bagging与随机森林算法原理小结
********************************原文 https://www.cnblogs.com/pinard/p/6156009.html *******************************8
在集成学习小结中,有两个流派,分别是boosting流派+bagging流派
boosting流派是指各个弱分类器之间有依赖关系
bagging流派是指各个弱分类器之间没有依赖关系,可以并行拟合。
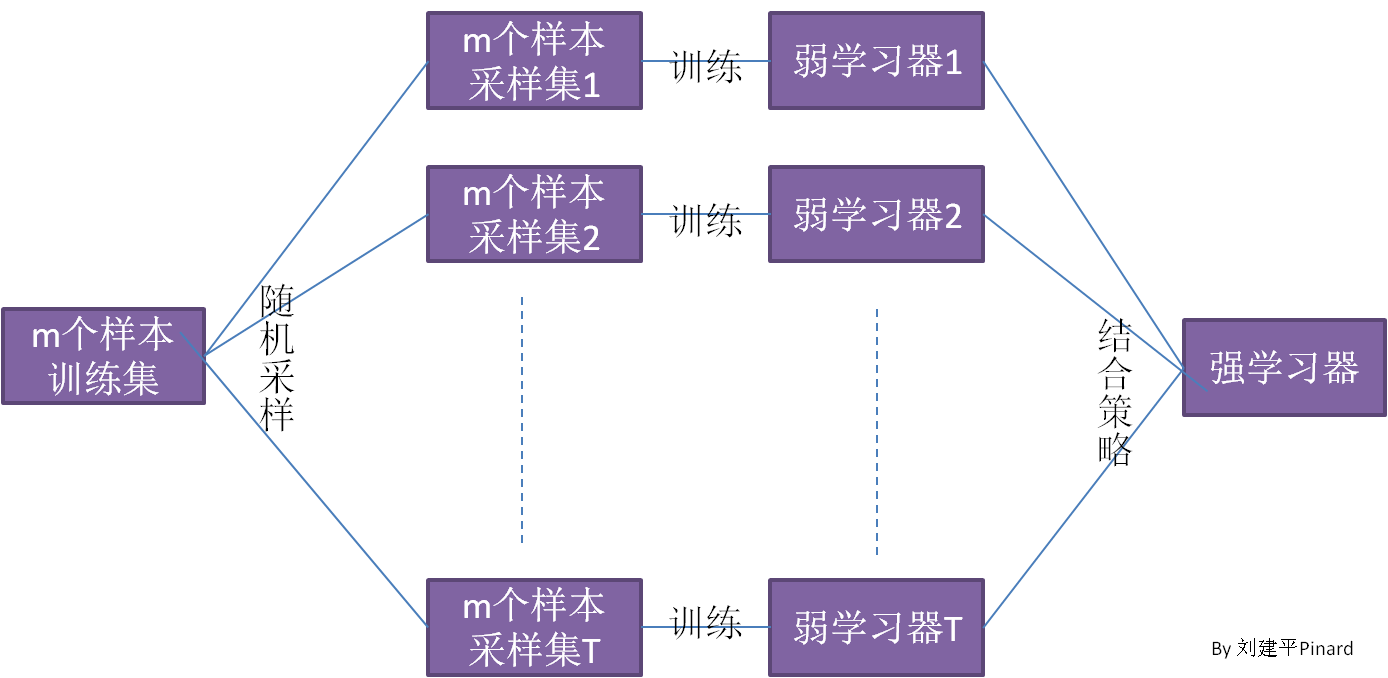
bagging特点在于随机采样。
即没采集一个样本后,都将样本放回。
GBDT的子采样是无返回采样,bagging是放回采样。
对于一个样本,它在某一次含m个样本的训练集的随机采样中,每次被采集到的概率是1m1m。不被采集到的概率为1−1m1−1m。如果m次采样都没有被采集中的概率是(1−1m)m(1−1m)m。当m→∞m→∞时,(1−1m)m→1e≃0.368(1−1m)m→1e≃0.368。也就是说,在bagging的每轮随机采样中,训练集中大约有36.8%的数据没有被采样集采集中。
bagging的集合策略也比较简单
对于分类问题,通常使用的是简答投票法,得到最多票数的类别或者类别之一为最终的模型输出
对于回归问题,通常使用简单平均法,对T个弱学习器得到的回归结果进行算法平均值得到最终的模型输出。
随机森林算法
random forest是bagging算法的进化版,他的思想是bagging。但是rf有了一定的改进。
1 首先,RF使用了CART决策树作为弱学习器,这个和梯度提升树类似,同样选择CART但是RF对决策树进行了一定的改进,
对于普通的决策树,我们会在节点上所有的n个样本特征中选择一个最优的特征来做决策树的左右子树的划分,但是RF是通过选择节点上的一部分样本特征,这个数字小于N,假设为M,然后在这些随机选择的M个样本特征中继续计算一个最优的特征来做决策树的左右子树划分,这样增强了模型的泛华能力。
如果M=N,则此时的RF的CART和普通的CART决策树没有区别,M越小,模型越健壮,但是拟合能力就越差。
除了这一点和普通的bagging没有什么不同。
随机森林小结
RF的主要优点:
1 训练可以高度并行化
2 由于可以随机选择决策树结点划分特征,这样在样本特征维度很高的时候,仍然能高效的训练模型。
3 在训练后,可以给出各个特征对于输出的重要性
4 由于选择了随机性,训练出的模型的方差小,泛华能力强
5 RF实现比较简单
6 对部分缺失的特征不敏感
RF的主要缺点:
1 在某些噪音比较大的数据集上,RF模型容易陷入过拟合
2 取值划分比较多的特征容易对RF的决策产生更大的影响
随机森林的随机性
随机森林RF的随机来源于算法用于训练数据的不同子集训练每个单独的决策树,用数据中随机选择的属性对每个决策树的每个节点进行分割,通过引入这种随机性元素,该算法能够创建批次不相关的模型。这导致可能的误差均匀分布在模型中。意味着误差最终会通过随机森林模型的多数投票决策被消除。
1 特征选择的随机性
2 样本的随机性,采用boostrap的采样思想,每次有返回的从样本中选取特定数量的样本作为样本集。
输入数据不需要做归一化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号