Boosting算法3---XGBoost
**************************原文 https://www.zhihu.com/question/41354392 ****************************
************************** https://blog.csdn.net/zwqjoy/article/details/89281846 ******************************
XGBoost内部实现了梯度提升数GBDT模型,并对模型中算法进行了诸多优化,在取得高精度的同时又保持了极快的速度。
XGBoost最大的特点在于,他能够利用CPU的多线程进行并行,同时在算法上加以改进提高了精度。
通过多伦迭代,每轮迭代产生一个弱分类器,每个分类器再上一轮分类器的残差基础上进行训练。对弱分类器的要求一般是足够简单,要求是低方差,高偏差。因为在训练的过过程中通过减低偏差来不断提高最终分类器的精度。
XGBoost的目标函数
不是直接最小化损失函数作为训练目标,而是在上述的基础上加上数的复杂度。这样是为了避免过拟合。最后的目标函数为

其中正则项控制着模型的复杂度,包括了叶子结点数目和leaf score的l2模的开发
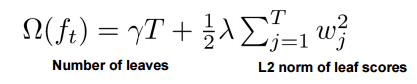
GBDT与XGBoost算法的区别
1 传统的gbdt以cart作为基分类器,xgboost还支持线性分类器,这个时候xgboost相当于带l1和l2正则化项的logisti 回归和线性和回归
2 传统的GBDT在优化时只用到了一阶导数信息,xgboost则对代价函数进行二阶泰勒展开。同时用到了一阶和二阶,同时xgboost支持自定义代价函数,只要函数可一阶和二阶即可
3 xgboost在代价函数里面加入了正则化项,用于控制模型的复杂度。正则化项包含了数的叶节点个数
4 xgboost在进行一次迭代后,会将叶子结点的权重乘上学习速率。主要是为了消减每棵树的影响。
5 对缺失值的处理,xgboost可自动学习到它的分裂方向
6 xgboost工具支持并行,xgboost的并行是在特征粒度上的,由于决策树的学习最耗时的一个步骤就是确定最佳分割点,xgboost在训练之前,预先对数据进行了排序,然后保存为block接口狗,后面迭代重复利用该blok。大大减小了计算量。在进行节点分裂计算时,需要计算每个特征的增益,最终选择增益最大的那个特征进行分裂,那么各个特征的增益计算就可以多线程计算。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号