
深度学习应用系列(三)| autokeras使用入门
我们在构建自己的神经网络模型时,往往会基于预编译模型上进行迁移学习。但不同的训练数据、不同的场景下,各个模型表现不一,需要投入大量的精力进行调参,耗费相当多的时间才能得到自己满意的模型。
而谷歌近期推出了AutoML,可以帮助人们在给定数据下自动找寻最优网络模型,可谓让不是专业的人也可以轻松构建合适自己的网络模型,但唯一的问题是太贵了,每小时收费20美元啦。
幸好开源界也推出了autokeras,让我们一众屌丝也可以享受这免费的待遇,其官网是 https://autokeras.com/ 。
官网的文档和样例目前不是很详细,我研究了一番,写篇简单的入门贴,供大家参考。
一、 准备数据
先下载训练和测试数据集,下载地址为 http://pan.baidu.com/s/1nuqlTnN,总共500张图片,其中100张为测试数据,400张为训练数据,图片分为'bus', 'dinosaur', 'flower', 'horse', 'elephant'五类,分别以以3,4,5,6,7开头进行按类区分
按照autokers的要求,我们需要做一个csv文件,记录图片与所属标签的映射关系,可以用如下代码生成:
import os
import csv
TRAIN_IMG_DIR = '/home/yourname/Documents/tensorflow/images/500pics2/train'
TRAIN_CSV_DIR = '/home/yourname/Documents/tensorflow/images/500pics2/train_labels.csv'
TEST_IMG_DIR = '/home/yourname/Documents/tensorflow/images/500pics2/test'
TEST_CSV_DIR = '/home/yourname/Documents/tensorflow/images/500pics2/test_labels.csv'
def mkcsv(img_dir, csv_dir):
list = []
list.append(['File Name','Label'])
for file_name in os.listdir(img_dir):
if file_name[0] == '3': #bus
item = [file_name, 0]
elif file_name[0] == '4': #dinosaur
item = [file_name, 1]
elif file_name[0] == '5': #elephant
item = [file_name, 2]
elif file_name[0] == '6': #flower
item = [file_name, 3]
else:
item = [file_name, 4] #horse
list.append(item)
print(list)
f = open(csv_dir, 'w', newline='')
writer = csv.writer(f)
writer.writerows(list)
mkcsv(TRAIN_IMG_DIR, TRAIN_CSV_DIR)
mkcsv(TEST_IMG_DIR, TEST_CSV_DIR)
最后生成的csv文件的格式是这样:
File Name,Label 473.jpg,1 675.jpg,3 556.jpg,2 584.jpg,2 339.jpg,0
二、 格式化图片
训练和测试图片的大小不一,需要统一转换成相同的格式才能被autokeras处理,可用如下代码处理:
from tensorflow.keras.preprocessing import image import os TEST_IMG_DIR_INPUT = "/home/yourname/Documents/tensorflow/images/500pics2/test_origin" TEST_IMG_DIR_OUTPUT = "/home/yourname/Documents/tensorflow/images/500pics2/test" TRAIN_IMG_DIR_INPUT = "/home/yourname/Documents/tensorflow/images/500pics2/train_origin" TRAIN_IMG_DIR_OUTPUT = "/home/yourname/Documents/tensorflow/images/500pics2/train" IMAGE_SIZE = 28 def format_img(input_dir, output_dir): for file_name in os.listdir(input_dir): path_name = os.path.join(input_dir, file_name) img = image.load_img(path_name, target_size=(IMAGE_SIZE, IMAGE_SIZE)) path_name = os.path.join(output_dir, file_name) img.save(path_name) format_img(TEST_IMG_DIR_INPUT, TEST_IMG_DIR_OUTPUT) format_img(TRAIN_IMG_DIR_INPUT, TRAIN_IMG_DIR_OUTPUT)
本例中我们把图片大小统一转换成(28, 28)的格式,为什么是这个值呢?我最初尝试设置成224*224,但发现后来运行autokeras时,抛出了"RuntimeError: CUDA error: out of memory"的错误,autokeras是基于pyTorch,我觉得pyTorch对于内存的利用上需要优化下,同样的数据集我在基于tensorflow的keras上是不会报内存不足的。不过也许你的内存足够大的话,可以忽略我的建议。
三、 训练
首先我们需要安装autokeras:pip3 install autokeras
其次需要安装graphviz: apt install graphviz,目的是为了最后能画出我们生成的模型
以下是训练代码:
from autokeras.image.image_supervised import load_image_dataset, ImageClassifier
from keras.models import load_model
from keras.utils import plot_model
from keras.preprocessing.image import load_img, img_to_array
import numpy as np
TRAIN_CSV_DIR = '/home/yourname/Documents/tensorflow/images/500pics2/train_labels.csv'
TRAIN_IMG_DIR = '/home/yourname/Documents/tensorflow/images/500pics2/train'
TEST_CSV_DIR = '/home/yourname/Documents/tensorflow/images/500pics2/test_labels.csv'
TEST_IMG_DIR = '/home/yourname/Documents/tensorflow/images/500pics2/test'
PREDICT_IMG_PATH = '/home/yourname/Documents/tensorflow/images/500pics2/test/719.jpg'
MODEL_DIR = '/home/yourname/Documents/tensorflow/images/500pics2/model/my_model.h5'
MODEL_PNG = '/home/yourname/Documents/tensorflow/images/500pics2/model/model.png'
IMAGE_SIZE = 28
if __name__ == '__main__':
# 获取本地图片,转换成numpy格式
train_data, train_labels = load_image_dataset(csv_file_path=TRAIN_CSV_DIR, images_path=TRAIN_IMG_DIR)
test_data, test_labels = load_image_dataset(csv_file_path=TEST_CSV_DIR, images_path=TEST_IMG_DIR)
# 数据进行格式转换
train_data = train_data.astype('float32') / 255
test_data = test_data.astype('float32') / 255
print("train data shape:", train_data.shape)
# 使用图片识别器
clf = ImageClassifier(verbose=True)
# 给其训练数据和标签,训练的最长时间可以设定,假设为1分钟,autokers会不断找寻最优的网络模型
clf.fit(train_data, train_labels, time_limit=1 * 60)
# 找到最优模型后,再最后进行一次训练和验证
clf.final_fit(train_data, train_labels, test_data, test_labels, retrain=True)
# 给出评估结果
y = clf.evaluate(test_data, test_labels)
print("evaluate:", y)
# 给一个图片试试预测是否准确
img = load_img(PREDICT_IMG_PATH)
x = img_to_array(img)
x = x.astype('float32') / 255
x = np.reshape(x, (1, IMAGE_SIZE, IMAGE_SIZE, 3))
print("x shape:", x.shape)
# 最后的结果是一个numpy数组,里面是预测值4,意味着是马,说明预测准确
y = clf.predict(x)
print("predict:", y)
# 导出我们生成的模型
clf.export_keras_model(MODEL_DIR)
# 加载模型
model = load_model(MODEL_DIR)
# 将模型导出成可视化图片
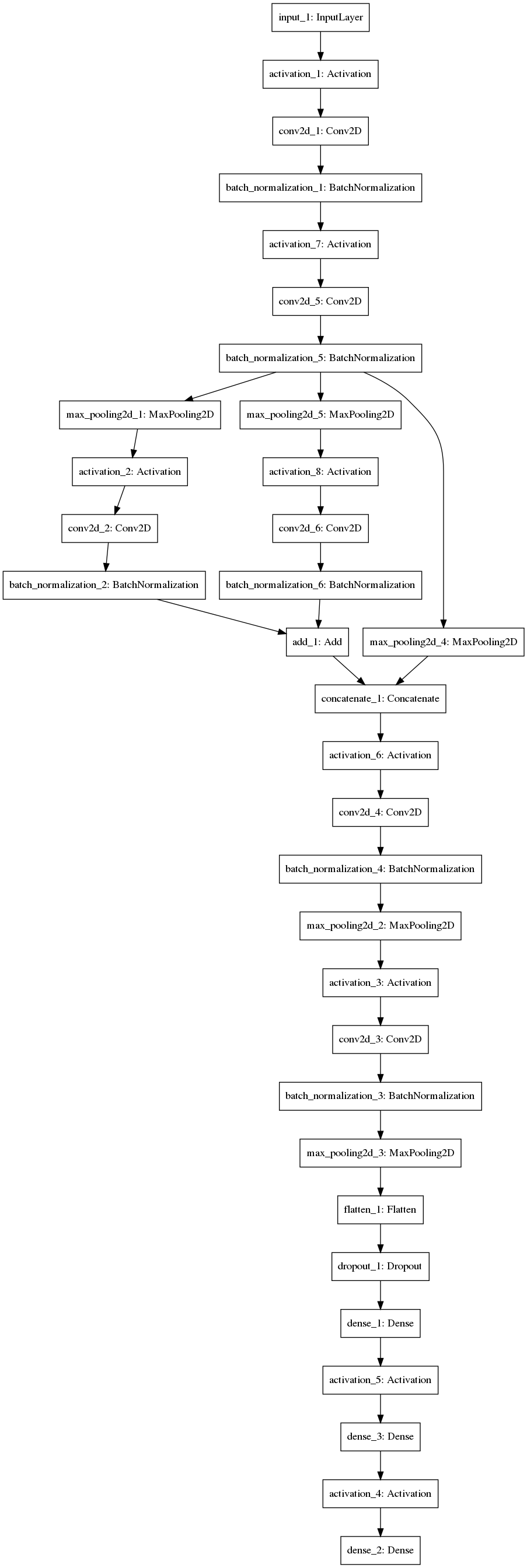
plot_model(model, to_file=MODEL_PNG)
最后给出生成的模型样子,也许这个模型比不上你手工调参得来的模型高效,但这已经是autokeras给出的最优解了,而且我们不需要劳神劳力的去调参了。
人生苦短,我用autokers!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号