关于Kafka high watermark的讨论2
之前写过一篇关于Kafka High watermark的文章,引起的讨论不少:有赞扬之声,但更多的是针对文中的内容被challenge,于是下定决心找个晚上熬夜再看了一遍,昨晚挑灯通读了一遍确实发现不少错误。鉴于此我决定再写一篇博客重新梳理一下最新版本中High watermark(下称HW)的工作原理,也算是纠正之前文章中的错误。这次我不打算说leader epoch,而只是专门讨论HW、log end offset(日志末端位移,下称LEO)的事情。希望我能把整个流程交代清楚。也许这篇文章依然有很多问题,到时候就恳请各位多多批评指正了:)
和之前第一篇一样,我首先给出与HW、LEO相关的副本角色定义:
- leader副本:分区leader所在broker上面的Replica副本对象,不断处理follower副本发送的FETCH请求
- follower副本:分区follower所在broker上面的Replica副本对象,不断地向leader副本发送FETCH请求
- ISR副本:这实际上是一个副本集合,包含leader副本和所有与leader副本保持同步的follower副本。如何判定保持同步:replica.lag.time.max.ms时间内follower副本未发送任何FETCH请求或未赶上leader副本LEO则判定为不同步
每个Replica对象都有很多属性或字段,和本文相关的是LEO、remote LEO和HW。
- LEO:日志末端位移(log end offset),记录了该Replica对象底层日志(log字段)中下一条消息的位移值。注意是下一条消息!也就是说,如果一个普通topic(非compact策略,即cleanup.policy != compact)的某个分区副本的LEO是10,倘若未发生任何消息删除操作,那么该副本当前保存了10条消息,位移值范围是[0, 9]。此时若有一个producer向该副本插入一条消息,则该条消息的位移值是10,而副本LEO值则更新成11。
- remote LEO:严格来说这是一个集合。leader副本所在broker的内存中维护了一个Partition对象来保存对应的分区信息,这个Partition中维护了一个Replica列表,保存了该分区所有的副本对象。除了leader Replica副本之外,该列表中其他Replica对象的LEO就被称为remote LEO,这些LEO值也是要被更新的。
- HW:上一篇中我是这么描述HW值的——“水位值,对于同一个副本对象而言其HW值不会大于LEO值。小于等于HW值的所有消息都被认为是‘已备份’的”—— 严格来说,我这里说错了。实际上HW值也是指向下一条消息,因此应该这样说:小于HW或在HW以下的消息被认为是“已备份的”。另外上篇文章中的配图也是错误的,如下所示:
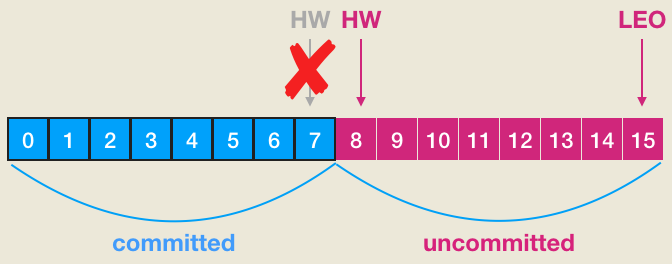
之前文章中说HW是7时,位移介于[0, 7]的所有消息都是committed状态。这种说法是有问题的,实际上,如果要让[0, 7]的消息是committed状态,那么HW值应该是8。当然关于LEO的表述是正确的,即:LEO=15表示这个副本当前有15条消息,最新一条消息的位移是14。另外我们总说consumer是无法消费未提交消息的。这句话如果用以上名词来解读的话,应该表述为:consumer无法消费分区leader副本中位移值大于等于分区HW值的任何消息。这里需要特别注意分区HW值就是leader副本的HW值。
说一些题外话~~~~~
在判断能否消费某条消息时到底比较的是”小于HW“还是”小于等于HW",我个人倾向于认为是小于HW,即位移=HW值的消息是不能被消费的。我们可以从Log.scala的read方法签名中证明这点:
/** * Read messages from the log. * * @param startOffset The offset to begin reading at * @param maxLength The maximum number of bytes to read * @param maxOffset The offset to read up to, exclusive. (i.e. this offset NOT included in the resulting message set) <==== 注意这行!!! * @param minOneMessage If this is true, the first message will be returned even if it exceeds `maxLength` (if one exists) * @param isolationLevel The isolation level of the fetcher. The READ_UNCOMMITTED isolation level has the traditional * read semantics (e.g. consumers are limited to fetching up to the high watermark). In * READ_COMMITTED, consumers are limited to fetching up to the last stable offset. Additionally, * in READ_COMMITTED, the transaction index is consulted after fetching to collect the list * of aborted transactions in the fetch range which the consumer uses to filter the fetched * records before they are returned to the user. Note that fetches from followers always use * READ_UNCOMMITTED. * @throws OffsetOutOfRangeException If startOffset is beyond the log end offset or before the log start offset * @return The fetch data information including fetch starting offset metadata and messages read. */ def read(startOffset: Long, maxLength: Int, maxOffset: Option[Long] = None, minOneMessage: Boolean = false, isolationLevel: IsolationLevel): FetchDataInfo = {
...
}
参数maxOffset是exclusive的,也就是说这个位移上的消息是不会被读取的。下面这段代码证明了在实际调用过程中read的maxOffset也是传入的HW值:
def read(tp: TopicPartition, fetchInfo: PartitionData, limitBytes: Int, minOneMessage: Boolean): LogReadResult = {
......
val initialHighWatermark = localReplica.highWatermark.messageOffset // <==== 注意这行!
......
val maxOffsetOpt = if (readOnlyCommitted) // follower拉取消息一定拉取committed的
Some(lastStableOffset.getOrElse(initialHighWatermark))
else
None
......
val fetch = log.read(offset, adjustedFetchSize, maxOffsetOpt, minOneMessage, isolationLevel)
......
}
不过LogSegment.scala的read方法并未严格实现这一点,貌似又支持读取offset=HW值的消息,如下所示:
def read(startOffset: Long, maxOffset: Option[Long], maxSize: Int, maxPosition: Long = size,
minOneMessage: Boolean = false): FetchDataInfo = {
......
val fetchSize: Int = maxOffset match {
case None =>
// no max offset, just read until the max position
min((maxPosition - startPosition).toInt, adjustedMaxSize)
case Some(offset) =>
if (offset < startOffset) // 并未比较相等的情况,也就是说startOffset = HW值的话也可继续读取数据
return FetchDataInfo(offsetMetadata, MemoryRecords.EMPTY, firstEntryIncomplete = false)
val mapping = translateOffset(offset, startPosition)
......
}
......
}
虽然在后面代码中加入了HW位移值对应物理文件位置是否真实存在的判断逻辑,但毕竟做了一次物理文件位置的转换操作(调用LogSegment#translateOffset),应该说是做了一些无用功的——后续我可能会提一个jira跟社区讨论一下此事,不过目前我们还是先认定HW值处的消息是不能被消费的。
在讨论HW、LEO工作原理的时候,下面这张图能够很好地解释leader副本对象和follower副本对象的主要区别:
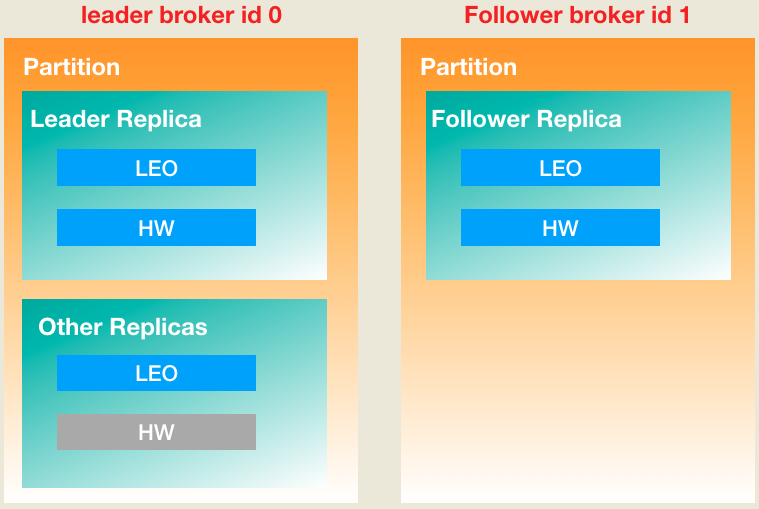
如前所述,所有的副本对象都保存在分区Partition对象的一个列表中。为了区别leader副本和follower副本,上图中我还是把它们拆开分别表示,这样会更加清晰一些。图中灰色字段表示不会被更新,也就是说leader Replica对象是不会更新remote HW值的(这里的remote含义与remote LEO相同)。有了这些概念我们现在可以讨论更新时机的问题了:
一、上图右边的follower Replica对象何时更新LEO?
Follower副本使用专属线程不断地向leader副本所在broker发送FETCH请求,然后leader发送FETCH response给follower。Follower拿到response之后取出里面的数据写入到本地底层日志中,在该过程中其LEO值会被更新。
二、上图左边的leader Replica对象何时更新LEO?
和follower Replica更新LEO道理相同,leader写底层日志时就会自动地更新它的LEO值。对于leader来说何时会写底层日志呢?最容易想到的一个场景就是producer生产消息时。由此可见,不管是在leader端还是在 follower端,只有写入本地底层日志时才会触发对本地Replica对象上LEO值的更新。
三、上图左下的Other Replicas何时更新LEO?
首先思考一下为什么leader Partition对象需要保存所有Replica副本的LEO?事实上,它们的主要作用是帮助leader Replica对象确定其HW值之用,而由于leader Replica的HW值就是整个分区的HW值,故这些other Replicas实际上是用来确定分区HW值的。Other Replicas LEO值是在leader端broker处理FETCH请求过程中被更新的。当follower发送一个FETCH请求时,它会告诉leader要从那个位移值开始读取,即FetchRequest中的fetchOffset字段。leader端在更新Other Replicas的LEO时会将其更新成这个fetchOffset值。
四、上图右上的follower Replica对象何时更新HW?
Follower Replica对象更新HW是在其更新本地LEO之后。一旦follower向本地日志写完数据后它就会尝试更新其HW值。具体算法是取本地LEO与FETCH response中HW值的较小值,因此follower Replica的HW值不会大于其本地LEO值。
五、上图左上的leader Replica对象何时更新HW?
前面说过了, leader Replica的HW值实际上就是分区的HW值,因此何时更新该值才是我们最关心的,因为它将直接影响分区数据对于consumer的可见性。以下4种情况Kafka会尝试去更新leader Replica对象的HW值:
- 该Replica成为leader Replica时:当某个Replica成为分区的leader副本后,Kafka会尝试去更新其HW值
- Broker崩溃导致副本被踢出ISR时:此时Kafka会执行ISR的缩减操作,故必须要检查下分区HW值是否需要更新
- Producer向leader Replica写入消息时:写入消息会更新leader Replica的LEO,故有必要检查下其HW值是否需要修改
- Leader Replica处理FETCH请求时:Leader Replica处理FETCH请求时在更新完Other Replicas的LEO后会尝试更新其HW值
上面的条件揭示了一个重要的事实:如果没有出现broker failure或leader变更等情形,分区HW值更新时机只可能有两个:1. leader broker处理PRODUCE请求;2. leader broker处理FETCH请求。Leader Replica HW值变更的算法很简单:首先找出leader Partition对象保存的所有与leader Replica保持同步的Replica对象(leader Replica + other Replicas)的LEO值,然后选择其中航最小的LEO值作为分区HW值。这里的同步判断条件有两个:
- 该副本在ISR中
- 该副本LEO落后于leader Replica LEO的时间≤ replica.lag.time.max.ms
乍看上去好像这两个条件说的是一回事,毕竟ISR的定义就是第二个条件描述的那样。但在某些情况下Kafka的确可能出现follower副本已经“追上”了leader的进度,但却不在ISR中——比如某个从failure中恢复的副本。如果Kafka只判断第一个条件的话,确定分区HW值时就不会考虑这些未在ISR中的副本,但这些副本已经具备了“立刻进入ISR”的资格,因此就可能出现分区HW值越过ISR中副本LEO的情况——这肯定是不允许的,因为超过ISR副本LEO的那些消息属于未提交消息。
在举实际例子之前,我们先确认一下这些更新步骤的顺序。首先是处理PRODUCE请求的逻辑顺序:

之后是leader端broker处理FETCH请求:

最后是follower端broker处理FETCH response:

下面举个一个实际的例子,该例子中的topic是单分区,副本因子是2。我们首先看下当producer发送一条消息时,leader/follower端broker的副本对象到底会发生什么事情以及分区HW是如何被更新的。首先是初始状态:

此时producer给该topic分区发送了一条消息。此时的状态如下图所示:
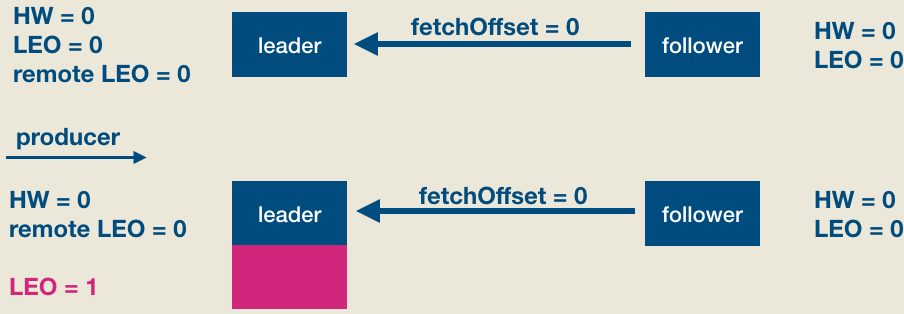
如上图所见,producer发送消息成功后(假设acks=1, leader成功写入即返回),follower发来了新的FECTH请求,依然请求fetchOffset = 0的数据。和上次不同的是,这次是有数据可以读取的,因此整个处理流程如下图:
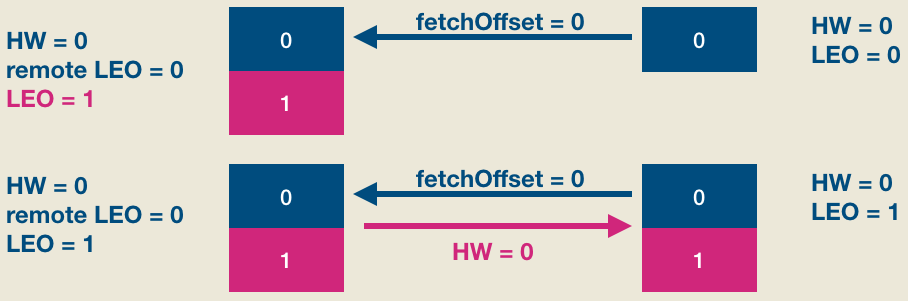
显然,现在leader和follower都保存了位移是0的这条消息,但两边的HW值都没有被更新,它们需要在下一轮FETCH请求处理中被更新,如下图所示:
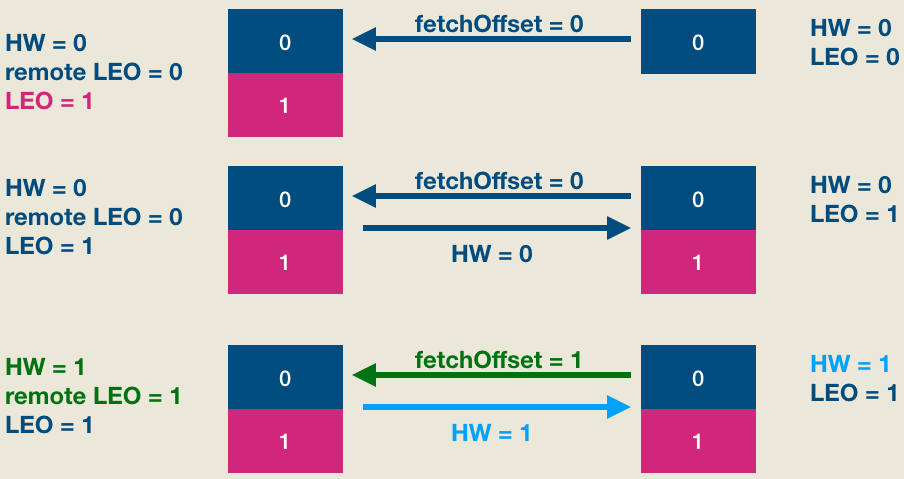
简单解释一下, 第二轮FETCH请求中,follower发送fetchOffset = 1的FETCH请求——因为fetchOffset = 0的消息已经成功写入follower本地日志了,所以这次请求fetchOffset = 1的数据了。Leader端broker接收到FETCH请求后首先会更新other replicas中的LEO值,即将remote LEO更新成1,然后更新分区HW值为1——具体的更新规则参见上面的解释。做完这些之后将当前分区HW值(1)封装进FETCH response发送给follower。Follower端broker接收到FETCH response之后从中提取出当前分区HW值1,然后与自己的LEO值比较,从而将自己的HW值更新成1,至此完整的HW、LEO更新周期结束。
由上面的分析可知,两边HW值的更新是在后面一轮(如果有多个follower副本,也许是多轮)FETCH请求处理中完成的,这种“时间”上的错配也是导致出现各种“数据丢失”或“数据不一致”的原因。基于此社区才引入了leader epoch机制试图规避因使用HW而带来的这个问题。不过本文并不关注leader epoch,只是单纯希望我能把HW、LEO这件事情讲明白。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号