python花式写法
python取列表最后一个数
+---+---+---+---+---+---+
| P | y | t | h | o | n |
+---+---+---+---+---+---+
0 1 2 3 4 5
-6 -5 -4 -3 -2 -1
>>> p = 'Python'
>>> p[-1]
'n'
print([q for q in range(1,100)])
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99]
pycharm使用时导入应用报错
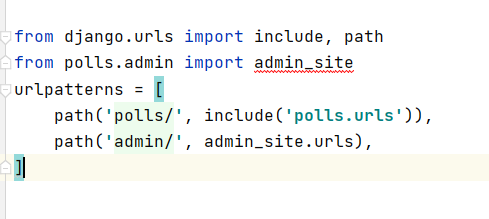
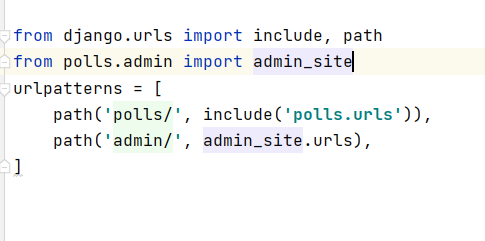
Python assert(断言)用于判断一个表达式,在表达式条件为 false 的时候触发异常。
断言可以在条件不满足程序运行的情况下直接返回错误,而不必等待程序运行后出现崩溃的情况,例如我们的代码只能在 Linux 系统下运行,可以先判断当前系统是否符合条件。
语法格式如下:
assert expression
等价于:
if not expression:
raise AssertionError
assert 后面也可以紧跟参数:
assert expression [, arguments]
等价于:
if not expression:
raise AssertionError(arguments)
assertIn("Python", driver.title)
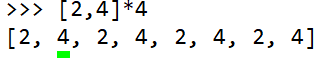

my_list = list(reversed(my_list))
reserved() 是 Pyton 内置函数之一,其功能是对于给定的序列(包括列表、元组、字符串以及 range(n) 区间),该函数可以返回一个逆序序列的迭代器(用于遍历该逆序序列)。
如何在两个数字之间执行按位与运算a & b
如何在两个数字之间执行按位异或运算a ^ b
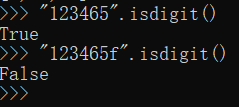
"123456".startswith("1") 如何检查一个字符串是否以另一个字符串开头?
调用其方法的字符串插入到每个给定字符串之间。结果作为新字符串返回。>>> ",".join("a,b")'a,,,b'
返回字符串中单词的列表,使用 sep 作为分隔符字符串。>>> "a,b".split(",")['a', 'b']返回字符串的大写版本。更具体地说,使第一个字符大写,其余小写>>> "abcc".capitalize()'Abcc'
语法类似于您使用的语法,str.format()但不那么冗长。看看这是多么容易阅读:
>>> name = "Eric" >>> age = 74 >>> f"Hello, {name}. You are {age}." 'Hello, Eric. You are 74.'
>>> F"Hello, {name}. You are {age}."
'Hello, Eric. You are 74.'
>>> def to_lowercase(input): ... return input.lower() >>> name = "Eric Idle" >>> f"{to_lowercase(name)} is funny." 'eric idle is funny.'
>>> f'''Eric Idle''' 'Eric Idle'
>>> f"""Eric Idle""" 'Eric Idle'>>> f"{'Eric Idle'}"
'Eric Idle'使用 args 和 kwargs 的替换返回 S 的格式化版本。替换由大括号('{' 和 '}')标识。
>>> "%(a)".format(a=123)
'%(a)'
>>> "%{a}".format(a=123)
'%123'
>>> "{a}".format(a=123)
'123'
>>>
>>> "123456".find("2")
1
>>>返回 S 中找到子字符串 sub 的最低索引,使得 sub 包含在 S[start:end] 中。 可选的参数 start 和 end 被解释为切片表示法。失败时返回 -1。
>>> a
{2: 2, 1: 1}
>>> for key in a:
... print(a)
...
{2: 2, 1: 1}
{2: 2, 1: 1}
>>> [x for x in a]
[2, 1]
>>>
>>> name="John"
>>> result = name == "John" and "John" or "Jane"
>>> result
'John'
>>>
三元关系
>>> a=[0,1,2,3,4,5,6]
>>> del a[1]
>>> a
[0, 2, 3, 4, 5, 6]
>>>
def fun(name,age):
pass
fun(age=10,10)这样可以
fun(name=10,10)这样不行
>>> a=[1,2,3]
>>> a=list(map(lambda x: x*2 ,a))
>>> print(a)
[2, 4, 6]
add=lambda x,y:x+y
print(add(1,2))
返回对象是类的实例还是其子类的实例
class b:
name="name"
age="age"
a=b()
print(isinstance(a,b))
a.age='hello'
print(a.age)
del a.age
print(a.age)
del a
print(a.age)
True
hello
age
NameError: name 'a' is not defined
class a:
def __init__(self):
print("init")
class b(a):
def __init__(self):
super().__init__()
b=b()
print(type(a).__dict__)
print(dir(a))
print(repr(a))
print(a.__dir__())
{'__module__': '__main__', 'name': 'name', 'age': 'age', '__dict__': <attribute '__dict__' of 'b' objects>, '__weakref__': <attribute '__weakref__' of 'b' objects>, '__doc__': None}
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'age', 'name']
<__main__.b object at 0x00000186E6E10E20>
['__module__', 'name', 'age', '__dict__', '__weakref__', '__doc__', '__repr__', '__hash__', '__str__', '__getattribute__', '__setattr__', '__delattr__', '__lt__', '__le__', '__eq__', '__ne__', '__gt__', '__ge__', '__init__', '__new__', '__reduce_ex__', '__reduce__', '__subclasshook__', '__init_subclass__', '__format__', '__sizeof__', '__dir__', '__class__']
c={}
c= {1} | {2}
print(c)
c.update({"123":"123"})
c.update({"456":"123"})
print(c)
c={**{1:123},**{2:654}}
print(c)
c={1:12}+{2:123}
print(c)
a={1:1,2:2}
print(1 in a)
a={1:1,2:2}
print(1 in a)
print(type(a))
del a[1]
print(1 in a)
a.get(3) #没有外键不报错
my_dict={}
keys, values = ["a", "b", "c"], [1, 2, 3]
my_dict.fromkeys(keys, values)
print(my_dict)
keys, values = ["a", "b", "c"], [1, 2, 3]
my_dict = dict(zip(keys, values))
print(my_dict)
keys, values = ["a", "b", "c"], [1, 2, 3]
my_dict = {}
for x in range(len(keys)):
my_dict[keys[x]] = values[x]
print(my_dict)
keys, values = ["a", "b", "c"], [1, 2, 3]
my_dict = {keys[x]:values[x] for x in range(len(keys))}
print(my_dict)
{}
{'a': 1, 'b': 2, 'c': 3}
{'a': 1, 'b': 2, 'c': 3}
{'a': 1, 'b': 2, 'c': 3}
在导入期间如何告诉 Python 解释器在哪里搜索模块?
sys.path.append("/foo")
import string
print(help(string))
print(dir(string))
print(repr(string))
如何指定导入的模块必须位于同一个包内
from . import string
如何使用函数动态导入模块?
module_name = "os"
os = __import__(module_name)
print([a for a in range(10) if a % 2 ==0])
>>> {letter for letter in set(["hello"])}
{'hello'}
>>> {letter for letter in "hello"}
{'o', 'h', 'e', 'l'}
>>>
>>> [x for x in range(10)]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> [x**2 for x in range(10)]
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
>>> [x^2 for x in range(10)]
[2, 3, 0, 1, 6, 7, 4, 5, 10, 11]
>>>
二元数组展开
regular_list = [[1, 2, 3, 4], [5, 6, 7], [8, 9]]
flat_list = [item for sublist in regular_list for item in sublist]
print('Original list', regular_list)
print('Transformed list', flat_list)
Original list [[1, 2, 3, 4], [5, 6, 7], [8, 9]]
Transformed list [1, 2, 3, 4, 5, 6, 7, 8, 9]
生成二元数组
>> (x,y for x in range(3) for y in range(3))
File "<stdin>", line 1
(x,y for x in range(3) for y in range(3))
^^^
SyntaxError: invalid syntax
>>> [(x,y) for x in range(3) for y in range(3)]
[(0, 0), (0, 1), (0, 2), (1, 0), (1, 1), (1, 2), (2, 0), (2, 1), (2, 2)]
>>> [(x,y) for x in range(3)] for y in range(3)
File "<stdin>", line 1
[(x,y) for x in range(3)] for y in range(3)
IndentationError: unexpected indent
>>> [[(x,y) for x in range(3)] for y in range(3)]
[[(0, 0), (1, 0), (2, 0)], [(0, 1), (1, 1), (2, 1)], [(0, 2), (1, 2), (2, 2)]]
>>>
import re
pattern = r"\d+"
re_obj = re.compile(pattern)
import re
pattern = r"\d+"
string = "Some text. 123. Some text"
print(re.split(pattern, string))
['Some text. ', '. Some text']
import re
pattern = r"\d+"
string = "Some text. 123. Some text. 321"
replacement = "Some text3214"
print(re.sub(pattern, replacement, string))
Some text. Some text3214. Some text. Some text3214
import re
pattern = r"\d+"
string = "Some text. 123. Some text. 321"
occurrences = re.finditer(pattern, string)
print([o.group() for o in occurrences])
import re
pattern = r"\d+"
string = "Some text. 123. Some text. 321"
re_obj = re.compile(pattern)
print(re_obj.findall(string))
import re
pattern = r"\d+"
string = "Some text. 123. Some text. 321"
print(re.findall(pattern, string))
import re
pattern = r"\d+"
string = "Some text. 123. Some text. 321"
re_obj = re.compile(pattern)
print(re_obj.search(string))
['123', '321']
['123', '321']
['123', '321']
<re.Match object; span=(11, 14), match='123'>
import re
pattern = r"\d+"
string = "Some text. 123. Some text. 321"
replacement = "Some text"
result, replaced_count = re.subn(pattern, replacement, string)
print(replaced_count)
import re
pattern = r"\d+"
string = "Some text. 123. Some text. 321"
replacement = "Some text"
replaced_count = len(re.sub(pattern, replacement, string))
print(replaced_count)
import re
pattern = r"\d+"
string = "Some text. 123. Some text. 321"
replacement = "Some text"
replaced_count = re.subn(pattern, replacement, string)
print(replaced_count)
2
42
('Some text. Some text. Some text. Some text', 2)
>>> import re
>>> pattern = r"(\d+) (\d+)?"
>>> string = "123 text"
>>> match_object = re.match(pattern, string)
>>> print(match_object.lastgroup)
None
>>> import re
>>> pattern = r"(\d+) (\d+)?"
>>> string = "123 text"
>>> match_object = re.match(pattern, string)
>>> print(match_object.groups()[-1])
None
>>> import re
>>> pattern = r"(\d+) (\d+)?"
>>> string = "123 text"
>>> match_object = re.match(pattern, string)
>>> print(match_object.group(match_object.lastindex))
123
>>> import re
>>> pattern = r"(\d+) (\d+)?"
>>> string = "123 text"
>>> match_object = re.match(pattern, string)
>>> print(match_object.groups()[match_object.lastindex])
None
>>>
import re
string="Hello"
pattern = r"hello"
re_obj = re.compile(pattern, re.I)
if re_obj.search(string):
print("Found")
import re
pattern = r"hello"
re_obj = re.compile(pattern, re.IGNORECASE)
if re_obj.match(string):
print("Found")
import re
pattern = r"hello"
if re.findall(pattern, string, re.IGNORECASE):
print("Found")
import re
pattern = r"/hello/i"
re_obj = re.compile(pattern)
if re_obj.search(string):
print("Found hello")
Found
Found
Found
>>> import re
>>> string = "Some text; 123, Some text, 123"
>>> pattern = r",;"
>>> print(re.split(pattern, string))
['Some text; 123, Some text, 123']
>>> import re
>>> string = "Some text; 123, Some text, 123"
>>> pattern = r"(,;)"
>>> print(re.split(pattern, string))
['Some text; 123, Some text, 123']
>>> import re
>>> string = "Some text; 123, Some text, 123"
>>> pattern = r"[,;]"
>>> print(re.split(pattern, string))
['Some text', ' 123', ' Some text', ' 123']
>>> import re
>>> string = "Some text 'a', Some text 'b'"
>>> pattern = r"'(.*?)'"
>>> re_obj = re.compile(pattern)
>>> result = re_obj.findall(string)
>>> result
['a', 'b']
>>> import re
>>> string = "Some text 'a', Some text 'b'"
>>> pattern = r"'(.*)'"
>>> re_obj = re.compile(pattern)
>>> result = re_obj.findall(string)
>>> result
["a', Some text 'b"]
>>>
>>> import re
>>> string = '''multiline
... string
... '''
>>> pattern = r"mul(.\n)+ing"
>>> re_obj = re.compile(pattern)
>>> re_obj.findall(string)
[]
>>> import re
>>> string = '''multiline
... string
... '''
>>> pattern = r"mul.+ing"
>>> re_obj = re.compile(pattern, re.MULTILINE)多行
>>> re_obj.findall(string)
[]
>>> import re
>>> string = '''multiline
... string
... '''
>>> pattern = r"mul.+ing"
>>> re_obj = re.compile(pattern, re.MULTILINE)多行
>>> re_obj.findall(string)
[]
>>> import re
>>> string = '''multiline
... string
... '''
>>> pattern = r"mul.+ing"
>>> re_obj = re.compile(pattern, re.DOTALL)点
>>> re_obj.findall(string)
['multiline\n string']
>>>
>>> import re
>>> string = "Python"
>>> pattern = r"^Python$"
>>> re_obj = re.compile(pattern)
>>> if re_obj.search(string):
... print("The whole string matches the pattern")
...
The whole string matches the pattern
>>> import re
>>> string = "Python"
>>> pattern = r"^Python$"
>>> if re.match(pattern, string):
... print("The whole string matches the pattern")
...
The whole string matches the pattern
>>> import re
>>> string = "Python"
>>> pattern = r"Python"
>>> if re.fullmatch(pattern, string):
... print("The whole string matches the pattern") # 如果整个字符串匹配这个正则表达式,则返回一个对应的 匹配对象。None如果字符串与模式不匹配则返回;请注意,这与零长度匹配不同。
...
The whole string matches the pattern
>>> import re
>>> string = "Python"
>>> pattern = r"Python"
>>> if re.match(pattern, string):
... print("The whole string matches the pattern")
...
The whole string matches the pattern
>>>
my_list = [1, 2, 3]
try:
my_list[5] = 0
except IndexError:
print("my_list[5] not found")
my_list[5] not found
>>> raise ValueError("Error description")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: Error description
>>> raise ValueError
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError
>>> raise ValueError()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError
>>> raise "Error description"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: exceptions must derive from BaseException
>>>
def my_func():
a=1/0
pass
try:
my_func()
except [ValueError, IndexError]:选择一种类型报错
print("Exception caught")
def my_func():
a=1/0
pass
try:
my_func()
except Exception:
print("Exception caught")
try:
my_func()
except :
print("Exception caught")
def my_func():
a=1/0
pass
try:
my_func()
except ValueError:
print("ValueError")
finally:最后
print("Finished")
def my_func():
pass
try:
my_func()
except ValueError:
print("ValueError")
finally:
print("Finished")
try:
my_func()
except ValueError:
print("ValueError")
else:
print("Finished")
try:
my_func()
except ValueError:
print("ValueError")
except None: 没有这种异常
print("There was no exception")
def my_func():
a=1/0
pass
# try:
# my_func()
# except ZeroDivisionError:
# raise sys.exc_info[0]
try:
my_func()
except ZeroDivisionError:
raise ZeroDivisionError
>>> class MyException(Exception):
... message = "Custom exception"
...
>>> try:
... raise MyException()
... except MyException as e:
... print(e)
...
>>> class MyException(Exception):
... def __str__(self):
... print("Custom exception") 自定义异常
...
>>> try:
... raise MyException()
... except MyException as e:
... print(e)
...
Custom exception
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
Custom exception
__main__.MyException: <exception str() failed>
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<stdin>", line 4, in <module>
TypeError: __str__ returned non-string (type NoneType)
>>> class MyException(Exception):
... def __repr__(self): 不行
... return "Custom exception"
...
>>> try:
... raise MyException()
... except MyException as e:
... print(e)
...
>>>
>>> class MyException(Exception):
... def __str__(self):
... return "Custom exception"
...
>>> try:
... raise MyException()
... except MyException as e:
... print(e)
...
Custom exception
>>>
>>> import traceback
>>> try:
... raise MyException()
... except MyException:
... traceback.print_exc()
...
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
MyException: Custom exception
>>> import traceback
>>> try:
... raise MyException()
... except MyException as e:
... traceback.print_tb(e.__traceback__)
...
File "<stdin>", line 2, in <module>
>>> import traceback
>>> try:
... raise MyException()
... except MyException:
... traceback.print_exception(*sys.exc_info())
...
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
MyException: Custom exception
>>> import traceback
>>> try:
... raise MyException()
... except MyException:
... traceback.print_tb(sys.exc_info)
...
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
__main__.MyException: Custom exception
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<stdin>", line 4, in <module>
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python310\lib\traceback.py", line 53, in print_tb
print_list(extract_tb(tb, limit=limit), file=file)
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python310\lib\traceback.py", line 72, in extract_tb
return StackSummary.extract(walk_tb(tb), limit=limit)
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python310\lib\traceback.py", line 364, in extract
for f, lineno in frame_gen:
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python310\lib\traceback.py", line 329, in walk_tb
yield tb.tb_frame, tb.tb_lineno
AttributeError: 'builtin_function_or_method' object has no attribute 'tb_frame'
a=set()
>>> a=set([1,2,3])设置一个集合
>>> a
{1, 2, 3}
>>>
{1, 2, 3}
>>> a={1,2,3}
>>> a
{1, 2, 3}
>>> type(a)
<class 'set'>
>>> a={}没有元素 ,所以为字典
>>> type(a)
<class 'dict'>
>>>
>>> a=set()
>>> a
set()
>>> a=set(None)不能为空
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'NoneType' object is not iterable
>>>
>>> a={[]}不能为空列表
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
>>>
>>> a
{1, 2, 3}
>>> a.add(4)
>>> a
{1, 2, 3, 4}
>>>
>>> b=a[:]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'set' object is not subscriptable
>>> from copy import copy
>>> b=copy(a)拷贝
>>> b
{1, 2, 3, 4}
>>> b=set(a)复制
>>> b
{1, 2, 3, 4}
>>>
>>> b
{1, 2, 3, 4}
>>> b-={4}去掉一个元素
>>> b
{1, 2, 3}
>>> b.remove(4)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 4
>>> b.remove(3)
>>> b
{1, 2}
>>> b.pop(2)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: set.pop() takes no arguments (1 given)
>>> b.pop()
1 去掉最后一个元素
>>> b
{2}
>>> b=set(a)
>>> b.discard(4)如果它是成员,则从集合中删除一个元素。如果元素不是成员,则什么也不做
>>> b
{1, 2, 3}
>>>
>>> a
{1, 2, 3, 4}
>>> a |=set()
>>> a
{1, 2, 3, 4}
>>> del a[:]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'set' object does not support item deletion
>>> for e in a:
... del e
File "<stdin>", line 2
del e
^
IndentationError: expected an indented block after 'for' statement on line 1
>>> for e in a:
... del e
...
>>> a
{1, 2, 3, 4}
>>> a.clear() 清楚元素
>>> a
set()
>>>
import random
my_set={0,1,2,3,4,5}
element_index = random.randint(0, len(my_set) - 1)
my_set = my_set.remove(element_index)
print(my_set)
my_set={0,1,2,3,4,5}
element_index = random.randint(0, len(my_set) - 1)
my_set.remove(element_index)
print(my_set)
None
{0, 1, 2, 4, 5}
>>> a={1,2}
>>> b={1,2,3}
>>> a.intersection(b)
{1, 2}
"""
将两个集合的交集作为新集合返回。
(即两个集合中的所有元素。)
"""
>>> a.union(b)
{1, 2, 3}
"""
将集合的并集作为新集合返回。
(即任一集合中的所有元素。)
"""
>>> a.symmetric_difference(b)
{3}
"""
将两个集合的对称差作为新集合返回。
(即恰好在一组中的所有元素。)
"""
>>> a.difference(b)
set()
"""
将两个或多个集合的差作为新集合返回。
(即该集合中的所有元素,但不包含其他元素。)
"""
>>>
>>> a in b
False
>>> a.issuperset(b) 端口这个集合是否包含另一个集合
False
>>> a >>b
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unsupported operand type(s) for >>: 'set' and 'set'
>>> b in a
False
>>> b.issuperset(a) #b包含于a
True
>>>
>>> a.issubset(b) #b包含于a 报告另一个集合是否包含该集合。
True
>>>
>>> a= {4,5,6}
>>> a-b
{4, 5, 6}
>>> b-a
{1, 2, 3}
>>> a={1}
>>> a-b
set()
>>> b-a
{2, 3}
>>> len(b|a)
3
>>> len(a|b)
3
>>> a^b
{2, 3}
>>> b^a
{2, 3}
>>> a.isdisjoint(b)
False
>>> a={4,5,6}
>>> a.isdisjoint(b) 如果两个集合有一个空交集,则返回 True。
True
>>>
列表去重
>>> a=[1,2,1,4]
>>> a=list(set(a))
>>> a
[1, 2, 4]
>>>
>>> a
{1, 2, 3, 4}
>>> b
{4, 5, 6}
>>> a+b
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unsupported operand type(s) for +: 'set' and 'set'
>>> c={**a,**b}
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'set' object is not a mapping
>>> a.update(b)
>>> a
{1, 2, 3, 4, 5, 6}
>>> a.add(b)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'set'
>>> a
{1, 2, 3, 4, 5, 6}
>>> a={1,2,3,4}
>>> a.add(b)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'set'
>>> a&=b
>>> a
{4}
>>>
a.union(b) == a | b
a.intersection(b) == a & b
a.difference(b) == a - b
a.symmetric_difference(b) == a ^ b
"""
将两个集合的对称差作为新集合返回。
(即恰好在一组中的所有元素。)
"""
result = name == "John" and "John" or "Jane"
>>> name="John"
>>> result = "John" if name == "John" else "Jane"
>>> name
'John'
>>> result
'John'
>>> result = name == "John" and "John" or "Jane"
>>> result
'John'
>>>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号