scrapy实战5 POST方法抓取ajax动态页面(以慕课网APP为例子):
在手机端打开慕课网,fiddler查看如图注意圈起来的位置
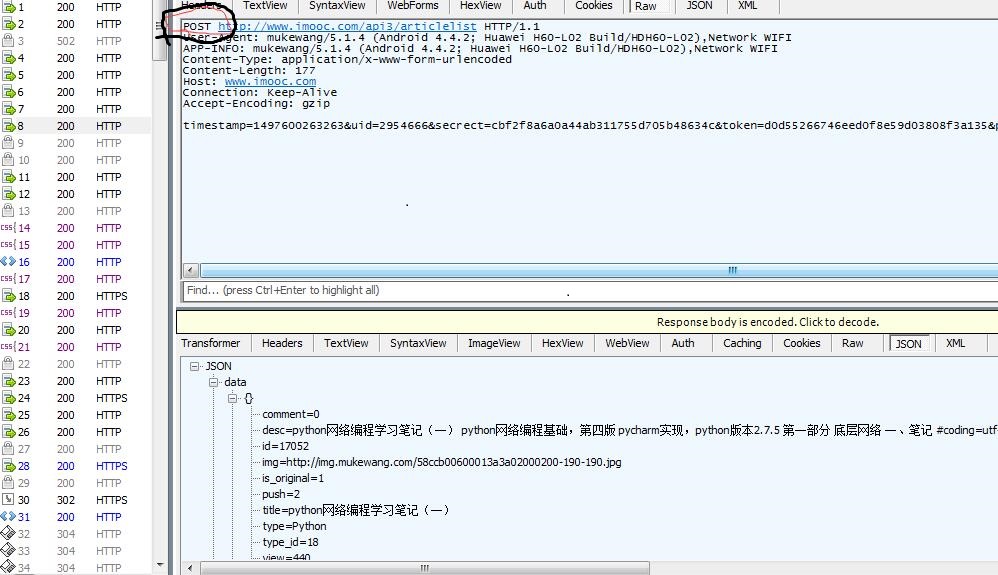
经过分析只有画线的page在变化

上代码:
items.py


1 import scrapy 2 3 4 class ImoocItem(scrapy.Item): 5 # define the fields for your item here like: 6 # name = scrapy.Field() 7 #id 8 id=scrapy.Field() 9 #标题 10 title=scrapy.Field() 11 #类别 12 tag=scrapy.Field() 13 #内容 14 content=scrapy.Field() 15 #爬取时间 16 crawl_time=scrapy.Field()
spiders/IMooc.py
1 # -*- coding: utf-8 -*- 2 import scrapy 3 from scrapy.linkextractors import LinkExtractor 4 from scrapy.spiders import CrawlSpider, Rule 5 import json 6 from imooc.items import ImoocItem 7 from datetime import datetime 8 9 from scrapy.http import FormRequest 10 class ImoocSpider(scrapy.Spider): 11 name = 'IMooc' 12 allowed_domains = ['www.imooc.com'] 13 headers={ 14 "User - Agent":"mukewang/5.1.4 (Android 4.4.2; Huawei H60-L02 Build/HDH60-L02),Network WIFI", 15 "APP-INFO":"mukewang/5.1.4 (Android 4.4.2; Huawei H60-L02 Build/HDH60-L02),Network WIFI", 16 "Host":"www.imooc.com", 17 "Connection":"Keep-Alive", 18 "Content-Type":"application/x-www-form-urlencoded" 19 } 20 def start_requests(self): 21 url="http://www.imooc.com/api3/articlelist" 22 requests = [] 23 for i in range(1,60): 24 formdata={ 25 "typeid":"18", 26 "page":str(i), 27 } 28 request = FormRequest(url, callback=self.parse_item, formdata=formdata,headers=self.headers) 29 requests.append(request) 30 return requests 31 def parse_item(self, response): 32 datas=json.loads(response.text)["data"] 33 for data in datas: 34 item=ImoocItem() 35 item["id"]=data["id"] 36 item["title"]=data["title"] 37 item["tag"]=data["type"] 38 item["content"]=data["desc"] 39 item["crawl_time"]=datetime.now() 40 yield item
pipelines.py
1 import pymysql 2 class ImoocPipeline(object): 3 def process_item(self, item, spider): 4 con = pymysql.connect(host="127.0.0.1", user="youusername", passwd="youpassword", db="imooc", charset="utf8") 5 cur = con.cursor() 6 sql = ("insert into imooc_shouji(id,title,tag,content,crawl_time)" 7 "VALUES(%s,%s,%s,%s,%s)") 8 lis = (item["id"],item["title"],item["tag"],item["content"],item["crawl_time"]) 9 cur.execute(sql, lis) 10 con.commit() 11 cur.close() 12 con.close() 13 return item
settings.py
1 BOT_NAME = 'imooc' 2 3 SPIDER_MODULES = ['imooc.spiders'] 4 NEWSPIDER_MODULE = 'imooc.spiders' 5 ROBOTSTXT_OBEY = False 6 DOWNLOAD_DELAY = 5 7 ITEM_PIPELINES = { 8 'imooc.pipelines.ImoocPipeline': 300, 9 }
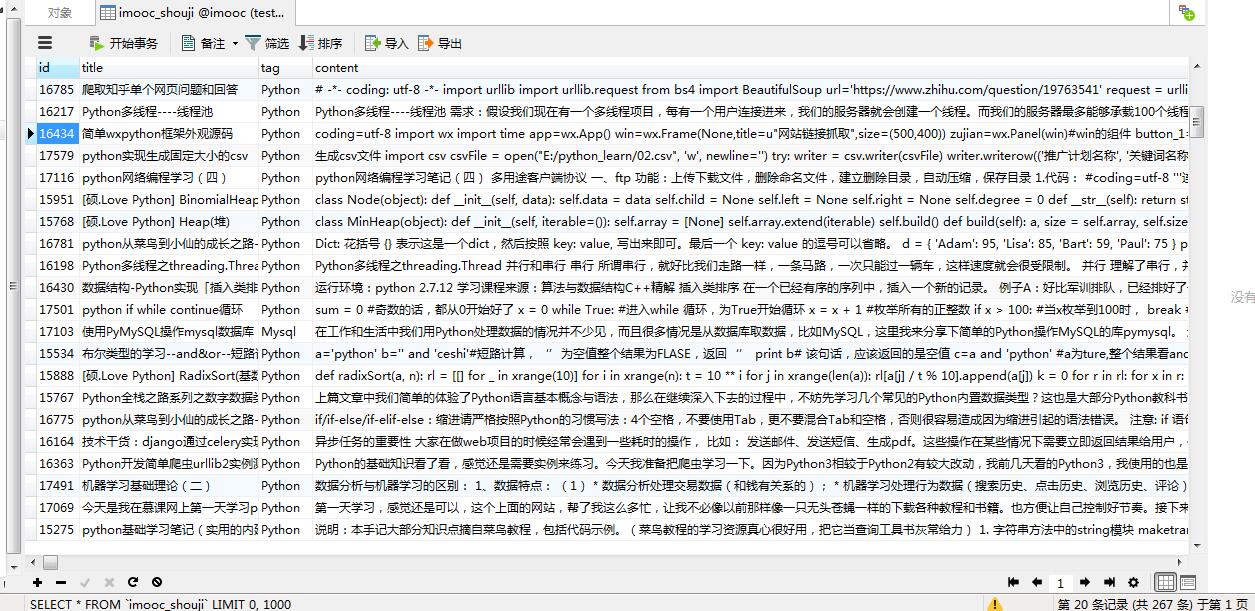
只爬取python相关的手记如下图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号