。为了让文本能够进行搜索,文本字段需要事先进行分析;当对文本中的关键词进行查询的时候,搜索引擎应该根据搜索条件搜索出原文本。
引申:keyword,存储数据时候,不会分词建立索引。
2.3)分析(analysis)
分析是将文本转换为索引词的过程,分析的结果依赖于分词器。比如:FOO BAR、Foo-Bar和foo bar这几个单词有可能会被分析成相同的索引词foo和bar,这些索引词存储在Elasticsearch的索引库中。当用FoO:bAR进行全文搜索的时候,搜索引擎根据匹配计算也能在索引库中搜索出之前的内容。这就是Elasticsearch的搜索分析。
2.4)索引(index)
索引是具有相同结构的文档集合。_index指向一个或多个物理分片的逻辑命名空间。在系统上索引的名字全部小写,通过这个名字可以用来执行索引、搜索、更新和删除操作等,在单个集群中,可以定义多个索引。
es索引结构如图
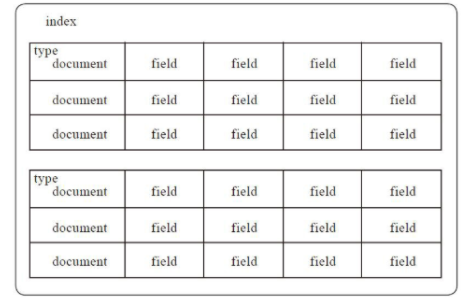
类型(type)
在索引中,可以定义一个或多个类型,类型是索引的逻辑分区。在一般情况下,一种类型被定义为具有一组公共字段的文档。例如,假设运行一个博客平台,并把所有的数据存储在一个索引中。在这个索引中,可以定义一种类型为用户数据,一种类型为博客数据,另一种类型为评论数据。
2.5)文档(document)
文档是存储在Elasticsearch中的一个JSON格式的字符串。它就像在关系数据库中表的一行。每个存储在索引中的一个文档都有一个类型和一个ID,每个文档都是一个JSON对象,存储了零个或者多个字段,或者键值对。
注意:原始的JSON文档被存储在一个_source的字段中。当搜索文档的时候默认返回的就是这个字段。
2.6)映射(mapping)
映射像关系数据库中的表结构,每一个索引都有一个映射,它定义了索引中的每一个字段类型,以及一个索引范围内的设置。一个映射可以事先被定义,或者在第一次存储文档的时候自动识别。
2.7)字段(field)
文档中包含零个或者多个字段,字段可以是一个简单的值(例如字符串、整数、日期),也可以是一个数组或对象的嵌套结构。字段类似于关系数据库中表的列。每个字段都对应一个字段类型,例如整数、字符串、对象等。字段还可以指定如何分析该字段的值。
2.8)来源字段(source field)
默认情况下,原文档将被存储在_source这个字段中,查询的时候也是返回这个字段。可以从搜索结果中访问原始的对象,这个对象返回一个精确的JSON字符串,不显示索引分析后的其他任何数据。
2.9)主键(ID)
ID是一个文件的唯一标识,如果在存库的时候没有提供ID,系统会自动生成一个ID,文档的index/type/id必须是唯一的。
2.10)映射(mapping)
映射是定义文档及其包含的字段如何存储和索引的过程。
使用映射通常定义:
- 哪些字符串字段应被视为全文字段。
- 哪些字段包含数字、日期或地理位置。
- 日期值的格式。
- 自定义规则来控制动态添加字段的映射 。
- (1)元字段
_index,_type, _id,和_source领域。每个文档都有与其关联的元数据,例如_index、 mapping _type和_id元字段。创建映射类型时,可以自定义其中一些元字段的行为。_source 表示文档正文的原始 JSON。_size _source由mapper-size插件提供 的字段大小(以字节为单位) 。 _field_names文档中包含非空值的所有字段。_ignored文档中由于 ignore_malformed. _routing将文档路由到特定分片的自定义路由值。
- (2)字段或属性
properties与文档相关的字段列表。字段数据类型每个字段都有一个数据type- 一个简单的类型,如
text,keyword,date,long,double,boolean或ip。 - 一种支持 JSON 分层性质的类型,例如
object或nested。 - 或特殊类型,如
geo_point,geo_shape, 或completion。
string字段可以被索引为一个text,用于全文搜索的keyword字段,以及一个用于排序或聚合的字段。这就是多字段的目的,大多数数据类型通过fields参数支持多字段。补充:
1)、防止映射爆炸的设置
在索引中定义太多字段会导致映射爆炸,从而导致内存不足错误和难以恢复的情况。例如,考虑这样一种情况,插入的每个新文档都会引入新字段。每次文档包含新字段时,这些字段都会追加在在索引的映射中,随着映射的增长,可能会成为一个问题。以下设置限制可以手动或动态创建的字段映射的数量,以防止不良文档导致映射爆炸:
index.mapping.total_fields.limit索引中的最大字段数。字段和对象映射以及字段别名计入此限制。默认值为1000。(限制是为了防止映射和搜索变得太大。较高的值会导致性能下降和内存问题,尤其是在负载高或资源少的集群中。如果增加此设置,建议也增加该 indices.query.bool.max_clause_count设置,这会限制查询中布尔子句的最大数量。)
index.mapping.depth.limit最大深度,以内部对象的数量来衡量。例如,如果所有字段都在根对象级别定义,则深度为1。如果有一个对象映射,则深度为 2等。默认为20。 index.mapping.nested_fields.limitnested索引 中不同映射的最大数量,默认为50。index.mapping.nested_objects.limitnested单个文档中所有嵌套类型 的最大JSON 对象数,默认为 10000。
index.mapping.field_name_length.limit设置字段名称的最大长度。默认值为 Long.MAX_VALUE(无限制)。此设置并不是真正解决映射爆炸的问题,但如果限制字段长度,它可能仍然有用。通常不需要设置此设置。除非用户开始添加大量名称非常长的字段,否则默认值是可以的。
2)、mapping设置
2.1)mapping中的字段类型一旦设置,一旦已经有数据写入,禁止直接修改,因为 lucene实现的倒排索引生成后不允许修改(但是可以新增字段),应该重新建立新的索引,然后做reindex操作。
1. 新增加字段
- Dynamic设为true时,一旦有新增字段的文档写入,Mapping也会同时被更新;
- Dynamic设为false,Mapping不会被更新,新增字段的数据无法被索引,但是信息会出现在_source中;
- Dynamic设置成strict,文档写入失败。
2. 如果希望修改字段类型,必须Reindex API,重建索引,因为如果修改了字段的数据类型,会导致已被索引的无法被搜索,但是如果是新增加的字段,就不会有这样的影响。
2.2)Dynamic Mapping
- 写入文档时候,如果索引不存在,会自动创建索引;
- Dynamic Mapping机制,使得我们无需手动定义Mappings。Elasticsearch会自动根据文档信息推算出字段的类型;
- 若自动推算的不对,例如地理位置信息,数值类型等,会导致部分函数无法使用(range等)。
二、常用用法
1、响应过滤
所有 REST API 都接受一个filter_path参数,该参数可用于减少 Elasticsearch 返回的响应。此参数采用逗号分隔的过滤器列表,用点表示法表示:
eg1:
curl -X GET "localhost:9200/_search?q=elasticsearch&filter_path=took,hits.hits._id,hits.hits._score&pretty"
结果
{
"took" : 3,
"hits" : {
"hits" : [
{
"_id" : "0",
"_score" : 1.6375021
}
]
}
}
eg2:
curl -X GET "localhost:9200/_cluster/state?filter_path=metadata.indices.*.stat*&pretty"
{
"metadata" : {
"indices" : {
"twitter": {"state": "open"}
}
}
}
eg3:
curl -X GET "localhost:9200/_cluster/state?filter_path=routing_table.indices.**.state&pretty"
{
"routing_table": {
"indices": {
"twitter": {
"shards": {
"0": [{"state": "STARTED"}, {"state": "UNASSIGNED"}]
}
}
}
}
}
eg4:
curl -X GET "localhost:9200/_count?filter_path=-_shards&pretty"
{
"count" : 5
}
eg5:
curl -X GET "localhost:9200/_cluster/state?filter_path=metadata.indices.*.state,-metadata.indices.logstash-*&pretty"
{
"metadata" : {
"indices" : {
"index-1" : {"state" : "open"},
"index-2" : {"state" : "open"},
"index-3" : {"state" : "open"}
}
}
}
eg6:
Elasticsearch 有时会直接返回字段的原始值,例如_source字段。如果要过滤_source字段,应考虑将现有_source参数与如下filter_path 参数组合使用:
curl -X POST "localhost:9200/library/book?refresh&pretty" -H 'Content-Type: application/json' -d'
{"title": "Book #1", "rating": 200.1}
'
curl -X POST "localhost:9200/library/book?refresh&pretty" -H 'Content-Type: application/json' -d'
{"title": "Book #2", "rating": 1.7}
'
curl -X POST "localhost:9200/library/book?refresh&pretty" -H 'Content-Type: application/json' -d'
{"title": "Book #3", "rating": 0.1}
'
curl -X GET "localhost:9200/_search?filter_path=hits.hits._source&_source=title&sort=rating:desc&pretty"
{
"hits" : {
"hits" : [ {
"_source":{"title":"Book #1"}
}, {
"_source":{"title":"Book #2"}
}, {
"_source":{"title":"Book #3"}
} ]
}
}
备注:&pretty 表示返回结果以json格式美化展示。
2、启用堆栈跟踪
默认情况下,当请求返回错误时,Elasticsearch 不包括错误的堆栈跟踪。通过将error_trace在url 参数设置为 true。
eg,默认情况下,向API发送无效size参数时_search:
curl -X POST "localhost:9200/twitter/_search?size=surprise_me&pretty"
{
"error" : {
"root_cause" : [
{
"type" : "illegal_argument_exception",
"reason" : "Failed to parse int parameter [size] with value [surprise_me]"
}
],
"type" : "illegal_argument_exception",
"reason" : "Failed to parse int parameter [size] with value [surprise_me]",
"caused_by" : {
"type" : "number_format_exception",
"reason" : "For input string: \"surprise_me\""
}
},
"status" : 400
}
设置error_trace=true:
curl -X POST "localhost:9200/twitter/_search?size=surprise_me&error_trace=true&pretty"
{
"error": {
"root_cause": [
{
"type": "illegal_argument_exception",
"reason": "Failed to parse int parameter [size] with value [surprise_me]",
"stack_trace": "Failed to parse int parameter [size] with value [surprise_me]]; nested: IllegalArgumentException..."
}
],
"type": "illegal_argument_exception",
"reason": "Failed to parse int parameter [size] with value [surprise_me]",
"stack_trace": "java.lang.IllegalArgumentException: Failed to parse int parameter [size] with value [surprise_me]\n at org.elasticsearch.rest.RestRequest.paramAsInt(RestRequest.java:175)...",
"caused_by": {
"type": "number_format_exception",
"reason": "For input string: \"surprise_me\"",
"stack_trace": "java.lang.NumberFormatException: For input string: \"surprise_me\"\n at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)..."
}
},
"status": 400
}
3、文档操作
(3.1)插入json文档到索引
eg1:
(1)将 JSON 文档插入twitter索引中,索引_id值为 1:
curl -X PUT "localhost:9200/twitter/_doc/1?pretty" -H 'Content-Type: application/json' -d'
{
"user" : "kimchy",
"post_date" : "2009-11-15T14:12:12",
"message" : "trying out Elasticsearch"
}
'
"_shards" : {
"total" : 2,
"failed" : 0,
"successful" : 2
},
"_index" : "twitter",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"result" : "created"
}
(2)如果不存在具有该 ID 的文档,则使用该_create资源将文档索引到twitter索引中:
curl -X PUT "localhost:9200/twitter/_create/1?pretty" -H 'Content-Type: application/json' -d'
{
"user" : "kimchy",
"post_date" : "2009-11-15T14:12:12",
"message" : "trying out Elasticsearch"
}
'
(3)如果不存在具有该 ID 的文档,则设置op_type要创建的参数以将文档索引到twitter索引中:
curl -X PUT "localhost:9200/twitter/_doc/1?op_type=create&pretty" -H 'Content-Type: application/json' -d'
{
"user" : "kimchy",
"post_date" : "2009-11-15T14:12:12",
"message" : "trying out Elasticsearch"
}
'
eg2:_id从twitter索引中检索0的 JSON 文档
curl -X GET "localhost:9200/twitter/_doc/0?pretty"
{
"_index" : "twitter",
"_type" : "_doc",
"_id" : "0",
"_version" : 1,
"_seq_no" : 10,
"_primary_term" : 1,
"found": true,
"_source" : {
"user" : "kimchy",
"date" : "2009-11-15T14:12:12",
"likes": 0,
"message" : "trying out Elasticsearch"
}
}
检查是否_id存在带有0的文档:
curl -I "localhost:9200/twitter/_doc/0?pretty"
Elasticsearch 返回200 - OK文档是否存在 的状态码404 - Not Found。
(3.2)删除文档
从twitter索引中删除 JSON 文档:
curl -X DELETE "localhost:9200/twitter/_doc/1?pretty"
{
"_shards" : {
"total" : 2,
"failed" : 0,
"successful" : 2
},
"_index" : "twitter",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"_primary_term": 1,
"_seq_no": 5,
"result": "deleted"
}
(3.2.1)路由
如果在索引时使用路由,则还需要指定路由值才能删除文档。如果_routing映射设置为required并且未指定路由值,则删除 API 会抛出 RoutingMissingException并拒绝请求。
curl -X DELETE "localhost:9200/twitter/_doc/1?routing=kimchy&pretty"
补充:es路由机制
Elasticsearch的路由机制即是通过哈希算法,将具有相同哈希值的文档放置到同一个主分片中(默认的路由算法:将文档的ID值作为依据将其哈希映射到相应的主分片上,这种算法基本上会保持所有数据在所有分片上的一个平均分布,而不会产生数据热点。)。类似于通过哈希算法来进行负载均衡。指定路由的目的是将文档存储到对应的分片上。
(3.2.2)超时
执行删除操作时,分配用于执行删除操作的主分片可能不可用。造成这种情况的一些原因可能是主分片当前正在从存储中恢复或正在进行重新定位。默认情况下,删除操作将等待主分片变为可用状态长达 1 分钟,然后才会失败并响应错误。该timeout参数可用于明确指定等待的时间。以下是将其设置为 5 分钟的示例:
curl -X DELETE "localhost:9200/twitter/_doc/1?timeout=5m&pretty"
(3.2.3)删除与指定查询匹配的文档
curl -X POST "localhost:9200/twitter/_delete_by_query?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"message": "some message"
}
}
}
'
(3.2.4)从twitter索引中删除所有推文
curl -X POST "localhost:9200/twitter/_delete_by_query?conflicts=proceed&pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"match_all": {}
}
}
'
(3.2.5)从多个索引中删除文档
curl -X POST "localhost:9200/twitter,blog/_delete_by_query?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"match_all": {}
}
}
'
(3.2.6)将按查询删除操作限制为特定路由值的分片
curl -X POST "localhost:9200/twitter/_delete_by_query?routing=1&pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"range" : {
"age" : {
"gte" : 10
}
}
}
}
'
默认情况下_delete_by_query使用 1000 的滚动批次。(使用scroll_size URL 参数更改批次大小)
curl -X POST "localhost:9200/twitter/_delete_by_query?scroll_size=5000&pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"term": {
"user": "kimchy"
}
}
}
'
(3.3)更新文档
向现有文档添加了一个新字段:
curl -X POST "localhost:9200/test/_update/1?pretty" -H 'Content-Type: application/json' -d'
{
"doc" : {
"name" : "new_name"
}
}
'
更改文档中的个别字段,其余字段保持不变
POST ip:port/index/_update_by_query { "query": { //更新文档的查询条件:城市为北京的文档 "term": { "city": { "value": "北京" } } }, "script": { //条件更新的更新脚本,将城市改为“上海” "source": "ctx._source['city']='上海'", "lang": "painless" } }
4、缓存
默认情况下,清除缓存 API 会清除所有缓存。可通过以下参数的设置来指定清楚执行缓存:
fielddataqueryrequest
curl -X POST "localhost:9200/twitter/_cache/clear?fielddata=true&pretty"
curl -X POST "localhost:9200/twitter/_cache/clear?query=true&pretty"
curl -X POST "localhost:9200/twitter/_cache/clear?request=true&pretty"
fields查询参数。
curl -X POST "localhost:9200/twitter/_cache/clear?fields=foo,bar&pretty"
curl -X POST "localhost:9200/kimchy,elasticsearch/_cache/clear?pretty"
curl -X POST "localhost:9200/_cache/clear?pretty"
curl -X PUT "localhost:9200/twitter?pretty" -H 'Content-Type: application/json' -d'
{
"settings" : {
"index" : {
"number_of_shards" : 3,
"number_of_replicas" : 2
}
}
}
'
curl -X PUT "localhost:9200/twitter?pretty" -H 'Content-Type: application/json' -d'
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 2
}
}
'
curl -X PUT "localhost:9200/test?pretty" -H 'Content-Type: application/json' -d'
{
"settings" : {
"number_of_shards" : 1
},
"mappings" : {
"properties" : {
"field1" : { "type" : "text" }
}
}
}
'
curl -X PUT "localhost:9200/test?pretty" -H 'Content-Type: application/json' -d'
{
"aliases" : {
"alias_1" : {},
"alias_2" : {
"filter" : {
"term" : {"user" : "kimchy" }
},
"routing" : "kimchy"
}
}
}
'
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "test"
}
acknowledged指示是否在集群中成功创建索引,同时 shards_acknowledged指示是否在超时之前为索引中的每个分片启动了所需数量的分片副本。acknowledged或 shards_acknowledged是false,但索引创建成功了。这些值仅指示操作是否在超时之前完成。如果 acknowledged是false,表示我们在使用新创建的索引更新集群状态之前就超时了,但它可能很快就会被创建。如果shards_acknowledged 是false,表示我们在启动所需数量的分片之前超时(默认情况下只是主分片),即使集群状态已成功更新以反映新创建的索引(即acknowledged=true)。index.write.wait_for_active_shards(更改此设置也会影响wait_for_active_shards后续所有写入操作的值):
curl -X PUT "localhost:9200/test?pretty" -H 'Content-Type: application/json' -d'
{
"settings": {
"index.write.wait_for_active_shards": "2"
}
}
'
wait_for_active_shards:
curl -X PUT "localhost:9200/test?wait_for_active_shards=2&pretty"
curl -X DELETE "localhost:9200/twitter?pretty"
curl -X DELETE "localhost:9200/twitter/_alias/alias1?pretty"
curl -X POST "localhost:9200/kimchy/_flush?pretty"
curl -X POST "localhost:9200/kimchy,elasticsearch/_flush?pretty"
curl -X POST "localhost:9200/_flush?pretty"
curl -X GET "localhost:9200/twitter?pretty"
curl -X GET "localhost:9200/logs_20302801/_alias/*?pretty"
{
"logs_20302801" : {
"aliases" : {
"current_day" : {
},
"2030" : {
"filter" : {
"term" : {
"year" : 2030
}
}
}
}
}
}
(5.5)索引别名操作
(5.5.1)创建或更新索引别名
索引别名是用于引用一个或多个现有索引的辅助名称(大多数 Elasticsearch API 接受索引别名来代替索引名称)。
curl -X PUT "localhost:9200/twitter/_alias/alias1?pretty"
eg:请求2030为logs_20302801索引创建别名
curl -X PUT "localhost:9200/logs_20302801/_alias/2030?pretty"
添加基于用户的别名
eg:
(1)创建一个索引users,带有user_id字段的映射
curl -X PUT "localhost:9200/users?pretty" -H 'Content-Type: application/json' -d' { "mappings" : { "properties" : { "user_id" : {"type" : "integer"} } } } '
(2)为特定用户添加索引别名,user_12:
curl -X PUT "localhost:9200/users/_alias/user_12?pretty" -H 'Content-Type: application/json' -d' { "routing" : "12", "filter" : { "term" : { "user_id" : 12 } } } '
(5.5.2)创建索引时添加别名
eg:使用create index API 在索引创建过程中添加索引别名
curl -X PUT "localhost:9200/logs_20302801?pretty" -H 'Content-Type: application/json' -d' { "mappings" : { "properties" : { "year" : {"type" : "integer"} } }, "aliases" : { "current_day" : {}, "2030" : { "filter" : { "term" : {"year" : 2030 } } } } } '
curl -X GET "localhost:9200/_alias/2030?pretty"
{
"logs_20302801" : {
"aliases" : {
"2030" : {
"filter" : {
"term" : {
"year" : 2030
}
}
}
}
}
}
curl -X GET "localhost:9200/_alias/20*?pretty"
{
"logs_20302801" : {
"aliases" : {
"2030" : {
"filter" : {
"term" : {
"year" : 2030
}
}
}
}
}
}
curl -X GET "localhost:9200/twitter,kimchy/_settings?pretty"
curl -X GET "localhost:9200/_all/_settings?pretty"
curl -X GET "localhost:9200/log_2013_*/_settings?pretty"
curl -X GET "localhost:9200/log_2013_-*/_settings/index.number_*?pretty"
curl -X GET "localhost:9200/_template/template_1,template_2?pretty"
curl -X GET "localhost:9200/_template/temp*?pretty"
curl -X GET "localhost:9200/_template?pretty"
curl -X GET "localhost:9200/twitter,kimchy/_mapping?pretty"
curl -X GET "localhost:9200/_all/_mapping?pretty"
curl -X GET "localhost:9200/_mapping?pretty"
curl -X PUT "localhost:9200/library/book/_bulk?refresh&pretty" -H 'Content-Type: application/json' -d' {"index":{"_id": "Leviathan Wakes"}} {"name": "Leviathan Wakes", "author": "James S.A. Corey", "release_date": "2011-06-02", "page_count": 561} {"index":{"_id": "Hyperion"}} {"name": "Hyperion", "author": "Dan Simmons", "release_date": "1989-05-26", "page_count": 482} {"index":{"_id": "Dune"}} {"name": "Dune", "author": "Frank Herbert", "release_date": "1965-06-01", "page_count": 604} '
使用SQL REST API执行 SQL :
curl -X POST "localhost:9200/_sql?format=txt&pretty" -H 'Content-Type: application/json' -d' { "query": "SELECT * FROM library WHERE release_date < \u00272000-01-01\u0027" } '
返回结果
author | name | page_count | release_date ---------------+---------------+---------------+------------------------ Dan Simmons |Hyperion |482 |1989-05-26T00:00:00.000Z Frank Herbert |Dune |604 |1965-06-01T00:00:00.000Z
结构化查询(Query DSL): query的时候,会先比较查询条件,然后计算分值,最后返回文档结果;
结构化过滤(Filter DSL): 过滤器,对查询结果进行缓存,不会计算相关度,避免计算分值,执行速度非常快(推荐使用);
0)通过_source过滤出查询结果只包括指定字段
{
"_source":{
"includes":["idtest"]
},
"query":{
"bool":{
"must":[
{"term":{ "textTest.keyword":"es"}}
],
"filter":[
{
"bool":{
"should":[
{"match_phrase":{"tagTest":"hello"}},
{"bool":{"must":[]}}
]
}
}
]
}
},
"sort":{
}
}
1)结构化过滤(Filter DSL)【 6种过滤 】
term 过滤:term 主要用于精确匹配哪些值,比如数字,日期,布尔值或 not_analyzed 的字符串(未经分析的文本 数据类型),相当于sql age=26
{ "term": { "age": 26 }}
{ "term": { "date": "2014-09-01" }}
terms 过滤:terms 允许指定多个匹配条件。如果某个字段指定了多个值,那么文档需要一起去做匹配。相当于sql: in 查询
{"terms": {"age": [26, 27, 28]}}
range 过滤:range 过滤允许我们按照指定范围查找一批数据,相等于sql between
{ "range": { "price": { "gte": 2000, "lte": 3000 } } } gt : 大于 lt : 小于 gte : 大于等于 lte :小于等于
exists 和 missing 过滤:exists 和 missing 过滤可以用于查找文档中是否包含指定字段或没有某个字段,类似于SQL语句中的 IS_NULL条件
{ "exists": { "field": "title" } }
bool 过滤:用来合并多个过滤条件查询结果的布尔逻辑;
must:多个查询条件的完全匹配,相当于 and。
must_not: 多个查询条件的相反匹配,相当于 not;
should:至少有一个查询条件匹配,相当于 or; 相当于sql and 和or
{ "bool": { "must": { "term": { "folder": "inbox" } }, "must_not": { "term": { "tag": "spam" } }, "should": [{ "term": { "starred": true } }, { "term": { "unread": true } }] } }
2)结构化查询(Query DSL)
bool 查询:bool 查询与 bool 过滤相似,用于合并多个查询子句。不同的是,bool 过滤可以直接给出是否匹配成功, 而bool 查询要计算每一个查询子句的 _score
{ "bool": { "must": { "match": { "title": "how to make millions" } }, "must_not": { "match": { "tag": "spam" } }, "should": [{ "match": { "tag": "starred" } }, { "range": { "date": { "gte": "2014-01-01" } } }] } }
bool嵌套查询
{ "bool": { "should": [{ "term": { "productID": "KDKE-B-9947-#kL5" } }, { "bool": { "must": [{ "term": { "productID": "JODL-X-1937-#pV7" } }, { "term": { "price": 30 } }] } }] } }
match_all 查询:使用match_all 可以查询到所有文档,是没有查询条件下的默认语句。
{
"match_all": {}
}
match 查询:match查询是一个标准查询,不管你需要全文本查询还是精确查询基本上都要用到它。 如果你使用 match 查询一个全文本字段,它会在真正查询之前用分析器先分析match一下查询字符
{ "match": { "tweet": "About Search" } }
multi_match 查询:multi_match查询允许你做match查询的基础上同时搜索多个字段
{ "multi_match": { "query": "full text search", "fields": ["title", "body"] } }
match_phrase:短语查询,full text search 是一个词组,意味着三个词的位置是连续且有顺序
{ "match_phrase": { "title": "full text search", } }
设置slop词组间隔
{ "match_phrase": { "title": { "query": "full text search", "slop": 1 } } }
phrase_prefix 查询:与词组中最后一个词条进行前缀匹配。
{ "query": { "match_phrase_prefix": { "title": { "query": "前缀测试" } } }, "from": 0, "size": 5 }
regexp查询:通配符查询
{ "query": { "regexp": { "title": "W[0-9].+" } } }
过滤查询:查询语句和过滤语句可以放在各自的上下文中,filtered已弃用,用bool代替
{ "query": { "bool": { "must": { "match": { "text": "quick brown fox" } }, "filter": { "term": { "status": "published" } } } }
"from": 0,#从0开始
"size": 10,#显示条数
"sort": { "publish_date": { "order": "desc" } } }
8、聚合
聚合查询主要分为三个类别:
- Metric 指标聚合
- Bucket 桶聚合
- Pipeline 管道聚合
eg:
GET /my-index-000001/_search
{ "query": { "bool": { "must": [ { "constant_score": { "filter": { "term": { "prop1.keyword": "0" } } } }, { "regexp": { "prop2.keyword": ".*es.*" } } ] } }, "from": 0, "size": 1, "aggs": { "group_by_state": { "terms": { "field": "testField.keyword", "size": 2000 } } } }
官放文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/7.4/elasticsearch-intro.html
感谢阅读,如需转载,请注明出处,谢谢!https://www.cnblogs.com/huyangshu-fs/p/11683905.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号