

Redis 跳跃表
跳跃表
咱们可以想象一个场景,我们需要维护一个有序的集合,集合是按照某个字段进行排序的,集合会有添加和删除操作。
如何在内存中存储存储并维护这样的集合呢,我们可以想到链表或者数组进行存储,他们都是线性的结构,我们分别分析下这两种接口存储有序集合的场景。
- 数组
使用数组维护集合,当插入一个元素时,首先需要找到插入位置,通过二分查找时间复杂度为O(logn),找到插入位置后,需要将后面的元素都移动一位,时间复杂度为O(n)。
两个操作时间复杂度为O(n)。
- 链表
使用链表维护集合,当插入一个元素时,首先需要找到插入位置,链表不能二分查找,所以遍历链表直到找到元素时间复杂的为O(n),找到后插入元素复杂度为O(1)。
两个操作时间复杂度为O(n)。
当集合数据量很大时,会对性能产生影响。
我们可以观察到,链表这种结构删除或者新增一个节点复杂度都为O(n),而找某个节点需要遍历,复杂度为O(n),我们能不能想办法把找某个节点的复杂度优化一下呢?
跳跃表 就是优化了查找某个节点的复杂度。
例如有如下的链表:

我们找某个节点需要遍历链表,时间复杂度为O(n)。我们在这个链表之上再维护一个链表,为下面的偶数节点列表。
例如下图链表:
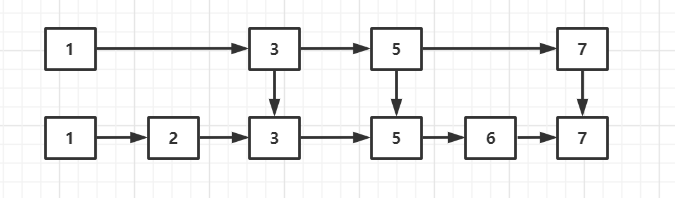
假如我要插入元素4,我遍历上面基数链表,定位到 3 和 5 之间,再返回到原来的链表定位,还是定位到 3 和 5 之间。
数据量少不够明显,可以想象下如果数据量大,查找次数将减少一半。这就是跳跃表的思想。
当然需要额外开辟空间来维护上面的链表,典型的空间换时间策略。
再数据量足够大的情况下我们还可以添加索引,直到同一层节点只有两个元素(只有一个没有比较的意义),这种多层链表结构就是跳跃表。
跳跃表新增节点:
- 新节点和各层索引节点逐一比较,确定原链表的插入位置。O(logn)
- 把索引插入到原链表。O(1)
- 利用抛硬币的随机方式,决定新节点是否提升为上一级索引。结果为“正”则提升并继续抛硬币,结果为“负”则停止。O(logn)
总体跳跃表时间复杂度为O(logn),空间复杂度为O(n)。
条约表删除节点:
- 自上而下,查找第一次出现节点的索引,并逐层找到每一层对应的节点。O(logn)
- 删除每一层查找到的节点,如果该层只剩下1个节点,删除整个一层(原链表除外)。O(logn)
总体跳跃表删除操作的时间复杂度是O(logn)。
Redis跳跃表
Redis有序集合(zset)底层是由 ziplist 和 Redis 跳跃表两种方式实现的。
满足一下条件使用 ziplist:
- 有序集合保存的元素数量小于128个
- 有序集合保存的所有元素的长度小于64字节
接下来我们讨论Redis的跳跃表是如何实现的。
Redis跳跃表的实现
Redis 跳跃表由 redis.h/zskiplistNode 和 redis.h/zskiplist 两个结构定义。
其中 zskiplistNode 结构用于表示跳跃表节点, 而 zskiplist 结构则用于保存跳跃表节点的相关信息。
可参考如下图:

跳跃表节点
跳跃表节点的实现由 redis.h/zskiplistNode 结构定义:
typedef struct zskiplistNode { // 后退指针 struct zskiplistNode *backward; // 分值 double score; // 成员对象 robj *obj; // 层 struct zskiplistLevel { // 前进指针 struct zskiplistNode *forward; // 跨度 unsigned int span; } level[]; } zskiplistNode;
- 层
跳跃表节点的 level 数组可以包含多个元素, 每个元素都包含一个指向其他节点的指针, 程序可以通过这些层来加快访问其他节点的速度。
- 前进指针
每个层都有一个指向表尾方向的前进指针(level[i].forward 属性), 用于从表头向表尾方向访问节点。
- 跨度
层的跨度(level[i].span 属性)用于记录两个节点之间的距离, 两个节点之间的跨度越大, 它们相距得就越远。
指向 NULL 的所有前进指针的跨度都为 0 , 因为它们没有连向任何节点。
- 后退指针
节点的后退指针(backward 属性)用于从表尾向表头方向访问节点: 跟可以一次跳过多个节点的前进指针不同, 因为每个节点只有一个后退指针, 所以每次只能后退至前一个节点。
- 分值
节点的分值(score 属性)是一个 double 类型的浮点数, 跳跃表中的所有节点都按分值从小到大来排序。
- 成员
节点的成员对象(obj 属性)是一个指针, 它指向一个字符串对象, 而字符串对象则保存着一个 SDS 值。
在同一个跳跃表中, 各个节点保存的成员对象必须是唯一的, 但是多个节点保存的分值却可以是相同的。
分值相同的节点将按照成员对象在字典序中的大小来进行排序, 成员对象较小的节点会排在前面(靠近表头的方向), 而成员对象较大的节点则会排在后面(靠近表尾的方向)。
跳跃表
zskiplist 结构的定义如下:
typedef struct zskiplist { // 表头节点和表尾节点 struct zskiplistNode *header, *tail; // 表中节点的数量 unsigned long length; // 表中层数最大的节点的层数 int level; } zskiplist;
header和tail指针分别指向跳跃表的表头和表尾节点, 通过这两个指针, 程序定位表头节点和表尾节点的复杂度为 O(1) 。- 通过使用
length属性来记录节点的数量, 程序可以在 O(1) 复杂度内返回跳跃表的长度。 level属性则用于在 O(1) 复杂度内获取跳跃表中层高最大的那个节点的层数量, 注意表头节点的层高并不计算在内。
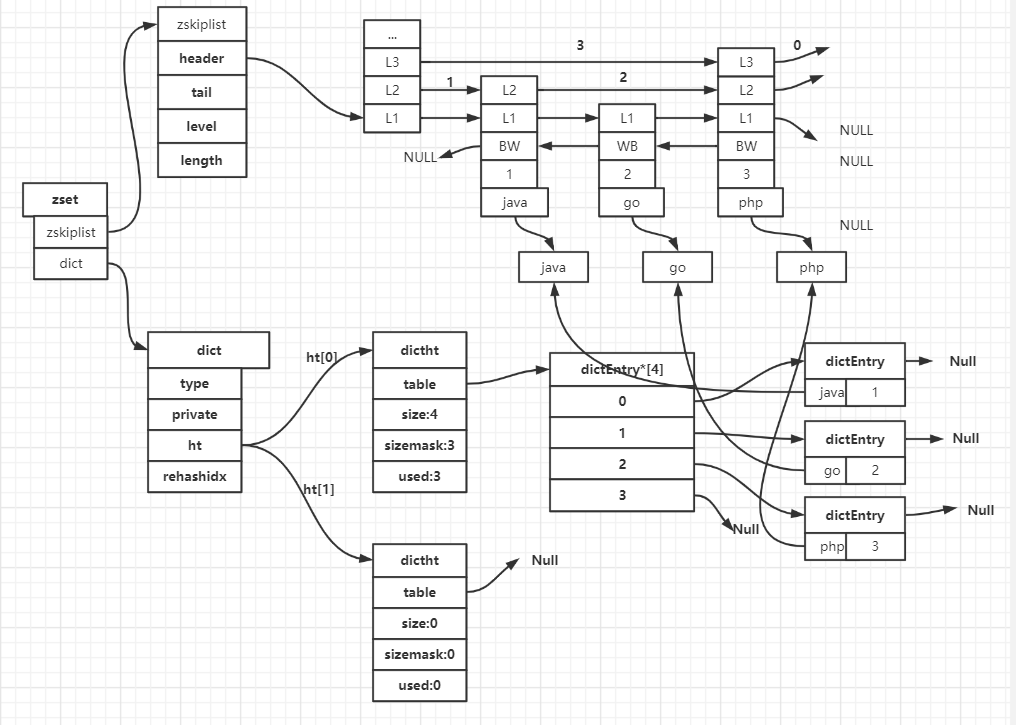
ZSet在内存中的结构
zset 的结构定义如下:
/* * 有序集合 */ typedef struct zset { // 字典,键为成员,值为分值 // 用于支持 O(1) 复杂度的按成员取分值操作 dict *dict; // 跳跃表,按分值排序成员 // 用于支持平均复杂度为 O(log N) 的按分值定位成员操作 // 以及范围操作 zskiplist *zsl; } zset;
有了上面的内容,我们可以看看zset是怎么利用跳跃表进行存储数据的。
例如,我们设置 这样的一个zset:
key = language,value=(1-java,2-go,3-php)
那么上述zset,对应下图:
参口文献
https://zhuanlan.zhihu.com/p/53975333
Redis 设计与实现第二版

 浙公网安备 33010602011771号
浙公网安备 33010602011771号