TEXTCNN算法原理与实践
------------------原文 https://blog.csdn.net/asialee_bird/article/details/88813385 ----------------
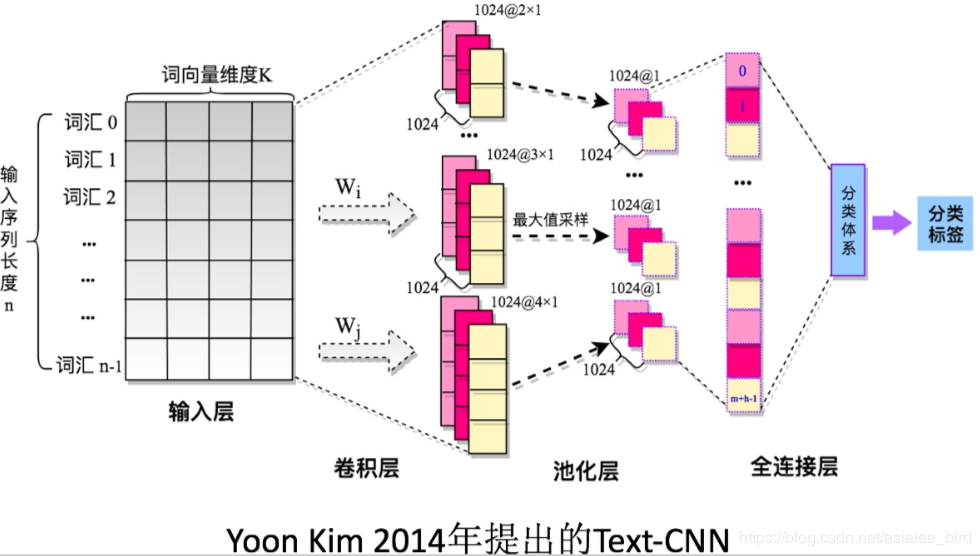
上图是textcnn的框架,句子中每个单词是n维词向量,输入矩阵是m*n,m为句子长度,cnn需要对输入样本进行卷积操作,对于文本数据,filter不再横向滑动,仅仅是向下移动,
1 嵌入层
2 卷积层
在图像处理时卷积核的宽度和高度是一样的,是text-cnn中,卷积核的宽度是于词向量的维度一致的,这是因为我们输入的每一行向量代表一个词,在抽取特征的过程中,词作为文本的最小粒度,而高度与cnn一样的,可以自行设置,通常取值2 3 4 5,高度类似于n-gram
3 池化层
在池化层到全连接层之前加上dropout防止过拟合。
4 全连接层
全连接层和其他模型一样的,假设有两层连接层,第一层加上relu,第二层使用softmax激活函数得到属于每个类的概率。
5 TextCNN的小变种
6 参数与超参数
1 sequence_length 对于cnn,输入与输出是固定的,可每个句子长短不一,处理方案是 需要做定长处理,比如定为n,超过截取,不足补0,
2 num_class
3 vocabulary——size
4 embedding_size 将原来语料库的词典大小降低为embedding_size
5 filter_size_arr
论文调参结论
1 使用预训练的Word2vec GloVec初始化效果会更好 一般不直接使用onehot
2 卷积核的大小影响较大,一般取1 --10 对于句子较长的文本,则应该选择大一些
3 卷积核的数据也有较大影响,一般取100-600 同时一般使用Dropout
4 激活函数一般选择Relu 和 tanh
5 池化层使用 1-max pooling
6 随着feature map数量增加,性能减小时,尝试使用大于0.5的Drooput
7 性能评估使用交叉验证

 浙公网安备 33010602011771号
浙公网安备 33010602011771号