

seata 解决分布式事务
Seata 是 阿里巴巴2019年开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务。在 Seata 开源之前,Seata 对应的内部版本在阿里内部一直扮演着分布式一致性中间件的角色,帮助阿里度过历年的双11,对各业务进行了有力的支撑。经过多年沉淀与积累,2019.1 Seata 正式宣布对外开源 。目前 Seata 1.0 已经 GA。
微服务中的分布式事务问题
让我们想象一下传统的单片应用程序,它的业务由3个模块组成,他们使用单个本地数据源。自然,本地事务将保证数据的一致性。
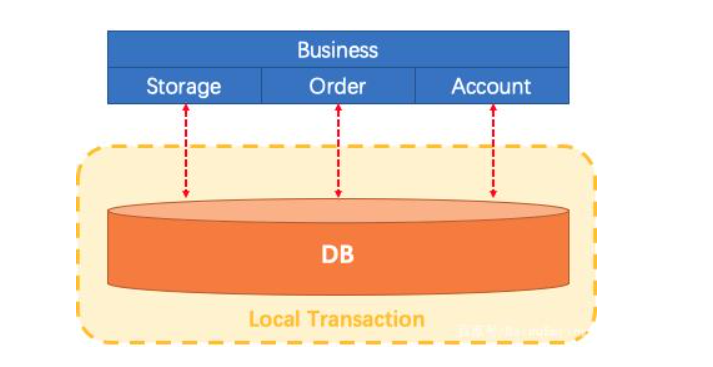
微服务架构已发生了变化。上面提到的3个模块被设计为3种服务。本地事务自然可以保证每个服务中的数据一致性。但是整个业务逻辑范围如何?
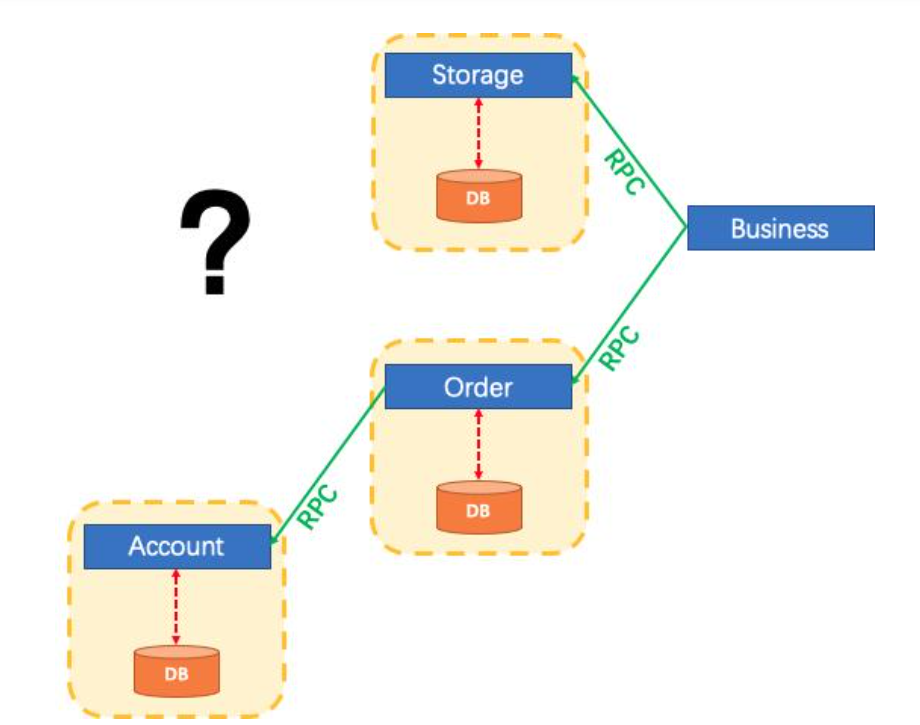
Seata怎么办?
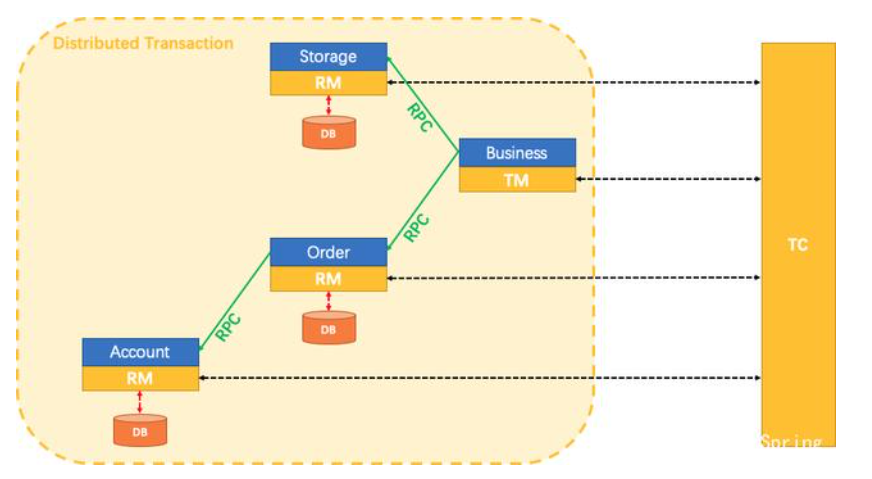
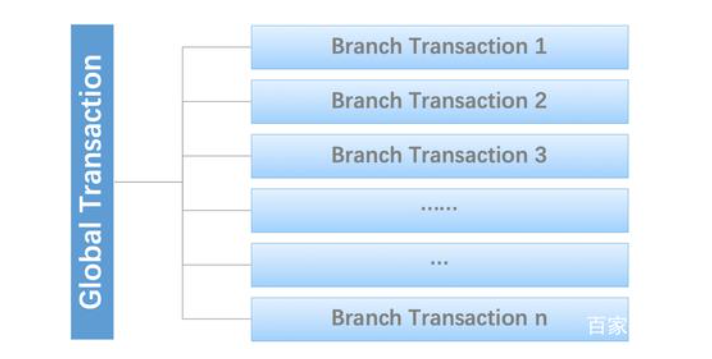
我们说,分布式事务是由一批分支事务组成的全局事务,通常分支事务只是本地事务。
Seata有3个基本组成部分:
事务协调器(TC):维护全局事务和分支事务的状态,驱动全局提交或回滚。
事务管理器TM:定义全局事务的范围:开始全局事务,提交或回滚全局事务。
资源管理器(RM):管理正在处理的分支事务的资源,与TC对话以注册分支事务并报告分支事务的状态,并驱动分支事务的提交或回滚
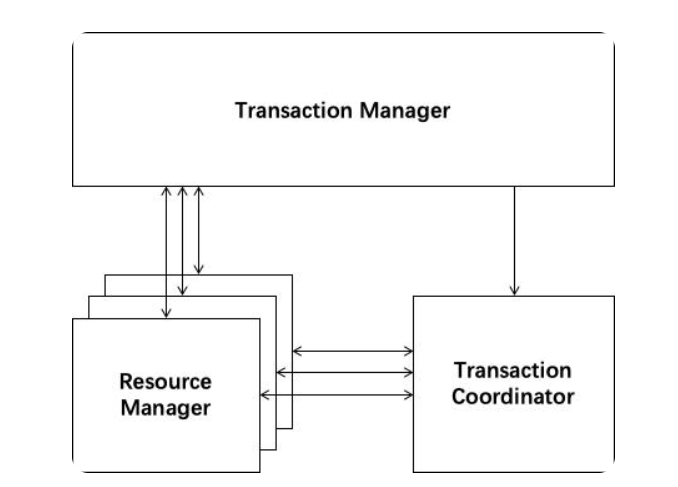
Seata管理的分布式事务的典型生命周期:
TM要求TC开始一项新的全局事务。
TC生成代表全局事务的XID。
XID通过微服务的调用链传播。
RM将本地事务注册为XID到TC的相应全局事务的分支。
TM要求TC提交或回退相应的XID全局事务。
TC驱动XID的相应全局事务下的所有分支事务以完成分支提交或回滚。
分布式事务 Seata 及其三种模式详解:
《分布式事务 Seata 及其三种模式详解》主题分享整理,着重分享分布式事务产生的背景、理论基础,以及 Seata 分布式事务的原理以及三种模式(AT、TCC、Saga)的分布式事务实现。
一、分布式事务产生的背景
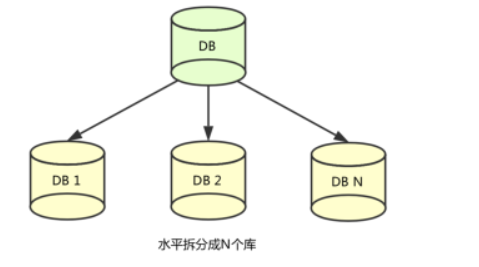
1.1 分布式架构演进之 - 数据库的水平拆分
蚂蚁金服的业务数据库起初是单库单表,但随着业务数据规模的快速发展,数据量越来越大,单库单表逐渐成为瓶颈。所以我们对数据库进行了水平拆分,将原单库单表拆分成数据库分片。
如下图所示,分库分表之后,原来在一个数据库上就能完成的写操作,可能就会跨多个数据库,这就产生了跨数据库事务问题。
1.2 分布式架构演进之 - 业务服务化拆分
在业务发展初期,“一块大饼”的单业务系统架构,能满足基本的业务需求。但是随着业务的快速发展,系统的访问量和业务复杂程度都在快速增长,单系统架构逐渐成为业务发展瓶颈,解决业务系统的高耦合、可伸缩问题的需求越来越强烈。
如下图所示,蚂蚁金服按照面向服务架构(SOA)的设计原则,将单业务系统拆分成多个业务系统,降低了各系统之间的耦合度,使不同的业务系统专注于自身业务,更有利于业务的发展和系统容量的伸缩。
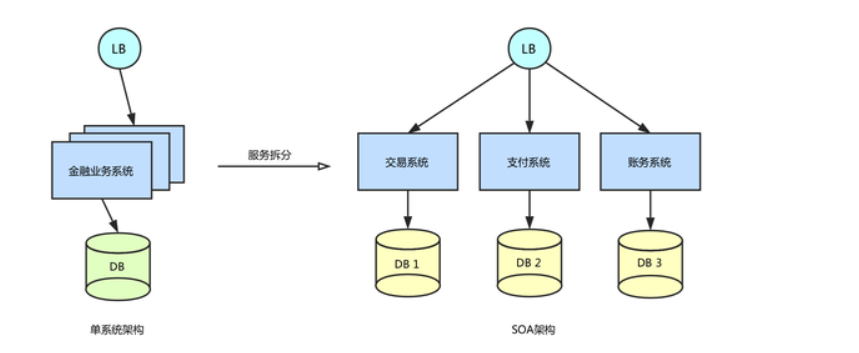
业务系统按照服务拆分之后,一个完整的业务往往需要调用多个服务,如何保证多个服务间的数据一致性成为一个难题。
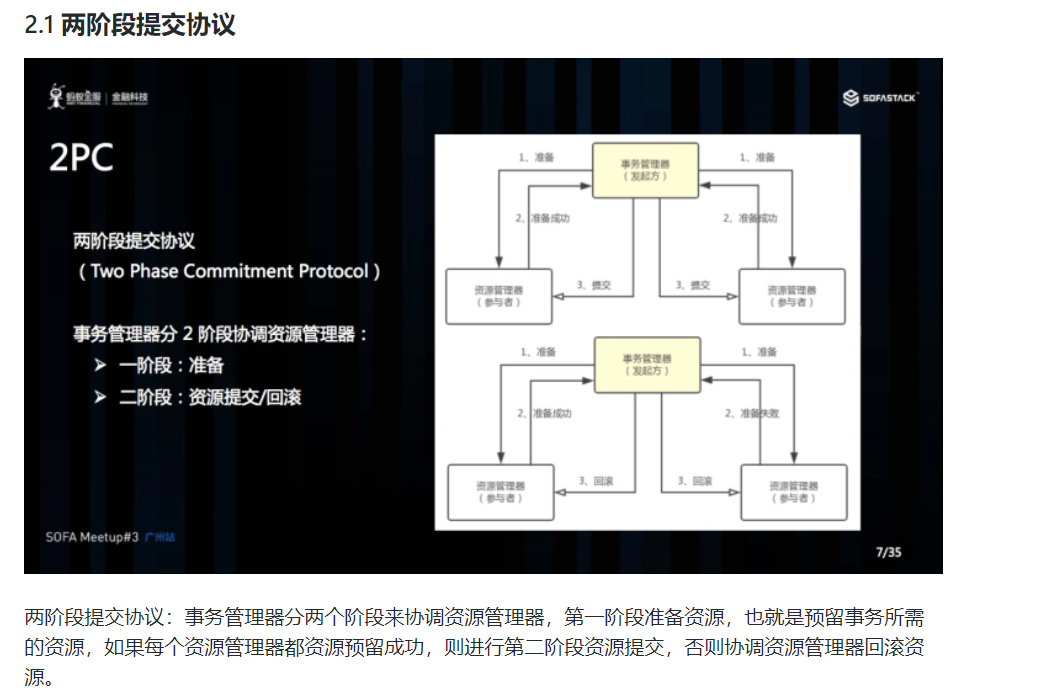
二、分布式事务理论基础
三、Seata 及其三种模式详解
3.1 分布式事务 Seata 介绍
Seata(Simple Extensible Autonomous Transaction Architecture,简单可扩展自治事务框架)是 2019 年 1 月份蚂蚁金服和阿里巴巴共同开源的分布式事务解决方案。Seata 开源半年左右,目前已经有超过 1.1 万 star,社区非常活跃。我们热忱欢迎大家参与到 Seata 社区建设中,一同将 Seata 打造成开源分布式事务标杆产品。
Seata:https://github.com/seata/seata
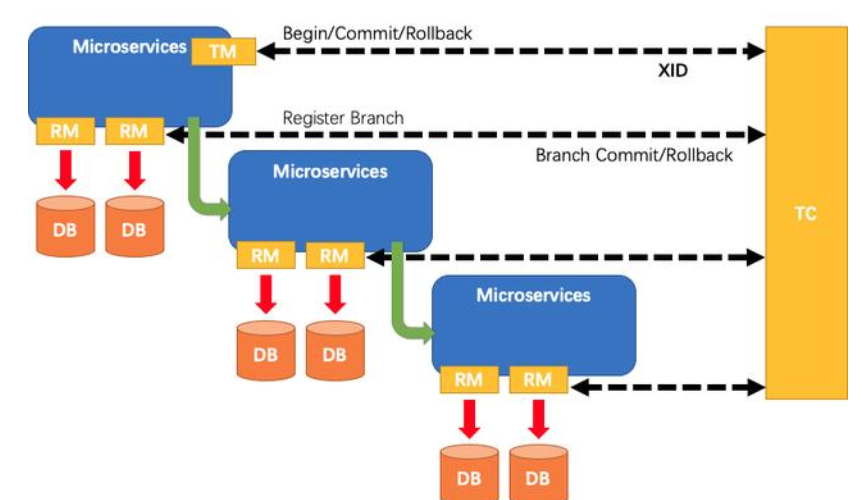
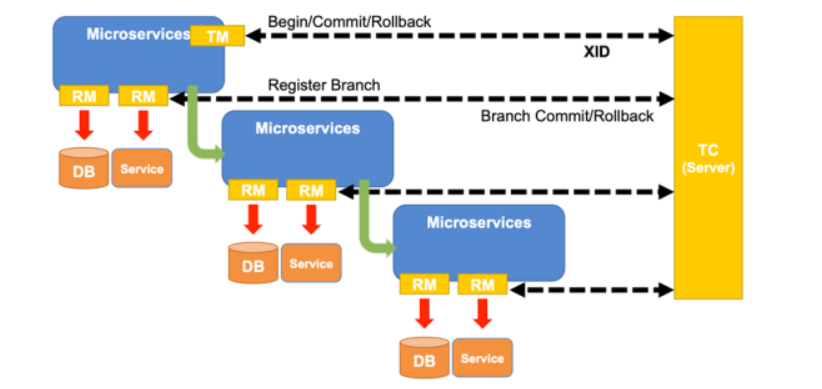
3.2 分布式事务 Seata 产品模块
如下图所示,Seata 中有三大模块,分别是 TM、RM 和 TC。 其中 TM 和 RM 是作为 Seata 的客户端与业务系统集成在一起,TC 作为 Seata 的服务端独立部署。
在 Seata 中,分布式事务的执行流程:
- TM 开启分布式事务(TM 向 TC 注册全局事务记录);
- 按业务场景,编排数据库、服务等事务内资源(RM 向 TC 汇报资源准备状态 );
- TM 结束分布式事务,事务一阶段结束(TM 通知 TC 提交/回滚分布式事务);
- TC 汇总事务信息,决定分布式事务是提交还是回滚;
- TC 通知所有 RM 提交/回滚 资源,事务二阶段结束;
3.3 分布式事务 Seata 解决方案
Seata 会有 4 种分布式事务解决方案,分别是 AT 模式、TCC 模式、Saga 模式和 XA 模式。
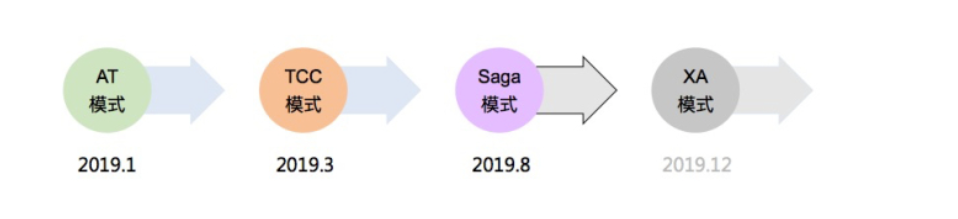
2.3.1 AT 模式
今年 1 月份,Seata 开源了 AT 模式。AT 模式是一种无侵入的分布式事务解决方案。在 AT 模式下,用户只需关注自己的“业务 SQL”,用户的 “业务 SQL” 作为一阶段,Seata 框架会自动生成事务的二阶段提交和回滚操作。
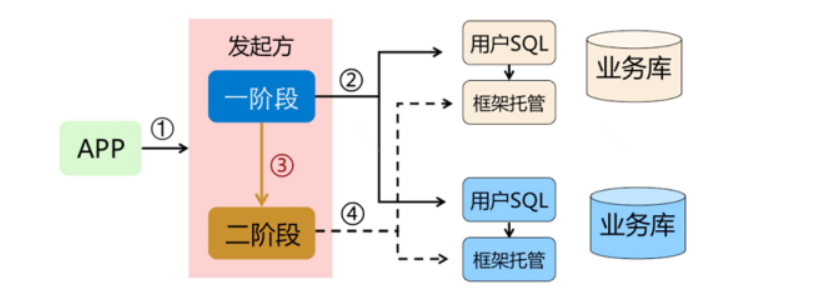
AT 模式如何做到对业务的无侵入 :
- 一阶段:
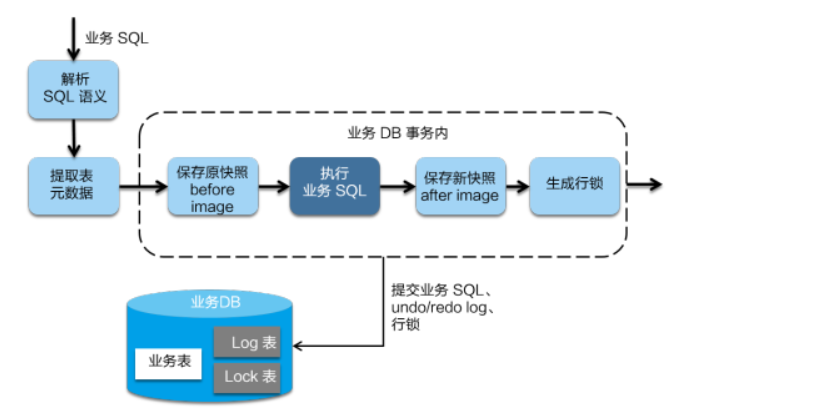
在一阶段,Seata 会拦截“业务 SQL”,首先解析 SQL 语义,找到“业务 SQL”要更新的业务数据,在业务数据被更新前,将其保存成“before image”,然后执行“业务 SQL”更新业务数据,在业务数据更新之后,再将其保存成“after image”,最后生成行锁。以上操作全部在一个数据库事务内完成,这样保证了一阶段操作的原子性。
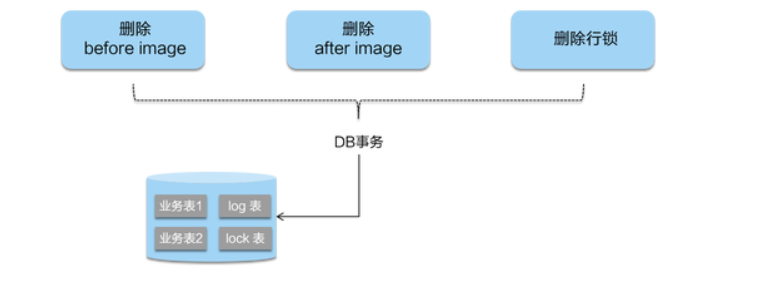
- 二阶段提交:
二阶段如果是提交的话,因为“业务 SQL”在一阶段已经提交至数据库, 所以 Seata 框架只需将一阶段保存的快照数据和行锁删掉,完成数据清理即可。
- 二阶段回滚:
二阶段如果是回滚的话,Seata 就需要回滚一阶段已经执行的“业务 SQL”,还原业务数据。回滚方式便是用“before image”还原业务数据;但在还原前要首先要校验脏写,对比“数据库当前业务数据”和 “after image”,如果两份数据完全一致就说明没有脏写,可以还原业务数据,如果不一致就说明有脏写,出现脏写就需要转人工处理。
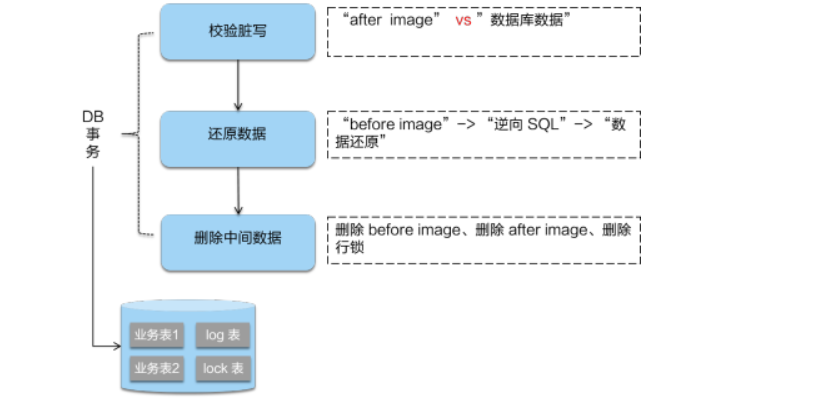
AT 模式的一阶段、二阶段提交和回滚均由 Seata 框架自动生成,用户只需编写“业务 SQL”,便能轻松接入分布式事务,AT 模式是一种对业务无任何侵入的分布式事务解决方案。
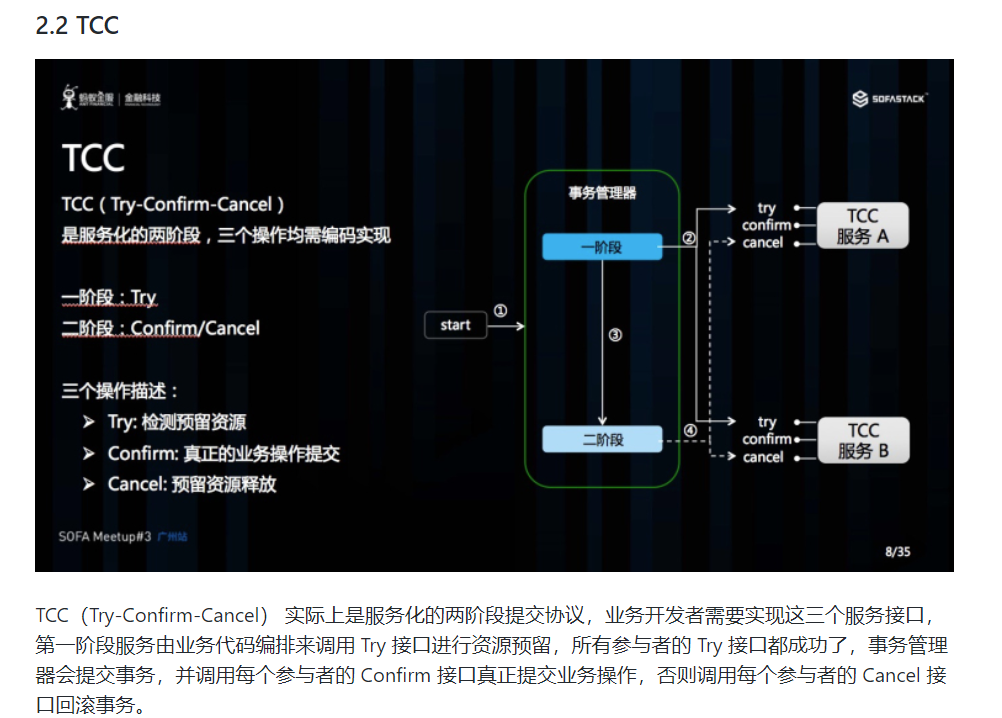
2.3.2 TCC 模式
2019 年 3 月份,Seata 开源了 TCC 模式,该模式由蚂蚁金服贡献。TCC 模式需要用户根据自己的业务场景实现 Try、Confirm 和 Cancel 三个操作;事务发起方在一阶段执行 Try 方式,在二阶段提交执行 Confirm 方法,二阶段回滚执行 Cancel 方法。
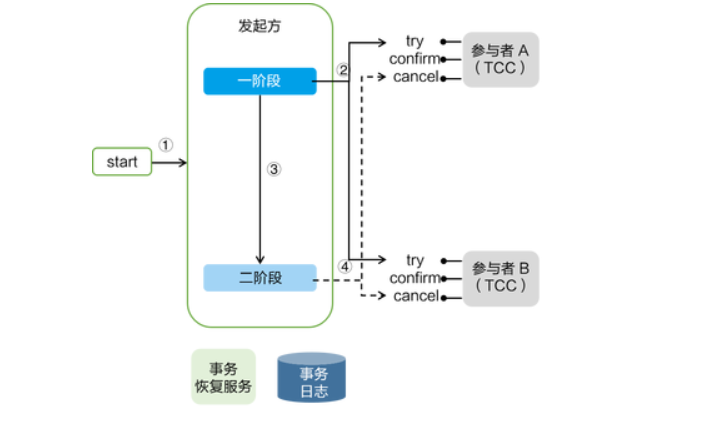
TCC 三个方法描述:
- Try:资源的检测和预留;
- Confirm:执行的业务操作提交;要求 Try 成功 Confirm 一定要能成功;
- Cancel:预留资源释放;

1 TCC 设计 - 业务模型分 2 阶段设计:
用户接入 TCC ,最重要的是考虑如何将自己的业务模型拆成两阶段来实现。
以“扣钱”场景为例,在接入 TCC 前,对 A 账户的扣钱,只需一条更新账户余额的 SQL 便能完成;但是在接入 TCC 之后,用户就需要考虑如何将原来一步就能完成的扣钱操作,拆成两阶段,实现成三个方法,并且保证一阶段 Try 成功的话 二阶段 Confirm 一定能成功。

如上图所示,
Try 方法作为一阶段准备方法,需要做资源的检查和预留。在扣钱场景下,Try 要做的事情是就是检查账户余额是否充足,预留转账资金,预留的方式就是冻结 A 账户的 转账资金。Try 方法执行之后,账号 A 余额虽然还是 100,但是其中 30 元已经被冻结了,不能被其他事务使用。
二阶段 Confirm 方法执行真正的扣钱操作。Confirm 会使用 Try 阶段冻结的资金,执行账号扣款。Confirm 方法执行之后,账号 A 在一阶段中冻结的 30 元已经被扣除,账号 A 余额变成 70 元 。
如果二阶段是回滚的话,就需要在 Cancel 方法内释放一阶段 Try 冻结的 30 元,使账号 A 的回到初始状态,100 元全部可用。
用户接入 TCC 模式,最重要的事情就是考虑如何将业务模型拆成 2 阶段,实现成 TCC 的 3 个方法,并且保证 Try 成功 Confirm 一定能成功。相对于 AT 模式,TCC 模式对业务代码有一定的侵入性,但是 TCC 模式无 AT 模式的全局行锁,TCC 性能会比 AT 模式高很多
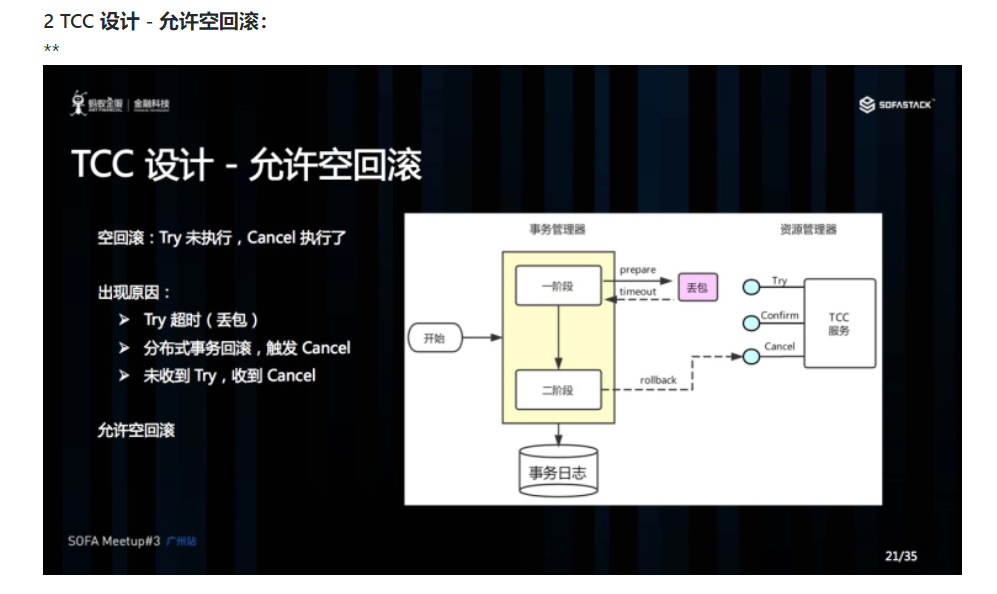
Cancel 接口设计时需要允许空回滚。在 Try 接口因为丢包时没有收到,事务管理器会触发回滚,这时会触发 Cancel 接口,这时 Cancel 执行时发现没有对应的事务 xid 或主键时,需要返回回滚成功。让事务服务管理器认为已回滚,否则会不断重试,而 Cancel 又没有对应的业务数据可以进行回滚。
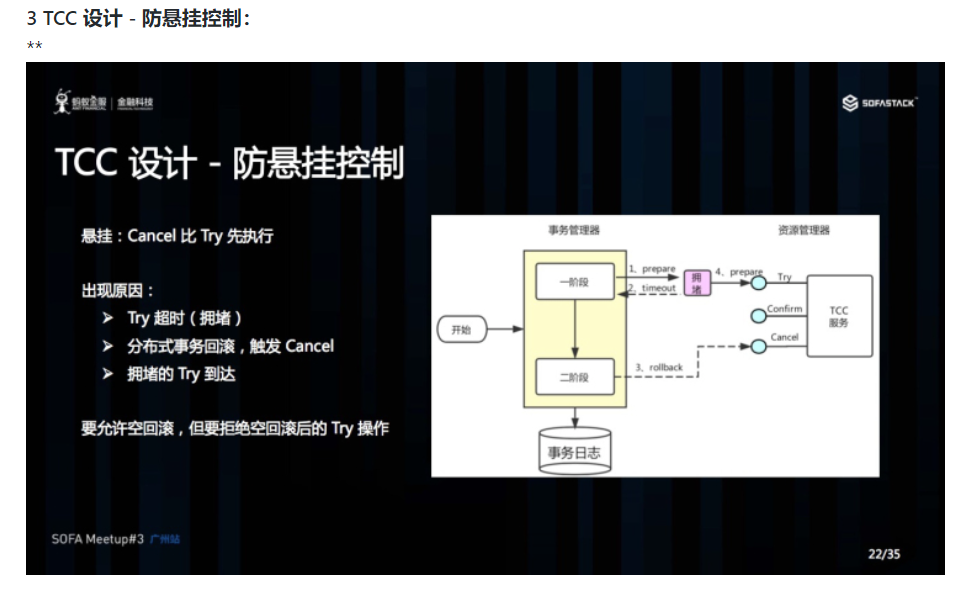
悬挂的意思是:Cancel 比 Try 接口先执行,出现的原因是 Try 由于网络拥堵而超时,事务管理器生成回滚,触发 Cancel 接口,而最终又收到了 Try 接口调用,但是 Cancel 比 Try 先到。按照前面允许空回滚的逻辑,回滚会返回成功,事务管理器认为事务已回滚成功,则此时的 Try 接口不应该执行,否则会产生数据不一致,所以我们在 Cancel 空回滚返回成功之前先记录该条事务 xid 或业务主键,标识这条记录已经回滚过,Try 接口先检查这条事务xid或业务主键如果已经标记为回滚成功过,则不执行 Try 的业务操作。
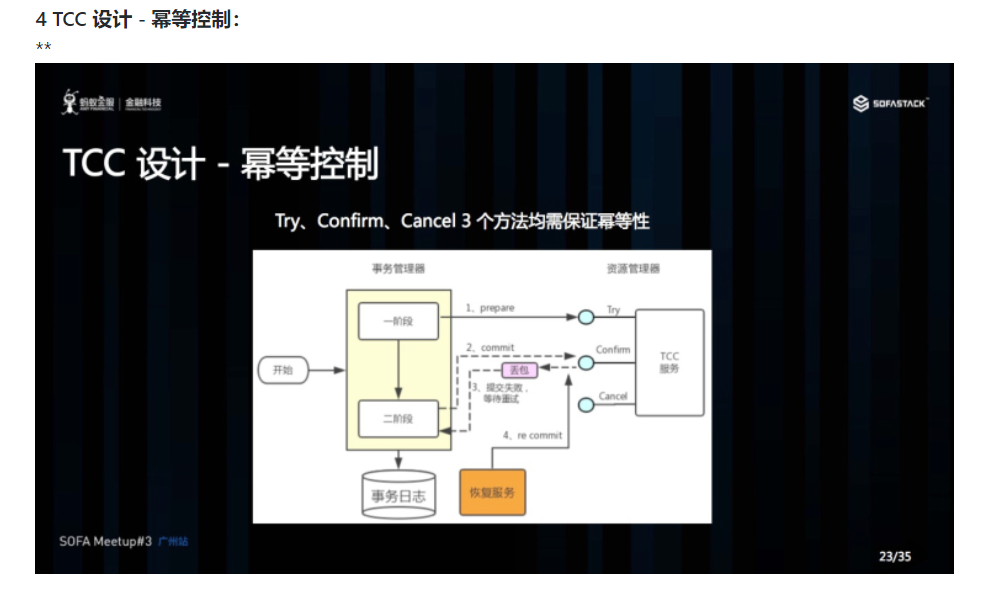
幂等性的意思是:对同一个系统,使用同样的条件,一次请求和重复的多次请求对系统资源的影响是一致的。因为网络抖动或拥堵可能会超时,事务管理器会对资源进行重试操作,所以很可能一个业务操作会被重复调用,为了不因为重复调用而多次占用资源,需要对服务设计时进行幂等控制,通常我们可以用事务 xid 或业务主键判重来控制。
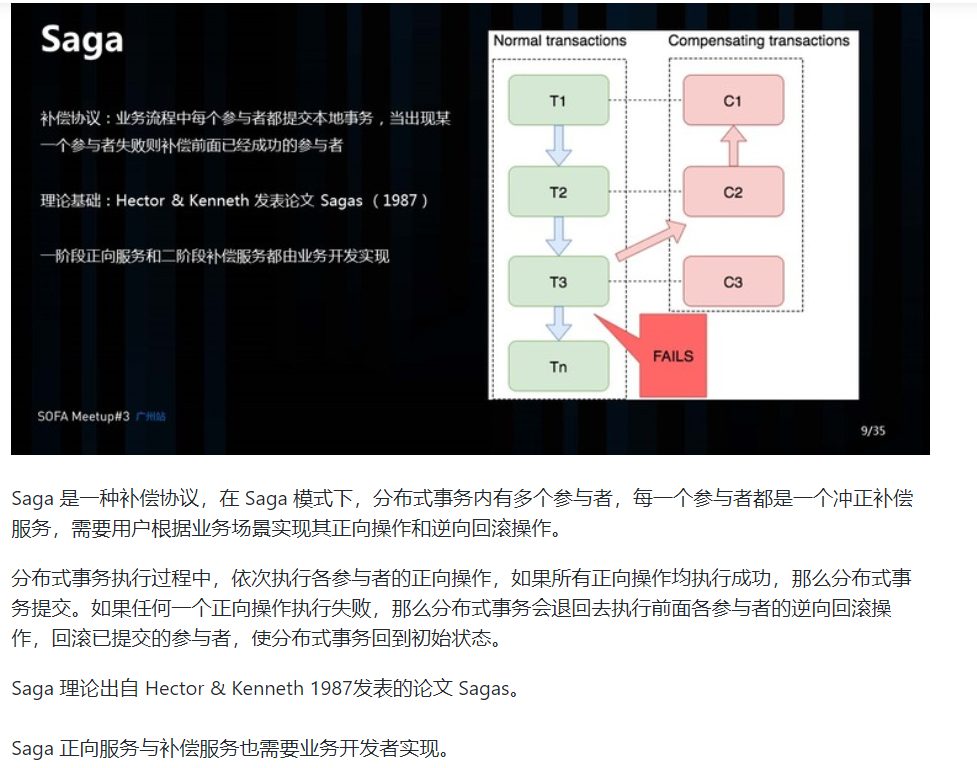
2.3.3 Saga 模式
Saga 模式是 Seata 即将开源的长事务解决方案,将由蚂蚁金服主要贡献。在 Saga 模式下,分布式事务内有多个参与者,每一个参与者都是一个冲正补偿服务,需要用户根据业务场景实现其正向操作和逆向回滚操作。
分布式事务执行过程中,依次执行各参与者的正向操作,如果所有正向操作均执行成功,那么分布式事务提交。如果任何一个正向操作执行失败,那么分布式事务会去退回去执行前面各参与者的逆向回滚操作,回滚已提交的参与者,使分布式事务回到初始状态。
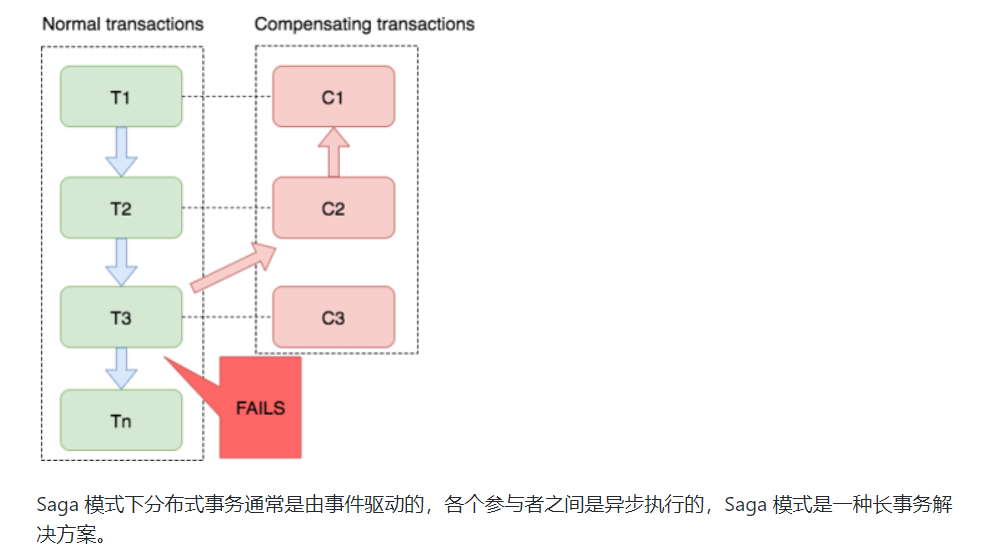

Saga模式的优势是:
- 一阶段提交本地数据库事务,无锁,高性能;
- 参与者可以采用事务驱动异步执行,高吞吐;
- 补偿服务即正向服务的“反向”,易于理解,易于实现;
缺点:Saga 模式由于一阶段已经提交本地数据库事务,且没有进行“预留”动作,所以不能保证隔离性。后续会讲到对于缺乏隔离性的应对措施。
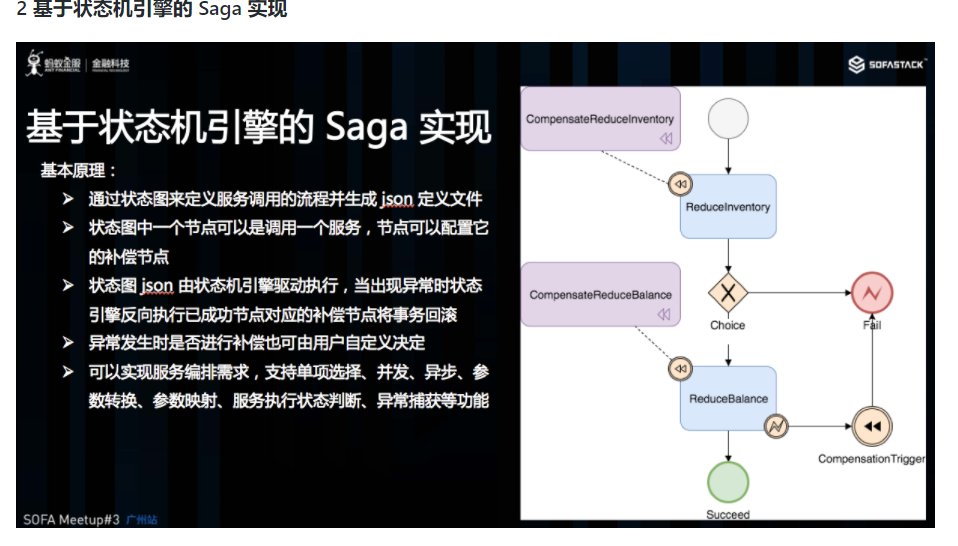
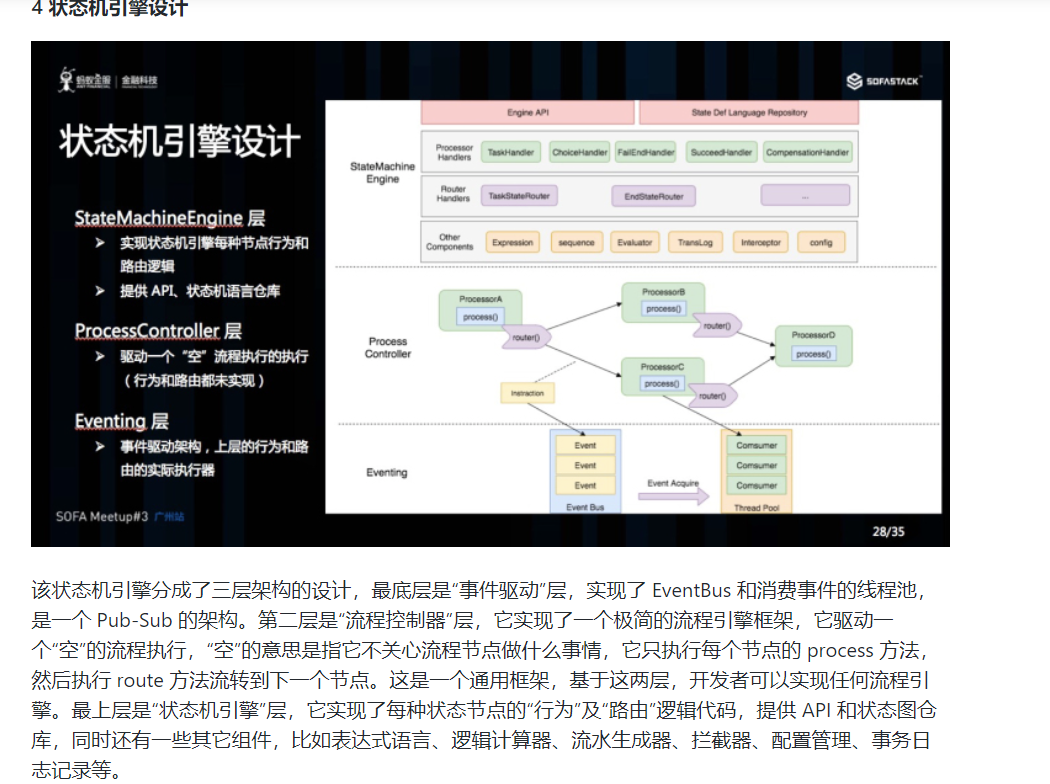
目前 Saga 的实现一般有两种,一种是通过事件驱动架构实现,一种是基于注解加拦截器拦截业务的正向服务实现。Seata 目前是采用事件驱动的机制来实现的,Seata 实现了一个状态机,可以编排服务的调用流程及正向服务的补偿服务,生成一个 json 文件定义的状态图,状态机引擎驱动到这个图的运行,当发生异常的时候状态机触发回滚,逐个执行补偿服务。当然在什么情况下触发回滚用户是可以自定义决定的。该状态机可以实现服务编排的需求,它支持单项选择、并发、异步、子状态机调用、参数转换、参数映射、服务执行状态判断、异常捕获等功能。
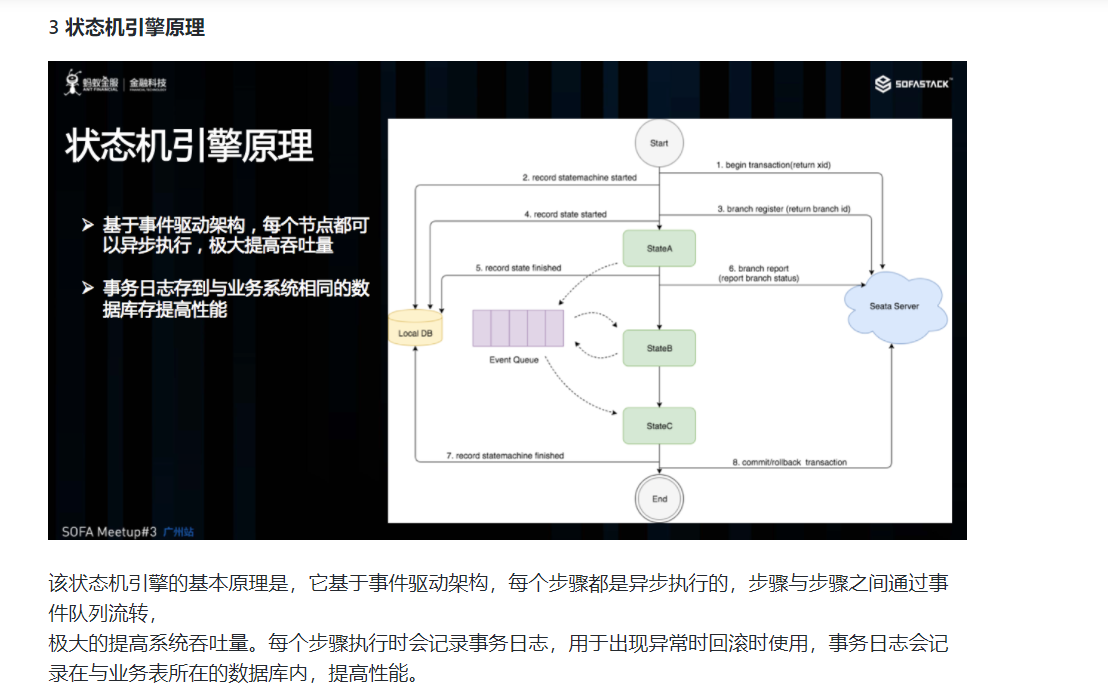



前面讲到 Saga 模式不保证事务的隔离性,在极端情况下可能出现脏写。比如在分布式事务未提交的情况下,前一个服务的数据被修改了,而后面的服务发生了异常需要进行回滚,可能由于前面服务的数据被修改后无法进行补偿操作。这时的一种处理办法可以是“重试”继续往前完成这个分布式事务。由于整个业务流程是由状态机编排的,即使是事后恢复也可以继续往前重试。所以用户可以根据业务特点配置该流程的事务处理策略是优先“回滚”还是“重试”,当事务超时的时候,Server 端会根据这个策略不断进行重试。
由于 Saga 不保证隔离性,所以我们在业务设计的时候需要做到“宁可长款,不可短款”的原则,长款是指在出现差错的时候站在我方的角度钱多了的情况,钱少了则是短款,因为如果长款可以给客户退款,而短款则可能钱追不回来了,也就是说在业务设计的时候,一定是先扣客户帐再入帐,如果因为隔离性问题造成覆盖更新,也不会出现钱少了的情况。
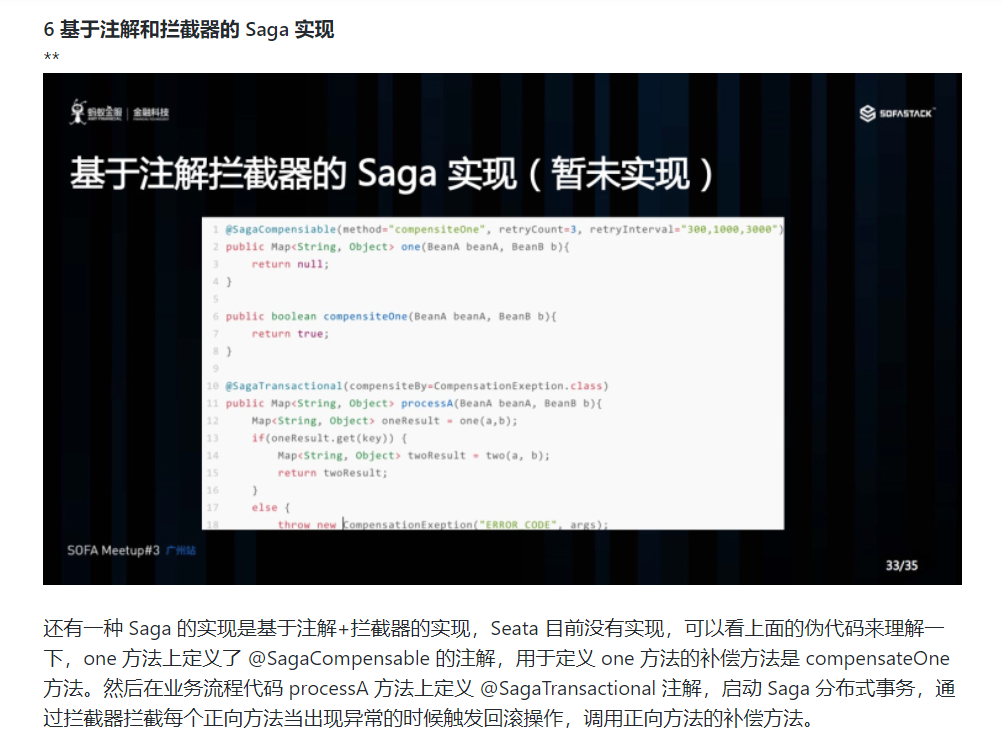
还有一种 Saga 的实现是基于注解+拦截器的实现,Seata 目前没有实现,可以看上面的伪代码来理解一下,one 方法上定义了 @SagaCompensable 的注解,用于定义 one 方法的补偿方法是 compensateOne 方法。然后在业务流程代码 processA 方法上定义 @SagaTransactional 注解,启动 Saga 分布式事务,通过拦截器拦截每个正向方法当出现异常的时候触发回滚操作,调用正向方法的补偿方法。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号