
数据分析常见数学公式(更新中...)
2016-08-10 18:25 猎手家园 阅读(7607) 评论(0) 收藏 举报1、方差:就是和中心偏离的程度!用来衡量一批数据的波动大小(即这批数据偏离平均数的大小)并把它叫做这组数据的方差。标准差是方差平方根。
公式:
举例:比如1.2.3.4.5 这五个数的平均数是3
方差就是: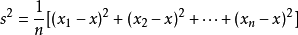
即:1/5[(1-3)²+(2-3)²+(3-3)²+(4-3)²+(5-3)²]=2
2、kmeans是最简单的聚类算法之一,但是运用十分广泛。kmeans一般在数据分析前期使用,选取适当的k,将数据分类后,然后分类研究不同聚类下数据的特点。
3、正态分布(Normal distribution)又名高斯分布(Gaussian distribution),是一个在数学、物理及工程等领域都非常重要的概率分布,在统计学的许多方面有着重大的影响力。若随机变量X服从一个数学期望为μ、方差为σ^2的高斯分布,记为N(μ,σ^2)。
4、 表示求和:∑读音为sigma,英文意思为Sum。其中i表示下界,n表示上界, k从i开始取数,一直取到n,全部加起来。
5、对数函数:如果ax=N(a>0,且a≠1),那么数x叫做以a为底N的对数,记作x=logaN,读作以a为底N的对数,其中a叫做对数的底数,N叫做真数。
图形如下:
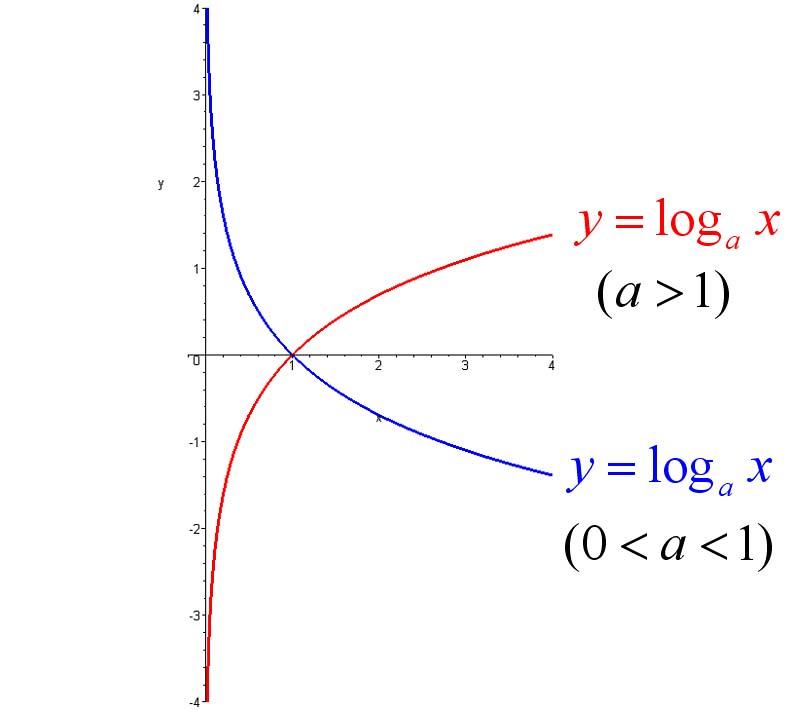
6、自然对数:以常数e为底数的对数叫做自然对数,记作lnN(N>0)。它的含义是单位时间内,持续的翻倍增长所能达到的极限值。
自然对数的底数e是由一个重要极限给出的。我们定义:当n趋于无限时,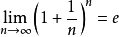 。
。
e是一个无限不循环小数,其值约等于2.718281828459…,它是一个超越数。
7、最小二乘法
残差:设yi是被解释变量的第i次样本观测值, yi^是相应的第 i 次样本估计值。将 yi 与 yi^之间的偏差记作ei称 ei为第 i 次样本观测值的残差。
最小二乘准则:使全部样本观测值的残差平方和达到最小。
8、导数:导数是函数的局部性质。一个函数在某一点的导数描述了这个函数在这一点附近的变化率。如果函数的自变量和取值都是实数的话,函数在某一点的导数就是该函数所代表的曲线在这一点上的切线斜率。导数的本质是通过极限的概念对函数进行局部的线性逼近。例如在运动学中,物体的位移对于时间的导数就是物体的瞬时速度。
9、基本初等函数:http://baike.baidu.com/view/363955.htm
10、各分步函数与图形
二项分步
多项分步
正态分步
伯努力试验
T分步
均匀分步
泊松分步
11、泊松分步:是一种统计与概率学里常见到的离散概率分布。
泊松分布适合于描述单位时间内随机事件发生的次数。如某一服务设施在一定时间内到达的人数,电话交换机接到呼叫的次数,汽车站台的候客人数,机器出现的故障数,自然灾害发生的次数等等。
12、伯努力试验和二项分步:(Bernoulli experiment)是在同样的条件下重复地、相互独立地进行的一种随机试验。其特点是该随机试验只有两种可能结果:发生或者不发生。
二项分布:一般地,在n次独立重复试验中,用ξ表示事件A发生的次数,如果事件发生的概率是P,则不发生的概率 q=1-p,N次独立重复试验中发生K次的概率是:
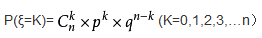
那么就说ξ服从二项分布。.其中P称为成功概率。
记作:ξ~B(n,p)
期望:Eξ=np
方差:Dξ=npq
13、排列:从n个不同元素中取出m(m≤n)个元素的所有排列的个数,叫做从n个不同元素中取出m个元素的排列数,用符号Anm(或Pnm,或nPm)表示。
公式: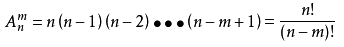
14、组合:一般地,从m个不同的元素中,任取n(n≤m)个元素为一组,叫作从m个不同元素中取出n个元素的一个组合。
公式: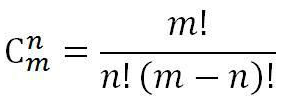
15、阶乘:一个正整数的阶乘(英语:factorial)是所有小于及等于该数的正整数的积,并且有0的阶乘为1。自然数n的阶乘写作n!。
16、神经网络算法:人工神经网络也就是一个普通的分类器而已,解决那些人类可以解决的Task。机器学习模型都只能解决两个问题:特征选择(Feature Selection)和函数拟合(Function Fitting)
17、箱形图(箱尾图):是一种用作显示一组数据分散情况资料的统计图。
(1)箱形图为我们提供了识别异常值的一个标准:异常值被定义为小于Q1-1.5IQR或大于Q3+1.5IQR的值。
(2)判断数据偏态和尾重。
(3)比较几批数据的形状
18、支持向量机(SVM):超级通俗的解释:支持向量机是用来解决分类问题的。
先考虑最简单的情况,豌豆和米粒,用筛子很快可以分开,小颗粒漏下去,大颗粒保留。
用一个函数来表示就是当直径d大于某个值D,就判定为豌豆,小于某个值就是米粒。
d>D, 豌豆
d<D, 米粒
在数轴上就是在d左边就是米粒,右边就是绿豆,这是一维的情况。
但是实际问题没这么简单,考虑的问题不单单是尺寸,一个花的两个品种,怎么分类?
假设决定他们分类的有两个属性,花瓣尺寸和颜色。单独用一个属性来分类,像刚才分米粒那样,就不行了。这个时候我们设置两个值 尺寸x和颜色y。
我们把所有的数据都丢到x-y平面上作为点,按道理如果只有这两个属性决定了两个品种,数据肯定会按两类聚集在这个二维平面上。
我们只要找到一条直线,把这两类划分开来,分类就很容易了,以后遇到一个数据,就丢进这个平面,看在直线的哪一边,就是哪一类。
比如x+y-2=0这条直线,我们把数据(x,y)代入,只要认为x+y-2>0的就是A类,x+y-2<0的就是B类。
以此类推,还有三维的,四维的,N维的 属性的分类,这样构造的也许就不是直线,而是平面,超平面。
一个三维的函数分类 :x+y+z-2=0,这就是个分类的平面了。
有时候,分类的那条线不一定是直线,还有可能是曲线,我们通过某些函数来转换,就可以转化成刚才的哪种多维的分类问题,这个就是核函数的思想。
例如:分类的函数是个圆形x^2+y^2-4=0。这个时候令x^2=a; y^2=b,还不就变成了a+b-4=0 这种直线问题了。
这就是支持向量机的思想。机的意思就是“算法”,机器学习领域里面常常用“机”这个字表示算法。
支持向量意思就是数据集种的某些点,位置比较特殊,比如刚才提到的x+y-2=0这条直线,直线上面区域x+y-2>0的全是A类,下面的x+y-2<0的全是B类,我们找这条直线的时候,一般就看聚集在一起的两类数据,他们各自的最边缘位置的点,也就是最靠近划分直线的那几个点,而其他点对这条直线的最终位置的确定起不了作用,所以我姑且叫这些点叫“支持点”(意思就是有用的点),但是在数学上,没这种说法,数学里的点,又可以叫向量,比如二维点(x,y)就是二维向量,三维度的就是三维向量( x,y,z)。所以 “支持点”改叫“支持向量”,听起来比较专业,NB。所以就是 支持向量机 了。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号